
Reinforcement learning challenges in the real-world
Reinforcement learning (RL) has moved from toy domains to real-world applications such as navigation [4], software engineering [2], industrial design [11], and finance [10]. Each of these applications has inherent difficulties which are long-standing fundamental challenges in RL, such as: limited training time, partial observability, large action or state spaces, costly exploration and safety considerations, among others. Similar problems occur when using RL in trading markets, however, we focus on three main aspects that we consider are highly relevant for financial applications: risk-awareness, variance reduction, and robustness.
Risk-awareness
Risk is such a common term that can have many definitions in different scenario. Our first question then is, what is risk? In the context of trading, risk is the potential that your chosen investments may fail to deliver your anticipated outcome. That could mean getting lower returns than expected, or losing your original investment – and in certain forms of trading, it can even mean a loss that exceeds your deposit.
Our second question is, how to measure risk? Risk assessment is a cornerstone in financial applications, a well-known approach is to consider risk while assessing the performance (profit) of a trading strategy. Here, risk is a quantity related to the variance (or standard deviation) of the profit and it is commonly refereed to as “volatility”. In particular, the Sharpe ratio [15], a commonly used measure in trading markets, considers both the generated profit and the risk (variance) associated with a trading strategy. Sharpe ratio is commonly defined to be the asset return divided by the standard deviation of the asset return.
Traditional RL aims to optimize the expected return, usually, without considerations of risk. However, risk-averse RL is a recent area that has proposed to optimize an objective function with risk consideration.
Risk-averse Q-learning (RAQL): Shen et al. [16] proposed a Q-learning algorithm that is shown to converge to the optimal of a risk-sensitive objective function:\begin{align}
\label{eq:Risk_Averse_Objective}
\tilde{J}_{\pi}= \frac{1}{\beta}\mathbb{E}_{\pi}\left[exp\left(\beta\sum_{t=0}^{\infty}\gamma^t r_t\right)\right]=\mathbb{E}\left[\sum_{t=0}^{\infty}\gamma^t r_t\right] + \frac{\beta}{2}\mathbb{V} ar\left[\sum_{t=0}^{\infty}\gamma^t r_t\right] + O(\beta^2).
\end{align}
The training scheme is the same as Q-learning, except that in each iteration, a utility function is applied to the TD-error. A utility function is a monotonically increasing function. A concave utility function is applied when we want to optimize a risk-averse objective function, in contrast, a convex utility function is applied when we want to optimize a risk-seeking objective function. To summarize, applying a utility function to Q-learning is a concise way to consider risk in RL.
Variance reduction
In trading markets, we do not only care about the expected return, but also how ‘safe’ a strategy is. In RL, one common approach to measure ‘safety’ is by measuring the variance of the return [7]. Here we we mention two recent works.
Averaged-DQN [1]: This approach reduces training variance by training multiple Q tables in parallel and averaging previously learned Q-value estimates, which leads to a more stable training procedure and improved performance by reducing approximation error variance in the target values. Averaged DQN is theoretically shown to reducing the training variance, but there is no convergence guarantee.
Variance reduced Q-learning (V-QL): Wainwrigth [18] proposed a variance reduction Q-learning algorithm which can be seen as a variant of the SVRG algorithm in stochastic optimization [9]. Given an algorithm that converges to $Q^*$, one of its iterates $\bar{Q}$ could be used as a proxy for $Q^*$, and then recenter the ordinary Q-learning updates by a quantity $-\hat{\mathcal{T}}_k(\bar{Q}) + \mathcal{T}(\bar{Q})$, where $\hat{\mathcal{T}}_k$ is an empirical Bellman operator, $\mathcal{T}$ is the population Bellman operator, which is not computable, but an unbiased approximation of it could be used instead. This algorithm is shown to be convergent to the optimal of expected return and enjoys minimax optimality up to a logarithmic factor.
Novel proposed algorithm: RA2-Q [6]: Since RAQL has the advantage that it converges to the optimal of a risk-averse objective function, we could use it as a building block and design novel risk-averse RL algorithms based on it. The idea of training multiple Q tables in parallel could be integrated with the utility function technique, more specifically, we train $k$ Q tables in parallel using the update rules in RAQL, and select more stable actions by estimating the variance by the sample variance of those $k$ Q tables, then compute a risk-averse $\hat{Q}$ table and select actions according to it. We name this algorithm RA2-Q, which preserves the convergence property of RAQL.
