
Introduction
In part I of this tutorial we argued that few-shot learning can be made tractable by incorporating prior knowledge, and that this prior knowledge can be divided into three groups:
Prior knowledge about class similarity: We learn embeddings from training tasks that allow us to easily separate unseen classes with few examples.
Prior knowledge about learning: We use prior knowledge to constrain the learning algorithm to choose parameters that generalize well from few examples.
Prior knowledge of data: We exploit prior knowledge about the structure and variability of the data and this allows us to learn viable models from few examples.
We also discussed the family of methods that exploit prior knowledge of class similarity. In part II we will discuss the remaining two families that exploit prior knowledge about learning, and prior knowledge about the data respectively.
Prior knowledge about learning
Perhaps the most obvious approach to few-shot learning would be transfer learning; we first find a similar task for which there is plentiful data and train a network for this. Then we adapt this network for the few-shot task. We might either (i) fine-tune this network using the few-shot data, or (ii) use the hidden layers as input for a new classifier trained with the few-shot data. Unfortunately, when training data is really sparse, the resulting classifier typically fails to generalize well.
In this section we’ll discuss three related methods that are superior for the few-shot scenario. In the first approach (“learning to initialize”), we explicitly learn networks with parameters that can be fine-tuned with a few examples and still generalize well. In the second approach (“learning to optimize”), the optimization scheme becomes the focus of learning. We constrain the optimization algorithm to produce only models that generalize well from small datasets. Finally, the third approach (“sequence methods”) learns models that treat the data/label pairs as a temporal sequence and that learns an algorithm that takes this sequence and predicts missing labels from new data.
Learning to initialize
Algorithms in this class aim to choose a set of parameters that can be fine-tuned very easily to another task via one or more gradient learning steps. This criterion encourages the network to learn a stable feature set that is applicable to many different domains, with a set of parameters on top of these that can be easily modified to exploit this representation.
Model agnostic meta-learning
Model agnostic meta-learning or MAML (Finn et al. 2017) is a meta-learning framework that can be applied to any model that is trained with a gradient descent procedure. The aim is to learn a general model that can easily be fine-tuned for many different tasks, even when the training data is scarce.
The parameters $\boldsymbol\phi$ of this general model can be adapted to the $j^{th}$ task $\mathcal{T}_{j}$ by taking a single gradient step
\begin{equation}\label{eq:MAML_obj1}\boldsymbol\phi_{j} = \boldsymbol\phi – \alpha \frac{\partial}{\partial \boldsymbol\phi} \mathcal{L}\left[\mathbf{f}[\boldsymbol\phi],\mathcal{T}_{j}]\right], \tag{1}\end{equation}
to create a task-specific set of parameters $\boldsymbol\phi_{j}$. Here, the network is denoted by $\mathbf{f}[\bullet]$ with parameters $\boldsymbol\phi$. The loss $\mathcal{L}[\bullet, \bullet]$ takes the model $\mathbf{f}[\bullet]$ and the task data $\mathcal{T}_{j}$ as parameters. The parameter $\alpha$ represents the size of the gradient step.1
Our goal is that on average for a number of different tasks, the loss will be small with these parameters. The meta-cost function $\mathcal{M}[\bullet]$ encompasses this idea
\begin{equation}\mathcal{M}[\boldsymbol\phi] = \sum_{j=1}^{J} \mathcal{L}\left[\mathbf{f}[\boldsymbol\phi_{j}],\mathcal{T}_{j}]\right], \tag{2}\end{equation}
where each set of parameters $\boldsymbol\phi_{j}$ is itself a function of $\boldsymbol\phi$ as given by equation 1. We wish to minimize this cost, which we can do by taking gradient descent steps
\begin{equation}\label{eq:MAML_obj2} \boldsymbol\phi \leftarrow \boldsymbol\phi – \beta \frac{\partial}{\partial \boldsymbol\phi} \mathcal{M}[\boldsymbol\phi], \tag{3}\end{equation}
where $\beta$ is the step size. This would typically be done in a stochastic fashion, updating the meta-cost function with respect to a few tasks at a time (figure 1a-b) In this way, MAML gradually learns parameters $\boldsymbol\phi$ which can be adapted to many tasks by fine tuning.
