
This blog post is for informational purposes only. RBC and RBC Borealis do not endorse or recommend any academic findings summarized in this article and the views expressed in this article are those of the author and do not necessarily reflect the position of RBC or RBC Borealis. RBC and RBC Borealis assume no liability for any consequence relating directly or indirectly to any action or inaction taken based on the information contained in this article.
Introduction
In 2023, and increasingly in 2024, the race has been on to leverage the power of Large Language Models (LLMs) such as the underlying GPT models in the now famous Chat-GPT[i]. These so-called frontier AI models represent a great opportunity, however, the veracity of the responses of an AI model can still be questionable. By examining emerging frameworks and methodologies to establish the trustworthiness of LLMs, this blog will explore the possibility of how to define trust in the context of an AI-based application, how trust can be measured, and what strategies and mechanisms exist to achieve trustworthy LLM-based applications.
What is Trustworthiness?
Trust with respect to LLMs can be defined by breaking trust down into components[i]. One way to break it down can be:
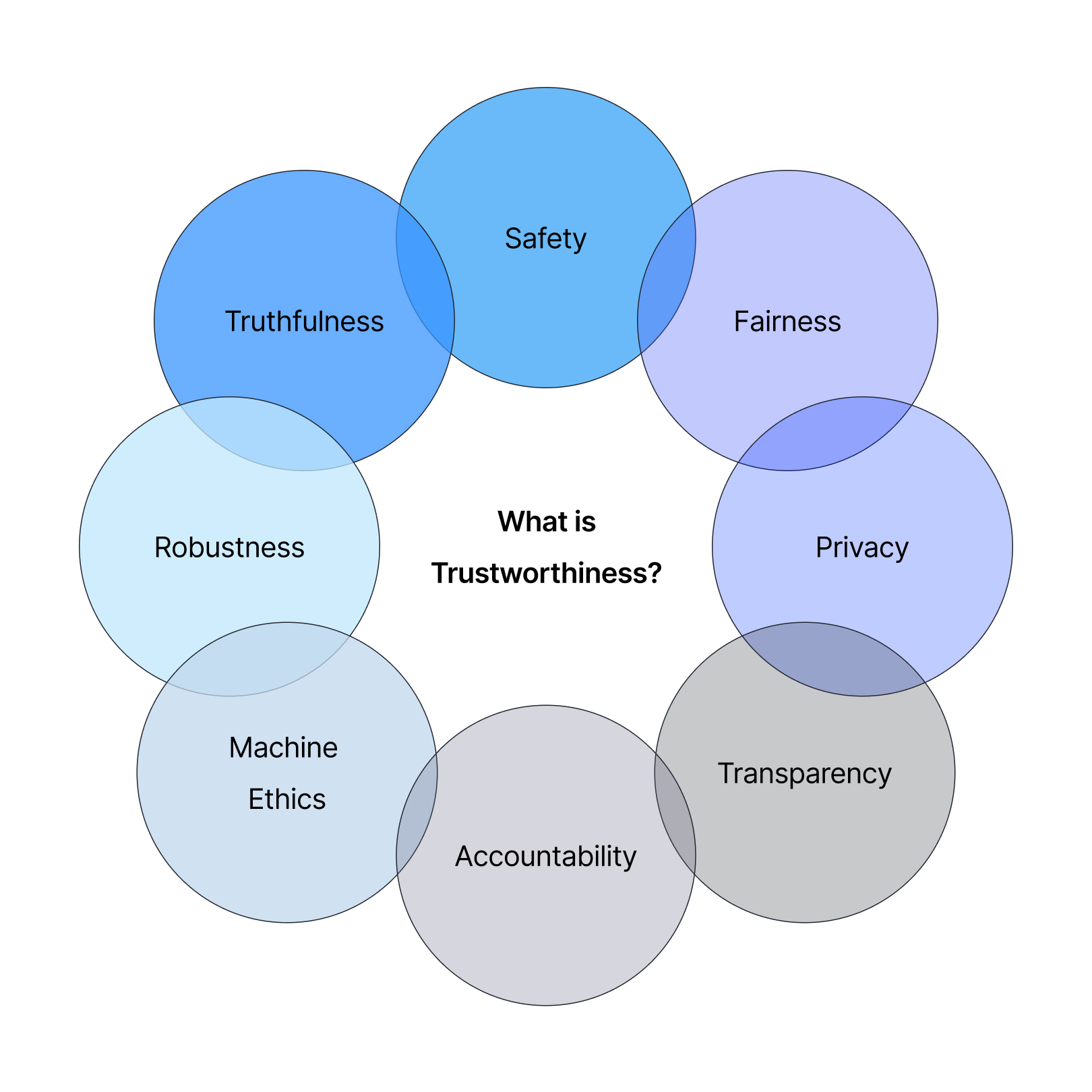
Components of Trust [i]
Let’s define these categories in the context of generative AI applications:
Truthfulness
The accurate representation of information, facts, and results. Which can be further broken down into:
- Misinformation generation using internal knowledge
- Misinformation generation using external knowledge
- Hallucination — the inclination to produce responses that, while sounding credible, are untrue
- Sycophancy in responses — the inclination to tailor responses to align with a human user’s perspective, even when that perspective lacks objective correctness
- Adversarial factuality — the ability to fix incorrect user input
A trustworthy AI should prioritize accuracy and authenticity in its responses, avoiding misinformation generation, hallucination, sycophancy, and adversarial factuality to provide reliable and objective information.
