
One of the driving factors behind the modern deep learning explosion can be attributed to the success of training neural networks with stochastic gradient descent (SGD). We form a neural network as a composition of functions, apply an auto-differentiation library such as PyTorch or TensorFlow, then let our GPUs take care of the rest. This approach has enabled us to achieve state-of-the-art benchmarks around a wide range of machine learning tasks, such as image/speech recognition and natural language processing. All of this progress hinges upon an important principle: that applying gradient descent to an objective function always converges to a local minima.
While it is tempting to now adopt a “one-size-fits-all” mantra, this would be a prematurely limiting methodology. Recently, a whole spate of machine learning models have emerged that involve more than a single objective; rather, they involve multiple objectives which all interact with each other during training. The most prominent model, of course, is Generative Adversarial Networks (GANs). However, other examples include synthetic gradients, proximal-gradient TD learning, and intrinsic curiosity. The appropriate way to think about these types of problems is to interpret them as game-theoretic problems, where one aims to find the Nash equilibrium rather than local minima of each objective. Intuitively speaking, Nash equilibrium occurs when each player knows the strategy of all the other players, and no player has anything to gain by changing his or her own strategy.
Unfortunately, finding Nash equilibrium in games is notoriously difficult. In fact, theoretical computer scientists have long known that finding Nash equilibrium for general games is an intractable problem. Nor is it ideal to naively apply gradient descent to games. Firstly, gradient descent has no convergence guarantees and, even in case where it does, it may be highly unstable and slow. But the most severe drawback is that, unlike the traditional setup in supervised machine learning, there is no single objective involved in this model which means we have no way of measuring any kind of progress.
We can illustrate the complexity of interacting losses with a very simple two-player game example. Consider Player 1 and Player 2 with the respective loss functions:
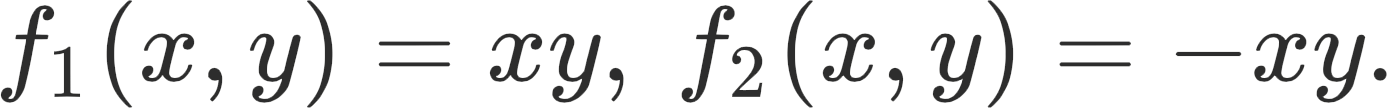
In this game, Player 1 controls the variable x and Player 2 controls the variable y. The dynamics (or simultaneous gradient) is given by:
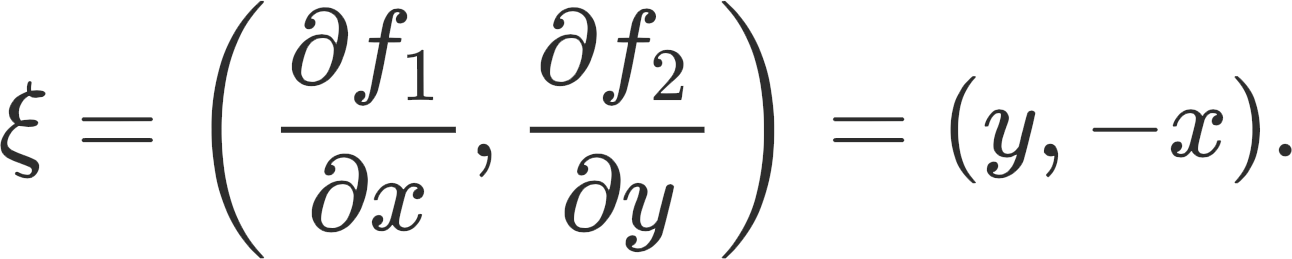
If we plot this in the 2D-Cartesian plane, all of the vector fields cycle around the origin and there is no direction which points straight to it. The technical problem here is that the dynamics ξ are not a gradient vector field; in other words, there is no function φ such that φ = ξ.