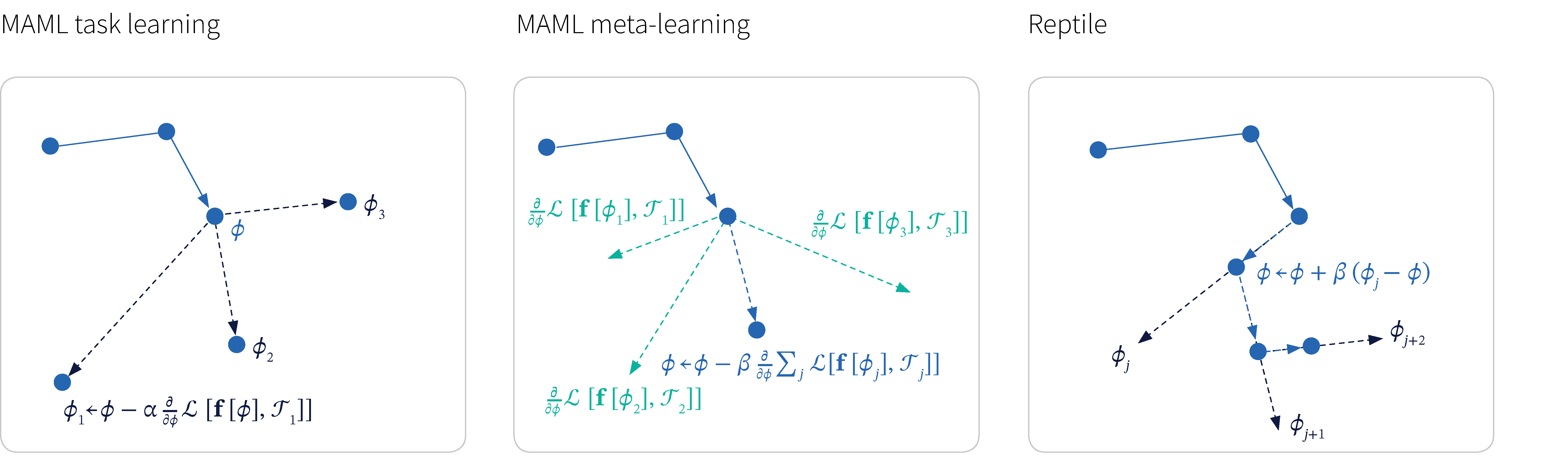
Figure 1. Parameter initialization for meta-learning. a) MAML task learning. The global model parameters $\boldsymbol\phi$ are used to initialize a single step optimization for each task $\mathcal{T}_{j}$ to create new parameters $\boldsymbol\phi_{j}$. b) MAML meta learning. The global model parameters $\boldsymbol\phi$ are updated so that at the next iteration, performance after these single-step updates will be better. c) Reptile task learning (black arrows) and meta learning (blue arrows). The global model parameters are used to initialize a single step optimization for each task. The global parameters are updated to move towards each single step solution.
First order MAML
MAML has the disadvantage that both the meta-learning objective (equation 3) and the task learning objective within it (equation 1) contain gradients, and so we have to take gradients of gradients (via a Hessian matrix) to perform each update.
To improve the efficiency of learning Finn et al. (2017) introduced first order model agnostic meta learning or FOMAML which simply omitted the second derivatives. Surprisingly, this did not impact performance. They speculate that this might be because that RELU networks are almost linear and so the second derivatives are close to zero.
Reptile
Nichol et al. (2018) introduced a simpler variant of first order MAML which they called Reptile. As for MAML, the algorithm repeatedly samples tasks $\mathcal{T}_{j}$, and optimizes the global parameters $\boldsymbol\phi$ to create task specific parameters $\boldsymbol\phi_{j}$. Then it updates the global parameters using the rule:
\begin{equation}\boldsymbol\phi \longleftarrow \boldsymbol\phi + \alpha (\boldsymbol\phi_{j}-\boldsymbol\phi). \tag{4}\end{equation}
This is illustrated in figure 1c. One interpretation of this is that we are performing stochastic gradient descent on a task level rather than a data level.
Jayathilaka (2019) improved this method by adding two thresholds $\beta$ and $\gamma$ as hyper-parameters. After $\beta$ steps, the gradient is pruned so that if the change in parameters $(\boldsymbol\phi_{j}-\boldsymbol\phi) < \gamma$ then no change is made. The logic of this approach is that the end of the meta-training procedure is over-learning the training tasks and hence this part of the regime is damped.
Learning to optimize
In the previous section we discussed algorithms that learn good starting positions for optimization. In this section we consider methods that learn the optimization algorithm itself. The idea is that these new optimization schemes will be constrained to produce models that generalize well when trained with few examples.
We will discuss two approaches. In the first we consider the learning rule as the cell-state update in a long short-term memory (LSTM) network; the LSTM is a model used to analyse sequences of data, and here these are sequences of optimization steps. In the second approach we frame the optimization updates in terms of reinforcement learning.
Optimization as LSTM cell update
Ravi & Larochelle (2016) propose training a LSTM based meta-learner, where the cell state represents the model parameters. This was inspired by their realization that the standard gradient descent update rule has a very similar form to the cell update in an LSTM. We’ll review each in turn to make this connection explicit.