Novel proposed algorithm: RA2.1-Q [6]: We can also combine the ‘recenter’ technique of V-QL with the utility function technique in a novel algorithm RA2.1-Q. For each empirical Bellman operator $\hat{\mathcal{T}}_k$, we apply a risk-averse utility function to the TD error. Although we cannot show any convergence guarantee of RA2.1-Q, empirically, RA2.1-Q obtained better results than RA2-Q and RAQL in a multi-agent evaluation.
Robustness
What is robustness? We usually say an algorithm is robust if it is stable under different challenging scenarios. Recent works, have improved robustness of algorithms with adversarial learning by assuming two opposing learning processes: one that aims to disturb the most and another one that tries to control the perturbations [12].
Risk-Averse Robust Adversarial Reinforcement Learning (RARL): The same concept has been adapted with neural networks in the context of deep RL [14] and in particular RARL [13] extended this idea by combining with Averaged DQN. RARL trains two agents — protagonist and adversary in parallel, and the goal for those two agents are respectively to maximize/minimize the expected return as well as minimize/maximize the variance of expected return. RARL showed good experimental results, enhancing stability and robustness, without providing theoretical guarantees.
Novel proposed algorithm: RA3-Q [6]: The idea of having a protagonist and adversary in the same environment lends itself to multi-agent learning algorithms. In this context, Nash Q-learning [8] is a well-known multi-agent algorithm that can obtain the optimal strategy when there exists a unique Nash equilibrium in general-sum stochastic games. Our last proposal takes inspiriation from multi-agent learning algorithms and adversarial RL. In order to achieve a robust risk-averse agent, we combine the idea of adversarial learning with RA2-Q. We assume two opposing learning process: one protagonist aims to maximize the expected reward and minimize the variance, while one adversary aims to disturb the protagonist by minimizing the expected reward and maximize the variance. We name this adversarial learning algorithm RA3-Q and although RA3-Q does not have a convergence guarantee, empirically, RA3-Q shows better results in terms of robustness compared to RA2-Q.
Evaluation
