
Summary
Dimensionality reduction occurs very naturally and very frequently within many machine learning applications. While the phenomenon remains, for the most part, a conceptual mystery, one thing many researchers believe is that reducing more dimensions will often result in a greater loss of information. What’s even harder to confirm is the rate at which this information loss occurs, as well as how to formulate the problem (even for very simple data distributions and nonlinear reduction mappings.)
In this work, we try to rigorously quantify such empirical observations from an information retrieval perspective by using geometric techniques. We begin by formulating the problem through an adaptation of two fundamental information retrieval measures – precision and recall – to the (continuous) function analytic setting. This shift in perspective allows us to borrow tools from quantitative topology in order to establish the first provable information loss rate induced by dimension-reduction.
We were surprised to discover that when we began reducing dimensions, the precision would decay exponentially. This discovery should raise red flags for practitioners and experimentalists attempting to interpret their dimension reduction maps. For example, it may not be possible to design information retrieval systems that enjoy high precision and recall at the same time. This realization should keep us mindful of the limitations of even the very best dimension reduction algorithms, such as t-SNE.
While precision and recall are natural information retrieval measures, they do not directly take advantage of the distance information between data (e.g. in data visualization). We therefore propose an alternative dimension-reduction measure based on Wasserstein distances, which also provably captures the dimension reduction effect. To obtain this theoretical guarantee, we solve the following iterated-optimization problem:
by using recent results from optimal partial transport literature.
Precision and Recall for Supervised Learning, Discrete
While precision and recall for supervised learning problems are familiar concepts, let’s do a quick review of it before we adapt it to the dimensionality reduction context.
In a supervised learning setting, say the classification of cats vs dogs, first select your favorite neural net classifier fW, then collect 1,000 test images.
\[Precision = 1/2 \frac{\text{How many are cats}}{\text{Among the ones predicted as cats}} + 1/2 \frac{\text{How many are dogs}} {\text{Among the ones predicted as dogs}}
\]
\[Recall = 1/2 \frac{ \text{How many are predicted as cats}}{\text{Among the cats}} + 1/2 \frac{\text{How many are predicted as dogs}}{\text{Among the dogs}}
\]
Generally speaking, we can average precision and recall over n classes.
Precision and Recall for Unsupervised Learning, Continuous
The formulation we used for precision and recall was inspired by the supervised learning setting. Since dimensionality reduction can actually happen in an unsupervised setting, we needed to change a few things around. In a typical dimensionality reduction map $f: X \rightarrow Y$, we often care about preserving the local structure post-reduction.
Since the unsupervised setting means there are no more labels, the first thing we did was to replace “label for an input x” by “neighboring points for an input x in high dimension.” We didn’t have the predictions either, but we felt it made sense to replace “prediction for an input x” by “neighboring points for an input y = f(x) in low dimension.”
When computing precision and recall in the supervised cases, we averaged across the labels. So, the second thing we did was to average over each data point.