The gradient descent update rule for a model with parameters $\boldsymbol\phi$ is given by:
\begin{equation}\label{eq:ravi_gradient} \boldsymbol\phi_{t} = \boldsymbol\phi_{t-1}-\alpha\cdot\mathbf{g}_{t-1}, \tag{5}\end{equation}
where $t$ represents the time step, $\alpha$ is the learning rate and $\mathbf{g}_{t}$ is the gradient vector. The cell state update rule in an LSTM is given by:
\begin{equation}\label{eq:ravi_optimize} \mathbf{c}_{t} = \mathbf{f}_{t} \odot \mathbf{c}_{t-1} + \mathbf{i}_{t}\odot \tilde{\mathbf{c}}_{t-1}, \tag{6}\end{equation}
where the cell state $\mathbf{c}_{t}$ at time $t$ is updated based on i) previous cell state $\mathbf{c}_{t-1}$ moderated by the forget gate $\mathbf{f}_{t}$ and ii) the candidate value for the cell state $\tilde{\mathbf{c}}_{t-1}$ moderated by the input gate $\mathbf{i}_{t}$.
The mapping from equation 5 to 6 is now clear. The cell state of the LSTM takes the place of the parameters $\boldsymbol\phi$ and the candidate value for the cell state $\tilde{\mathbf{c}}_{t-1}$ takes the place of the gradient $\mathbf{g}_{t-1}$. For the gradient descent case, the forget gate $\mathbf{f}_{t} = \mathbf{1}$, and the input gate $\mathbf{i}_{t} = -\alpha\mathbf{1}$.
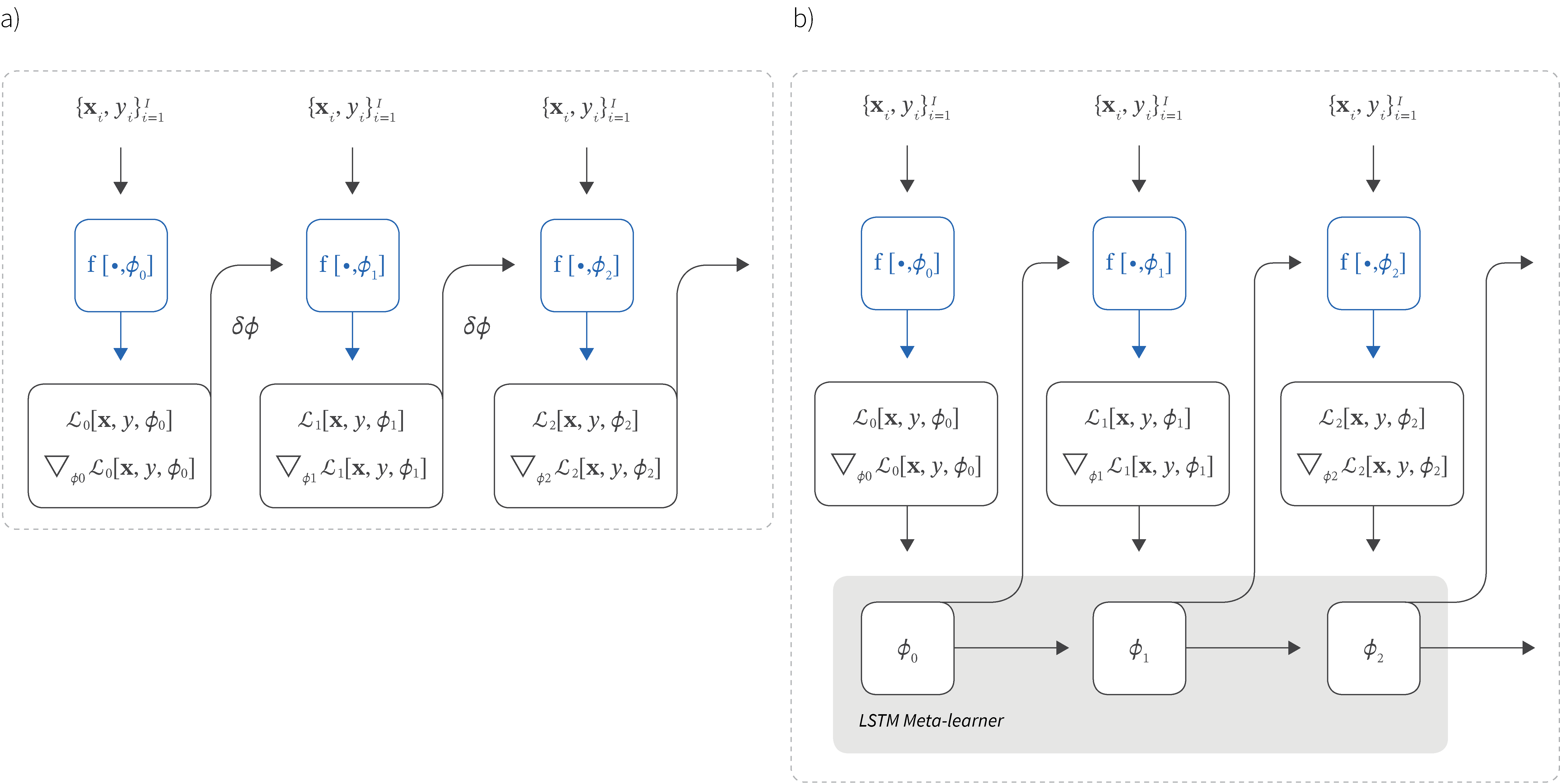
Figure 2. Learning to optimize. a) Standard learning setup. Data $\{\mathbf{x}_{i},y_{i}\}_{i=1}^{I}$ is passed through the neural network model $\mbox{f}[\bullet,\boldsymbol\phi_{0}]$ with initial parameters $\boldsymbol\phi_{0}$. The loss is calculated and the gradient of the loss $\mathcal{L}$ with respect to the parameters and these are used to update these parameters for the next iteration. b) Learning to optimize setup of Ravi & Larochelle (2016). The loss and its gradient are now passed to an LSTM containing the parameters as the cell state. The LSTM has learned the best rule to update these parameters for an unseen test task, from experience with a series of training tasks.