In the ICML paper, The Mechanics of n-Player Differentiable Games, [1], the authors use insights from Hamiltonian mechanics to tackle the problem of finding game equilibriums. Hamiltonian mechanics are a reformulation of classical mechanics in the following way. Consider a particle moving in the Euclidean space Rn. The state of the system at a given time t is determined by the coordinates of the position (q1,…,qn) and the coordinates of the momentum (p1,…,pn). The space R2n of positions and momenta is called the “phase space”. The “Hamiltonian” H(q,p) is a function on this phase space and it represents the total energy of the system. Hamilton’s equations (also referred to as “equations of motion”) describe the time evolution of the state of the system. These are given by
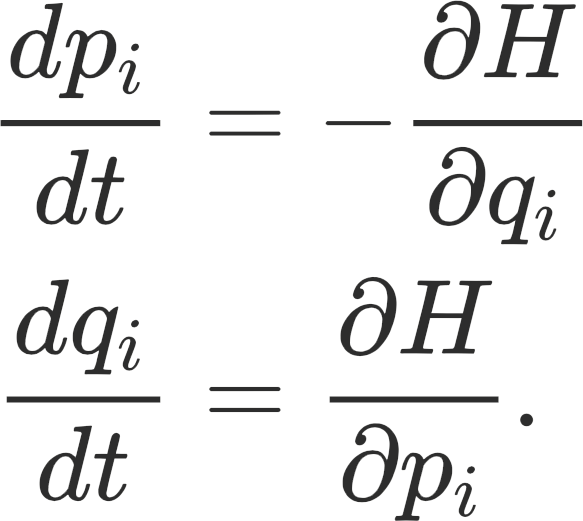
We see how all of these formulations play out in our simple example. If we define the Hamiltonian H(x,y) here to be
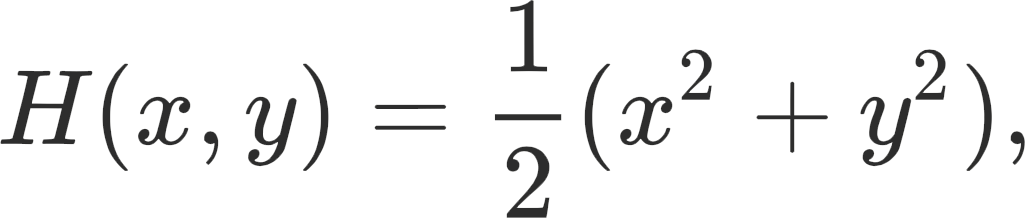
the gradient is then ▽H = (x, y). There are two critical observations to be made here: (1) conservation of energy. The level sets of H are conserved by the dynamics ξ = (y, –x) (hence, ξ cycles around the origin) and; (2) gradient descent on the Hamiltonian, rather than the simultaneous gradient on the losses, converges to the origin.
Motivated by this philosophy, the authors in [1] introduce the notion of Hamiltonian games. For a n-player game with parameter w, they define the Hessian of a game to be

Since this is a matrix, it always admits a symmetric and anti-symmetric decomposition:
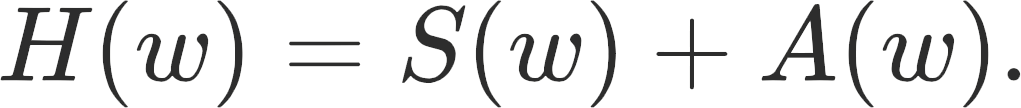
This leads to a classification: Hamiltonian games are defined as games where the symmetric component is zero, S(w) = 0. Potential games are defined as games where the anti-symmetric component is zero, A(w) = 0. Going back to our simple example, the Hessian is
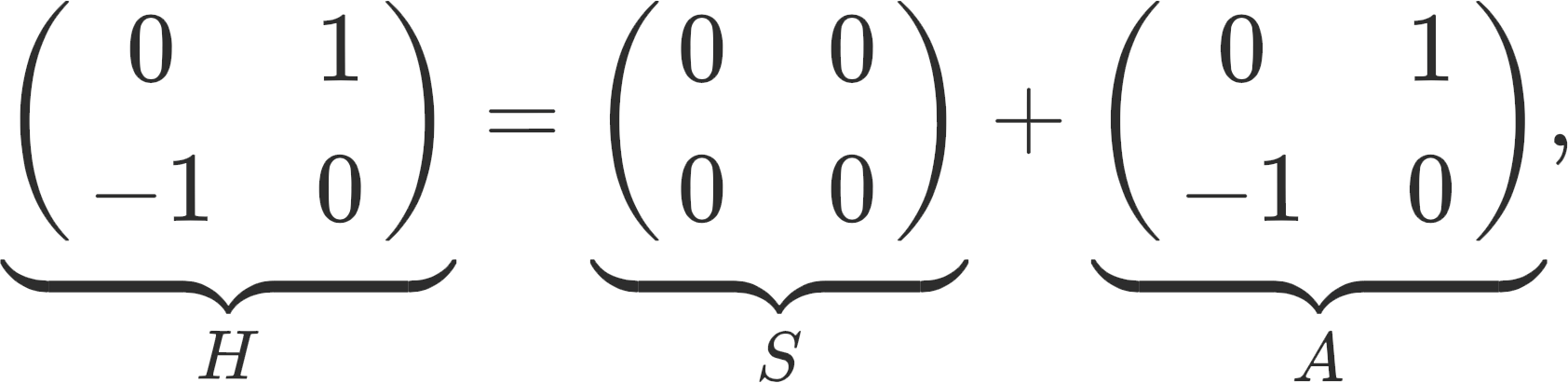
so therefore we have a Hamiltonian game. One of the main theoretical contributions of this paper is that given an n-player Hamiltonian game with H(w) = 1/2ξ(w)2, under some conditions the gradient descent on H converges to a Nash equilibrium.