\[Precision = \frac{1}{n} \sum_{x \in X_n} {\text{How many are neighbors of} ~x~ \text{in high dimension} / \text{Among the low dimensional neighbors of}~ y = f(x)}\]
\[Recall = \frac{1}{n} \sum_{x \in X_n} {\text{How many are neighbors of} ~y = f(x)~ \text{in low dimension} / \text{Among the high dimensional neighbors of} ~x}\]
Precision is roughly injectivity, recall is roughly continuity
But it was still hard to prove anything, even with the settings detailed above. One difficulty we faced is that f is a map between continuous spaces, but the data points are finite samples. This motivated us to look for continuous analogues of the examples below:
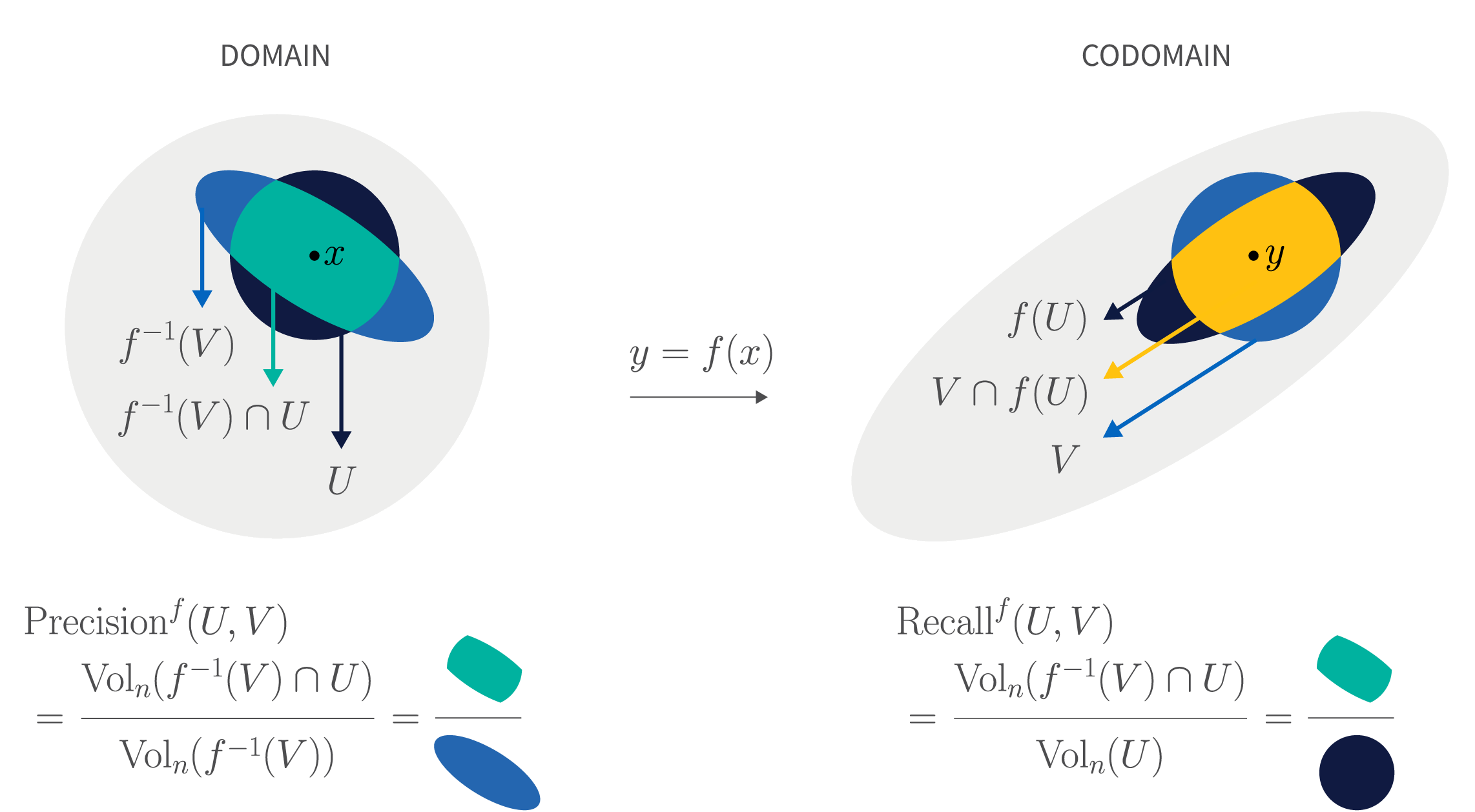
Finally, we arrived at one of the paper’s key observations: Precision is roughly injectivity; recall is roughly continuity.
What makes information loss in dimension reduction inevitable?
Let’s build some intuition with linear maps. In linear algebra, we learn that a linear map from $\mathbb{R}^n$ to $\mathbb{R}^m$ must have null space of dimension at least $n – m$. One may interpret this as the “how” and “why” of when linear maps lose information: distant points in high-dimension are projected together in low-dimension. This process leads to very poor precision.