Hence, Ravi & Larochelle (2016) propose representing the parameters of the models by the cell state of an LSTM and learning more general functions for the forget and input gates (figure 3). Each of these are two-layer neural networks that take a vector containing the previous gradient, previous loss function, previous parameters and previous value of the gate.
At each step of the training, the LSTM sees a sequence that corresponds to iterative optimization of the parameters $\boldsymbol\phi$ for the $j^{th}$ task. The LSTM learns the update rule from these sequences by updating the parameters in the forget and input gates; the parameters of these networks are manipulated to select an update rule that tends to produce good generalization.
In practice, each parameter is updated separately, so that there is a different input and forget gate for each. Similarly to ADAM, each parameter has a different learning rate, but now this learning rate is a complex function of the history of the optimization.
For the test task, the LSTM is run to provide gradient updates that incorporate prior knowledge from all of the training tasks and converge fast to a meaningful set of parameters without over-learning. Andrychowicz et al. (2016) present a similar scheme although this is not explicitly aimed at the few-shot learning situation.
Optimization updates from reinforcement learning
Li & Malik (2016) observed that an optimization algorithm can be viewed as a Markov decision process. The state consists of the set of relevant quantities for optimization (current parameters, objective values, gradients, etc.). The action is the parameter update $\delta\boldsymbol\phi$ and so the policy is a probabilistic parameter update formula (figure 3).
Inspired by this observation, Li & Malik (2016) described the mean of the policy is a recurrent neural net that takes features relevant to the optimization (iterates, gradient and objective values from recent iterations) and the previous memory state and outputs the action (parameter update).

Figure 3. Optimization as reinforcement learning. The state of the system is the current parameter vectors $\boldsymbol\phi$. The system chooses an action (parameter update) from a policy (distribution over possible parameter updates) and receives a reward in the form of a change in the loss function.
As with the LSTM system above, this system learns how best to update the model parameters in unseen test tasks, based on experience gained from a diverse collection of training tasks.
Optimization rules from reinforcement learning
Bello et al. (2017) developed a reinforcement learning system where the action consists of an optimization update rule in a domain specific language. Each rule consists of two operands, two unary functions to apply to the first and second operand respectively, and a binary function to combine their outputs:
\begin{equation} \boldsymbol\phi \leftarrow \boldsymbol\phi + \alpha \cdot \mbox{b}\left[\mbox{u}_{1}[o_{1}], \mbox{u}_{2}[o_{2}]\right], \tag{7}\end{equation}
where $\mbox{u}_{1}[\bullet]$ and $\mbox{u}_{2}[\bullet]$ are the unary functions, $o_{1}$ and $o_{2}$ are the operands and $\mbox{b}[\bullet]$ is the binary function. The term $\alpha$ represents the learning rate.
Examples of operands include the gradient, sign of gradient, random noise, and moving average of gradient. Unary functions include clipping, square rooting, exponentiating and identity. Binary functions include addition, subtraction, multiplication, and division. Many existing optimization schemes can be expressed in this language, including stochastic gradient descent, RMSProp and Adam.
The controller consists of a recurrent neural network which samples strings of length $5$, each of which represents a different rule. A child classification network is trained with this rule and the accuracy is fed back to change the parameters of the RNN so that it is more likely to output better rules.
Perhaps surprisingly, the system finds interpretable optimization rules; for example, the powersign classifier compares the sign of the gradient and its running average and adjusts the step size according to whether those values agree.