How do we measure the superiority of RL agents in trading markets? We use game theory and treat each agent as a player in a stochastic game. In empirical game theory, a meta game payoff table could be seen as a combination of two matrices $(N|R)$, where each row $N_i$ contains a discrete distribution of $p$ players over $k$ strategies, and each row yields a discrete profile $(n_{\pi_1}, …, n_{\pi_k})$ indicating exactly how many players play each strategy with $\sum_{j}n_{\pi_j} = p$. A strategy profile $\mathbf{u} = \left(\frac{n_{\pi_1}}{p}, …, \frac{n_{\pi_k}}{p}\right)$. And each row $R_i$ captures the rewards corresponding to the rows in $N$. Once we have a meta-game payoff table, to view the dominance of different strategies, one can plot a directional field of the payoff tables where arrows in the strategy space indicates the direction of flow of the population composition over the strategies [17].
In our first experiment with the open-sourced ABIDES [5] market simulator our setting consisted of one non-learning agent that replays the market deterministically [3]and learning agents. The learning agents considered are: RAQL, RA2-Q, RA2.1-Q. The measure we use is Sharpe Ratio, which is a commonly used risk-averse measure in financial markets. The results are shown in the Figure below.
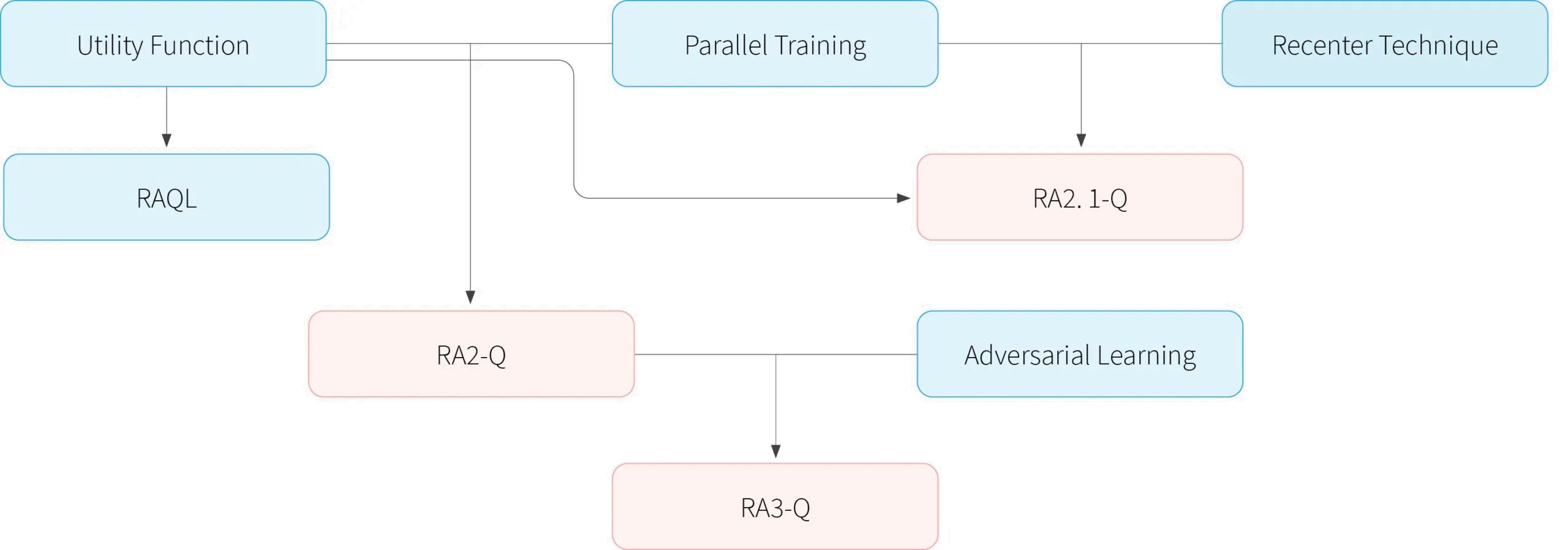
Figure 1. (a) The plot is colored according to the speed at which the strategy mix is changing at each point and (b) the lines show trajectories for some points over the simplex. Empirically, our two proposed algorithms RA2-Q and RA2.1-Q obtained better results than RAQL, and RA2.1-Q is the dominating strategy. Recall that unlike RA2-Q and RAQL, RA2.1-Q has no convergence guarantee, but it shows empirical advantage. Hence RA2.1-Q enhances risk-aversion at the expense of loosing theoretical guarantees.
Our second experiment tested robustness and we trained RA2-Q and RA3-Q agents under the same conditions as a first step. Then in testing phase we added two types of perturbations, one adversarial agent (trained within RA3-Q) or adding noise (aka. zero-intelligence) agents in the environment. In both cases, the agents will act in a perturbed environment. The results presented in Table 1 shown that RA3-Q obtained better results than RA2-Q, highlighting its robustness.
| Algorithm/Setting | Adversarial Perturbation | ZI Agents Perturbation |
| RA2-Q RA3-Q | 0.5269 0.9347 | 0.9538 1.0692 |
Conclusions
We have argued that risk-awareness, variance reduction and robustness are relevant characteristics for RL agents since those can be used as building blocks to construct algorithms. For example, by using utility functions, parallel training of Q tables, and adversarial learning, different algorithms can be constructed, as shown in Fig. 2.
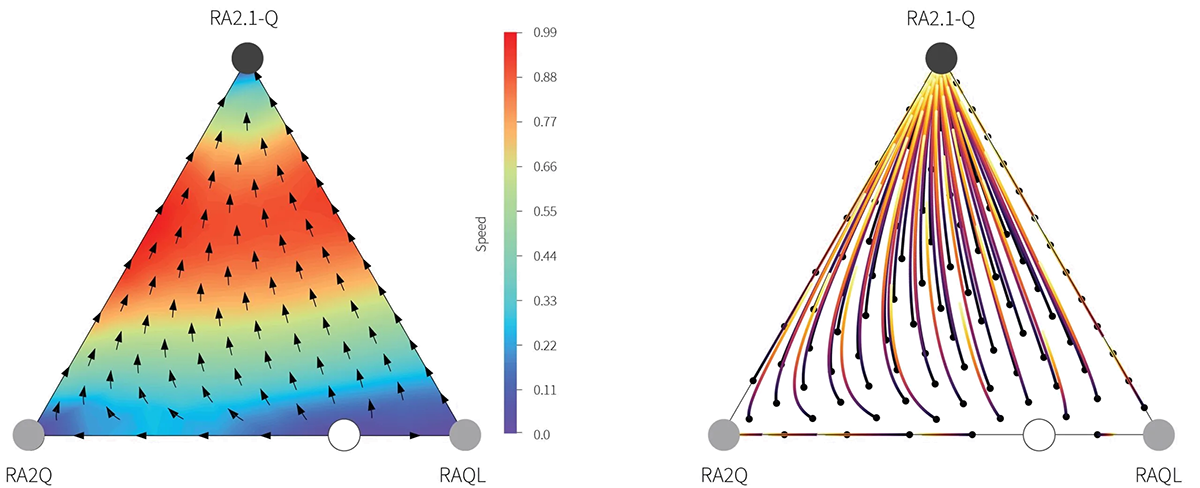
Figure 2. Building blocks of our proposed algorithms [6].