In practice, DR maps can be much more flexible than linear maps. So, can this expressivity circumvent the linear algebraic dimensional mismatch issue? To study dimension reduction under continuous maps, we turned to the corresponding study of topological dimension: waist inequality from quantitative topology. It turns out that a continuous map from high-to-low dimension still fails to circumvent the similar issue that plagues linear maps – that many continuous maps collapse the points together. For most $x$, we have for $y = f(x): \text{Vol}_{n-m} f^{-1}(y) \ge C(x) \text{Vol}_{n-m} B^{n-m}$.
Roughly speaking, the relevant neighborhood $U$ of $x$ is typically small, in all $n$ directions, while the retrieval neighborhood $f^{-1}(V)$ is big in n-m directions. This quantitative mismatch makes it very difficult to achieve high precision for a continuous DR map. It’s this mismatch that leads to the exponential decay of precision:
\[ Precision^{f}(U, V)
\leq
D(n, m)\,\left(\frac{r_U}{R}\right)^{n-m}\,\frac{ r_U^{^{m}} }{p^{m}(r_V/L)}
\]
Measure the imperfection
The above trade-off/information loss phenomenon has been widely observed by experimentalists. Naturally, practitioners have developed various tools to measure the imperfections. What was less clear in this regard is what led to the trade-off, so having clarified this a bit more, we can now design better measurement devices.
When we naively compute sample precision and recall:
\[Precision =
\frac{\mathrm{~How~many~points~are~high~dimensional~neighbors~of}~x }{\mathrm{Among~the~low~dimensional~neighbors~of}~y}
\]
\[Recall =
\frac{\mathrm{~How~many~points~are~low~dimensional~neighbors~of}~y }{\mathrm{Among~the~high~dimensional~neighbors~of}~x}
\]
These two quantities are equal when we fix the number of neighboring points. (Here, the numerators are the same. When we fix the number of neighboring points, the denominators are equal as well). Fixing the number of neighboring points is one of the reasons behind t-SNE’s success, since some data points are quite far away from others and without fixing them some outliers wouldn’t have any neighboring points.
We can alternatively compute them by discretizing the continuous precision and recall shown above.
\[Precision =
\frac{\mathrm{How~many~points~are~within~r_U~from}~x~\mathrm{and~within~r_V~from}~y}{\mathrm{How~many~points~are~within~r_V~from}~y}
\]
\[Recall = \frac{\mathrm{How~many~points~are~within~r_U~from}~x~\mathrm{and~within~r_V~from}~y}{\mathrm{How~many~points~are~within~r_U~from}~x}
\]
But not only will this create an unequal number of neighboring points, it will result in quite a few data points ending up with very few neighbors. This is partially caused by high-dimensional geometry. Either way it can appear as though precision and recall are difficult quantities to manage in a practical situation.
Let’s revisit the problem from an alternative perspective. From the proof-of-precision’s dimension reduction rate, it’s clear that the mismatch comes from $f^{-1}(V)$ and $U$ – and this corresponds to the injectivity imperfection. Heuristically, the parallel quantity for continuity imperfection is f(U) and V.
We therefore proposed the following Wasserstein measures:
\[ W_{2}(\mathbb{P}_U, \mathbb{P}_{f^{-1}(V)});
W_{2}(\mathbb{P}_{f(U)}, \mathbb{P}_V)
\]
Like precision and recall, we associated the two Wasserstein measures for each point in the DR visualization map.
Dimension reduction imperfection measure: practical takeaway
i) On a theoretical level, our work sheds light on the inherent trade-offs in any dimensionality reduction mapping model (e.g., visualization embedding).
ii) On a practical level, the implications are for practitioners to have a measurement tool to improve their data exploration practice: To date, people have put too much trust on low-dimensional visualizations. Low-dimensional visualizations can at best poorly reflect high-dimensional data structures; at worst it can produce incorrect representations, which can then degrade any subsequent analysis built upon them. We strongly suggest that practitioners improve their practice by incorporating a reliability measure for each data point on all their data visualizations.