Sequence methods
In the previous two sections, we considered methods that find good initial parameters for fine tuning networks and methods that learn optimization rules that tend to produce good generalization. Both of these methods are obviously directly connected to the optimization process.
In this section, we introduce sequence methods for meta-learning. Sequence methods ingest the entire support set as a sequence of tuples $\{\mathbf{x}, y\}$ each containing a data example $\mathbf{x}$ and a label $y$. The last tuple consists of just a data example from the query set and the system is trained to predict the missing label. The parameters of the sequence model are updated so this prediction is consistently accurate over different tasks.
At first sight, this might seem unrelated to the previous methods, but consider the situation when we have already passed the support set into the system. From this perspective the situation is very similar to a standard network. The query example will be passed in, and the query label returned. Working backwards, we can think of passing each support set sequence as optimizing the network for this task, and the training of the sequence model itself (across many different tasks) as meta-learning of how to optimize the model for different tasks.
We’ll consider two sequence methods. The first is based on a recurrent neural network (RNN) and the second uses an attention mechanism.
Memory augmented neural networks
Santoro et al. (2016) introduced memory augmented neural networks. Their system is trained one task at a time, with each task considered as a sequence of data $\mathbf{x}$ and label $y$ pairs (figure 4). However, the label $y_{t}$ for the data example $\mathbf{x}_{t}$ at time $t$ is not provided until time $t+1$. Hence, the system must learn to classify the current example based on past information. The data is shuffled every time that a task is presented so that the network doesn’t erroneously learn the sequence rather than the relation between the data and the label.
The network consists of a controller which stores memories in a network and retrieves them to use for classification. In practice, the controller that is used to place the memories and retrieve them is an LSTM or a feed-forward network. Memories are retrieved based on a key computed from the data which is compared to every memory by cosine similarity; the retrieved memory is a weighted sum of all of the stored memories weighted by the soft-max transformed cosine similarities.
As the sequence for a new task is passed in, the system stores memories from the support set sequence and uses these to predict the subsequent labels. Over time, the memory content becomes more suited to the current task and classification improves. During meta-training, we learn the parameters of the controller so that this process works well on average over many tasks; it learns the algorithm for storing and retrieving memories.
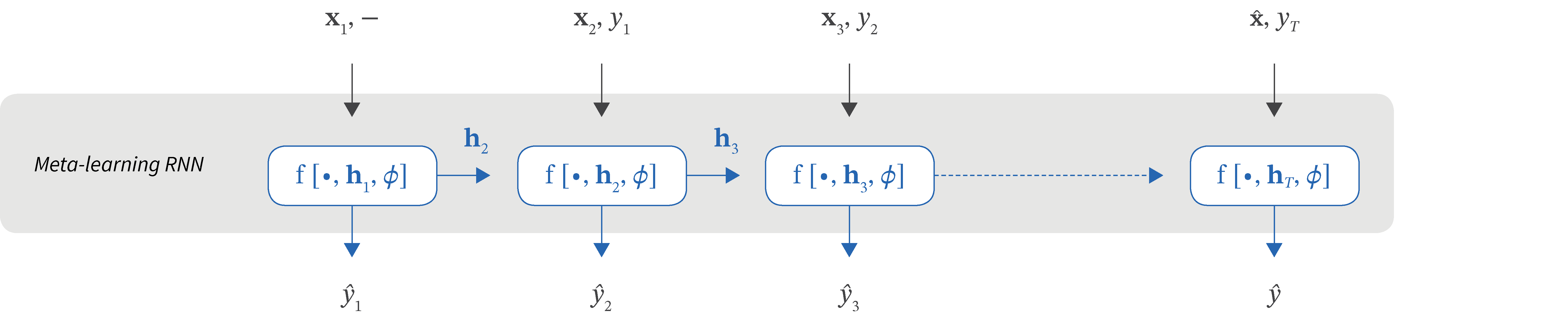
Figure 4. Sequence-based meta-learning (Santoro et al. 2016). The system is an LSTM that ingests an entire task at a time in the form of a sequence and updates its parameters based on that task. At each time step within this sequence, the network is given the current data example and attempts to predict its label. However, it is given the label from the previous time step as supervision. The LSTM must learn to remember the input patterns and their relation to the labels so that it can classify unseen examples. The data must be shuffled between each episode so that the network doesn’t erroneously learn the incorrect relation between the current data and previous label that it is given at each time step.
SNAIL
Mishra et al. (2017) also described a sequence method, in which the system is trained to take a set of (data, label) tuples $\{\mathbf{x}, y\}$ and then predict the missing label for the last example. Their system is not recurrent, and takes the entire sequence of support data at once. The architecture is based on alternating causal temporal convolutions and soft-attention layers (figure 5). This allows the decision for the query example to depend on the previously observed pairs. They term this architecture the simple neural attentive meta-learner or SNAIL.