Table 2 presents a summary of properties of the algorithms mentioned in this post, those with bold typeface are our novel algorithms [6].
| Algorithm | Risk-awareness | Variance reduction | Robustness |
| RAQL | ● | ||
| Averaged DQN | ● | ||
| V-QL | ● | ||
| RARL | ● | ● | |
| RA2-Q | ● | ● | |
| RA2.1-Q | ● | ● | |
| RA3-Q | ● | ● | ● |
[1] Oron Anschel, Nir Baram, and Nahum Shimkin. Averaged-dqn: Variance reduction and sta-bilization for deep reinforcement learning. InInternational Conference on Machine Learning,pages 176–185. PMLR, 2017.[2] Mojtaba Bagherzadeh, Nafiseh Kahani, and Lionel Briand. Reinforcement learning for test caseprioritization.arXiv preprint arXiv:2011.01834, 2020.
[3] Tucker Hybinette Balch, Mahmoud Mahfouz, Joshua Lockhart, Maria Hybinette, and DavidByrd. How to evaluate trading strategies: Single agent market replay or multiple agent inter-active simulation?arXiv preprint arXiv:1906.12010, 2019.
[4] Marc G Bellemare, Salvatore Candido, Pablo Samuel Castro, Jun Gong, Marlos C Machado,Subhodeep Moitra, Sameera S Ponda, and Ziyu Wang. Autonomous navigation of stratosphericballoons using reinforcement learning.Nature, 588(7836):77–82, 2020.
[5] David Byrd, Maria Hybinette, and Tucker Hybinette Balch. Abides: Towards high-fidelitymarket simulation for ai research.arXiv preprint arXiv:1904.12066, 2019.
[6] Yue Gao, Kry Yik Chau Lui, and Pablo Hernandez-Leal. Robust Risk-Sensitive ReinforcementLearning Agents for Trading Markets. InReinforcement Learning for Real Life (RL4RealLife)Workshop at ICML, 2021.
[7] Javier Garcıa and Fernando Fern ́andez. A comprehensive survey on safe reinforcement learning.Journal of Machine Learning Research, 16(1):1437–1480, 2015.
[8] Junling Hu and Michael P. Wellman. Multiagent reinforcement learning: Theoretical frameworkand an algorithm. InProceedings of the Fifteenth International Conference on Machine Learn-ing, ICML ’98, page 242–250, San Francisco, CA, USA, 1998. Morgan Kaufmann PublishersInc.
[9] Rie Johnson and Tong Zhang. Accelerating stochastic gradient descent using predictive variancereduction. In C. J. C. Burges, L. Bottou, M. Welling, Z. Ghahramani, and K. Q. Weinberger,editors,Advances in Neural Information Processing Systems, volume 26. Curran Associates,Inc., 2013.
[10] Yuxi Li. Deep reinforcement learning: An overview.arXiv preprint arXiv:1701.07274, 2017.
[11] Azalia Mirhoseini, Anna Goldie, Mustafa Yazgan, Joe Jiang, Ebrahim Songhori, Shen Wang,Young-Joon Lee, Eric Johnson, Omkar Pathak, Sungmin Bae, et al. Chip placement with deepreinforcement learning.arXiv preprint arXiv:2004.10746, 2020.
[12] Jun Morimoto and Kenji Doya. Robust reinforcement learning.Neural computation, 17(2):335–359, 2005.5
[13] Xinlei Pan, Daniel Seita, Yang Gao, and John Canny. Risk averse robust adversarial reinforce-ment learning. In2019 International Conference on Robotics and Automation (ICRA), pages8522–8528. IEEE, 2019.
[14] Lerrel Pinto, James Davidson, Rahul Sukthankar, and Abhinav Gupta. Robust adversarialreinforcement learning. InInternational Conference on Machine Learning, pages 2817–2826.PMLR, 2017.
[15] William F Sharpe. The sharpe ratio.Journal of portfolio management, 21(1):49–58, 1994.
[16] Yun Shen, Michael J Tobia, Tobias Sommer, and Klaus Obermayer. Risk-sensitive reinforcementlearning.Neural computation, 26(7):1298–1328, 2014.
[17] Karl Tuyls, Julien Perolat, Marc Lanctot, Edward Hughes, Richard Everett, Joel Z Leibo, CsabaSzepesv ́ari, and Thore Graepel. Bounds and dynamics for empirical game theoretic analysis.Autonomous Agents and Multi-Agent Systems, 34(1):1–30, 2020.
[18] Martin J Wainwright.Variance-reducedq-learning is minimax optimal.arXiv preprintarXiv:1906.04697, 2019.