Another central contribution made by the authors is the proposal of a new algorithm to find stable fixed points (which under some conditions can be considered Nash equilibrium). Their Symplectic Gradient Adjustment (SGA) adjusts the game dynamics by

For a potential game where A(w) = 0, then SGA performs the usual gradient descent by finding local minimum. In contrast, for a Hamiltonian game where S(w) = 0, then SGA finds local Nash equilibrium. Readers fluent in differential geometry can immediately see the reasoning behind the terminology “symplectic”. For a Hamiltonian game, H(w) is a Hamiltonian function and the gradient of the Hamiltonian ▽H = ATξ. The dynamic ξ is a Hamiltonian vector field, since it conserves the level-sets of the Hamiltonian H. In symplectic geometry, the relationship between symplectic form ω and the Hamiltonian vector field ξ is
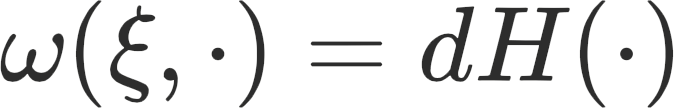
The right-hand side of this equation is simply the gradient of our Hamiltonian function. In the context of Hamiltonian games, we see that the antisymmetric matrix A is playing the role of the symplectic form ω, which justifies the terminology.
In the experimental section, the authors compared their SGA method to other recently proposed algorithms for finding stable fixed points in GANs. Moreover, to demonstrate the flexibility of their algorithm, the authors also studied the performance of SGA on general two-player and four-player games. In all cases, SGA was competitive with, if not better than, existing algorithms.
As a summary, this paper provides a glimpse of how a specific class of general game problems may be tackled by borrowing tools from mathematics and physics. Machine learning models featuring multiple interacting losses are becoming increasingly popular. As such, it is necessary for us to come up with new methodologies rather than relying on the crutches of standard gradient descent. Unraveling the mysteries behind these complicated models will have considerable practical impact as it will aid the design of better scalable algorithms in the future.
References
[1] David Balduzzi, Sebastien Racaniere, James Martens, Jakob Foerster, Karl Tuyls, and Thore Graepel. The mechanics of n-player differentiable games. arXiv preprint arXiv:1802.05642, 2018.