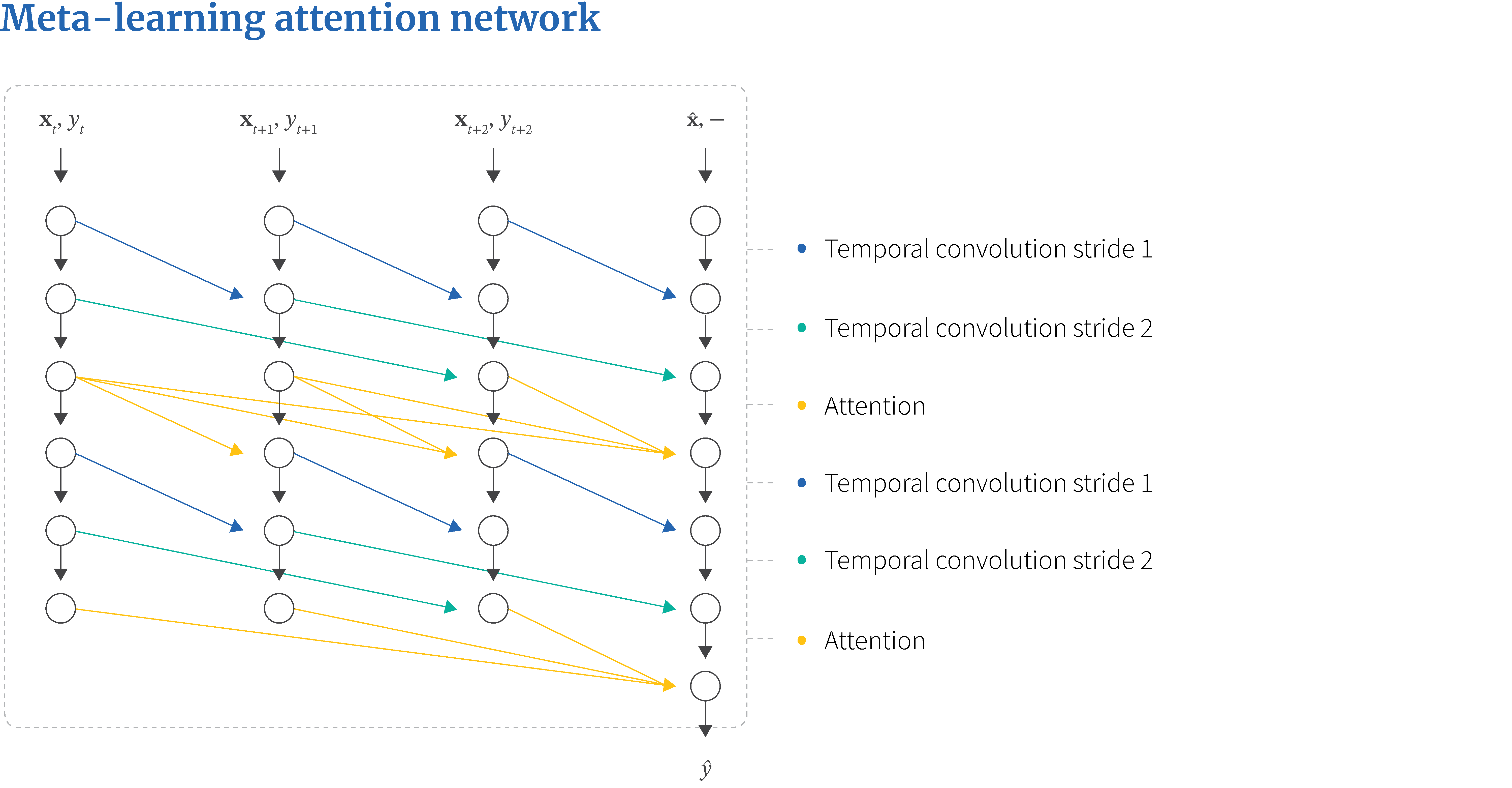
Figure 2. Learning to optimize. a) Standard learning setup. Data $\{\mathbf{x}_{i},y_{i}\}_{i=1}^{I}$ is passed through the neural network model $\mbox{f}[\bullet,\boldsymbol\phi_{0}]$ with initial parameters $\boldsymbol\phi_{0}$. The loss is calculated and the gradient of the loss $\mathcal{L}$ with respect to the parameters and these are used to update these parameters for the next iteration. b) Learning to optimize setup of Ravi & Larochelle (2016). The loss and its gradient are now passed to an LSTM containing the parameters as the cell state. The LSTM has learned the best rule to update these parameters for an unseen test task, from experience with a series of training tasks.
Prior knowledge of data
The final family of few-shot learning methods exploit prior knowledge about the process that generates the classes and their examples. There are two main approaches here. First, we can try to characterize a generative model of all possible classes with a small number of parameters. These parameters can then be learned from a just a few examples and be used as the basis for discriminating new classes. Second, we can exploit knowledge of the data creation process to synthesize new examples and hence augment the dataset. We can then use this expanded dataset to train a conventional model. We consider each approach in turn.
Generative models for object classes
We will describe two generative models. First we consider a model that is specialized to recognizing new classes of hand written characters. The structure of the model contains significant information about how images of characters are created and this is exploited to understand new types of character. Second, we consider a more generic generative model that learns how to generate families of data classes.
Pen-stroke model
Lake et al. (2015) construct a hierarchical non-parametric generative model for hand-written characters using a probabilistic programming approach . At the first level, a set of primitives are combined into parts, each of which is a single pen-stroke. Multiple parts are then connected to create characters. This process is illustrated in figure 6a. At the second level, a realisation of the character is created by simulating the pen-strokes for that character under noisy conditions.

Figure 6. Generative model learning. a) Pen-stroke model of Lake et al. (2015). A learned set of basic strokes is combined together to make classes. Each class can generate multiple realisations of the character. b) The neural statistician Edwards & Storkey (2016). In its simplest form, this model has a very similar structure to the pen-stroke model. An object class $\mathbf{c}_{k}$ is generated from a distribution over classes and realizations $\mathbf{x}_{nk}$ of the data are generated (via hidden variables $\mathbf{z}_{nk}$) from these classes).
During the meta-learning process, the set of primitives are learned such that they can be combined to describe sets of unseen characters. The system has access to the actual pen-strokes for training which makes this learning easier. The support set of the test task is used to describe the new classes in terms of this fixed set of primitives. For a query in the test task, the posterior probability that it was generated from each of the character classes is computed.
The structure of the model (primitive pen strokes, and likely combinations) is hence prior information learned from previous sets of characters that can be exploited to discriminate unseen classes.
Neural statistician
Edwards & Storkey (2016) presented a more generic model which they termed the neural statistician as it learns the statistics of both classes and examples in a dataset. This model can generate new examples of classes and examples of any data and contains no prior information about the generation process (e.g., about pen-strokes or image transformations).
The model has a similar generative structure to the pen stroke model, but is based on the variational auto-encoder (figure 6b). At the top level is a context vector $\mathbf{c}$. A probability distribution over the context vector describes the statistics of a single class. In the context of few-shot learning, we might have $N$ context vectors indexed as $\mathbf{c}_{n}$ representing the $N$ classes. Each generates $K$ hidden variables $\{\mathbf{z}_{nk}\}_{k=1}^{K}$ and each of these generates a data example $\mathbf{x}_{nk}$. In this way, a single task for the N-way-K-shot problem is generated.2
The support sets from the training tasks are used to learn the parameters of this model using a modification of the variational auto-encoder that allows inference of both context variables and hidden variables. For the test task, the support set is used to infer the context vectors and hidden variables that explain this dataset. Classification of the query set can be done by evaluating the probability that each data example was generated by the context vector for each class. As for the pen-stroke model, prior knowledge is accumulated in building the structure of the model during meta-learning, which means that unseen classes can be modelled effectively from only a few data examples.
Rezende et al. (2016) presented a related model that was also based on the VAE but differed in that (i) it was specialized to images and contained prior knowledge about image transformations (ii) generation was conditioned explicitly on a new class example, as opposed to inferring a hidden variable representing the class.
Data augmentation approaches
Hariharan & Girshick (2017) proposed a method for hallucinating new examples to augment datasets where few data examples are available. Their proposed approach is based on the intuition that learned intra-class variations are both transferable and generalize well to novel classes.
They assume that they have a large body of data with many examples per class from which they can learn about intra-class variation. They then exploit this knowledge to create extra examples in the few-shot test scenario. Their learning approach is based on analogy; if in the training data we observe embeddings $\mathbf{z}_{11}$ and $\mathbf{z}_{12}$ for class 1, then perhaps we can use the embedding $\mathbf{z}_{21}$ from class 2 to predict a new variation $\mathbf{z}_{22}$. In other words, we aim to answer the question “if $\mathbf{z}_{11}$ is to $\mathbf{z}_{12}$ then $\mathbf{z}_{21}$ is to what?” (figure 7).

Figure 7. Augmenting data using analogies. New feature vectors are generated from the limited examples in the few-shot scenario to improve performance. a) The generator takes quadruplets of examples (from an external database) and learns analogical relations between them. b) To generate new examples, the system predicts the missing part of the analogy.
This analogy task is performed using a multi-layer perceptron that takes $\mathbf{z}_{11}$, $\mathbf{z}_{12}$ and $\mathbf{z}_{21}$ and predicts $\mathbf{z}_{22}$. They learn this network from quadruplets of features taken from training tasks with plentiful data.3 The loss function encourages both accurate prediction of the missing feature vector and also correct classification of the synthesized example. For few-shot test tasks, the data is augmented using this generator by analogy with the plentiful training classes and it is shown that this significantly improves performance.
Subsequently Wang et al. (2018) proposed an end-to-end framework that jointly optimizes a meta-learner (such as a prototypical network) and a hallucinator (which generates additional training examples). Samples are hallucinated by a multi-layer perceptron that takes a training example and a noise vector and generates a new example. The new samples are added to the original training set and this augmented training set is used to learn parameters of classifier. Loss is back-propagated and both parameters of the classification algorithm and parameters of the hallucinator are updated. A key notion here is that it is not the plausibility of the new examples that is important, but rather it is their ability to improve classification performance in a few-shot setting.
Conclusion
There is enormous diversity in approaches to meta-learning and few-shot learning, but there is currently no consensus on the best approach. Probably the most thorough empirical comparison was by Chen et al. (2019) (figure 8), but this mainly focuses on approaches that learn embeddings. It should be noted as well, that many of the approaches are complementary to one another and a practical solution would be to combine them.
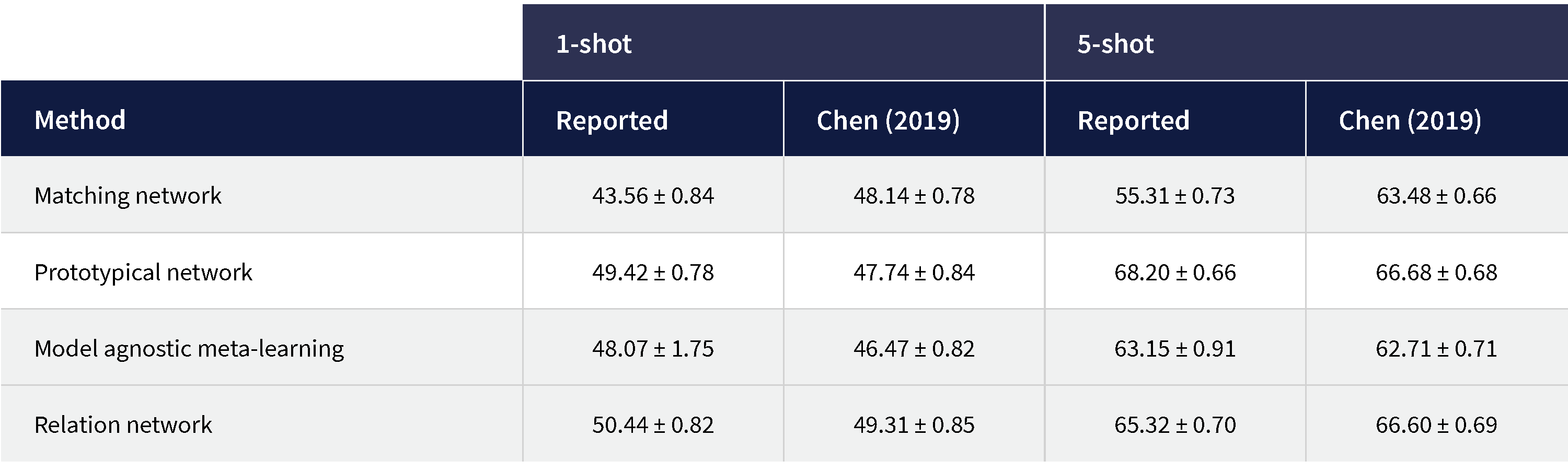
Figure 8. Meta-learning results comparison from Chen et al. (2019). Results reported in mini-ImageNet for one-shot and five-shot learning tasks. Both results from the original papers plus re-implemented results are compared.
Few-shot learning and meta-learning are likely to gain in importance as AI penetrates more specific problem domains where the cost of gathering data is too great to justify a brute force approach. They remain interesting open problems in artificial intelligence.
1 This update can be iterated, but we will describe a single update for simplicity of notation.
2 In practice, the model is somewhat more complicated than this with a sequence of dependent hidden variables describing each data example.
3 The analogies are actually learned from cluster centers of the data and are chosen so that the cosine similarity between $\mathbf{z}_{11}-\mathbf{z}_{12}$ and $\mathbf{z}_{21}-\mathbf{z}_{22}$ is greater than zero.
Work with Us!
Impressed by the work of the team? RBC Borealis is looking to hire for various roles across different teams. Visit our career page now and discover opportunities to join similar impactful projects!
Careers at RBC Borealis