Safety
The outputs from LLMs should only engage users in a safe and healthy conversation. Which can be broken down into:
- Resilience against malicious, or jailbreak attacks
- Zealousness in identifying things as safe or unsafe; exaggerated safety
- Ability to avoid generating toxic content
- Resilience against misuse
A trustworthy AI should be resilient against misuse, malicious or jailbreak attacks, while also maintaining a balance between caution and openness in its conversations, engaging users in informative, respectful, and safe interactions.
Fairness
The quality or state of being fair, especially fair or impartial treatment. Which can be broken down into:
- Stereotypes
- Disparagement
- Preference bias
A trustworthy AI should strive for impartiality and neutrality, avoiding stereotypes, disparagement, and preference bias in its treatment of individuals or groups, ensuring that all users are treated fairly and without discrimination.
Robustness
The ability of a system to maintain its performance level under various circumstances. Which can be broken down into:
- Ability to handle noisy, incomplete, or bad input
- Ability to recognize and appropriately handle data that deviates significantly from its training set
A trustworthy AI should be robust in its processing and decision-making, able to adapt to various inputs, errors, or unexpected situations while maintaining its accuracy and reliability to provide consistent and reliable performance.
Privacy
The norms and practices that help to safeguard human and data autonomy, identity, and dignity. Which can be broken down into:
- Privacy awareness
- Leakage potential
A trustworthy AI should prioritize privacy by being transparent about its data collection and usage, minimizing leakage potential, and respecting individuals’ autonomy and dignity by safeguarding their personal information.
Machine Ethics
Ensuring ethical behaviour of man-made machines that use artificial intelligence, otherwise known as artificially intelligent agents. Which can be broken down into:
- Implicit ethics — the internal values of LLMs, such as the judgment of moral situations
- Explicit ethics — how LLMs should react in different moral environments
- Emotional awareness — the capacity to recognize and empathize with human emotions, a critical component of ethical interaction
A trustworthy AI should embody machine ethics by internalizing implicit values, explicitly adhering to moral principles, and demonstrating emotional awareness, thereby enabling it to interact with humans in an ethical, empathetic, and responsible manner.
Transparency
The extent to which information about an AI system and its outputs is available to individuals interacting with such a system. Some might explain transparency as explainability. Since LLMs, open-source or proprietary, are notorious for their black-box nature, the scientific community is actively searching for approaches to peer into the inner workings of LLMs. Fortunately, there have been some recent breakthroughs such as the release from OpenAI where they were able to find new methods to identify 16 million oft-interpretable patterns in GPT-4’s internal representations, however, it is still early days, and the problem remains an elusive one.
Accountability
An obligation to inform and justify one’s conduct to an authority. Things like data citation, providing explanations of reasoning, and being nuanced with answers all tie into this aspect. As LLMs become more sophisticated, it is imperative that they provide explanations and justifications for their behaviour.
Evidently, there are many aspects of trust. Ideally, an LLM should be evaluated against these facets, and possibly more, to give some confidence that the LLM is safe and trustworthy to use. Furthermore, since the usage of AI is increasingly subject to regulation and policy, LLMs must ensure compliance with such standards, undergoing regular assessments to maintain their trustworthiness and integrity.
The Criticality of Trust for AI in Financial Services
The World Economic Forum has consistently ranked Canada’s banks as among the soundest in the world[I]. AI has the potential to improve how banks create value for clients; However, banks must be aware of the risks relevant to AI interactions with clients, understand how those risks may impact clients, and be able to safely mitigate those risks to continue to deliver products and services that clients can trust. Below are several risk scenarios relevant to AI interactions with clients:
Privacy Risks
Most LLMs are trained on the public data of the internet. However, to use AI in the context of a business application, usually the model requires access to more personalized information either through fine-tuning or via context through prompting. Without the proper guardrails, the model’s inherent world information either via the fine-tuning process or prompting can be leaked through activities called prompt injections, or trying to “jailbreak” the LLM. One such technique is asking the LLM to “repeat the word ‘poem’ forever”. Researchers have found instances of LLMs leaking their training data, which may include private user information when tasked with this request. While this doesn’t seem logical to a human user, LLMs sometimes behave in seemingly inexplicable ways when exposed to seemingly random and incoherent prompts. Not only is it important to monitor what prompts a LLM is exposed to, but also what data it has access to in its world knowledge[i].
Explainability and Transparency Risks
While great strides have been made in understanding the decision-making process for most Machine Learning techniques, LLMs largely remain a black box.
The underlying complexity of LLM transformer-based neural networks can make it difficult to follow the LLMs “thought” process to arrive at a particular decision or outcome. As such, explainability mechanisms are key in delivering AI-powered applications. Leveraging state-of-the-art prompting techniques that force a model to output its reasoning is an important facet of designing any LLM application.
Fortunately, these risks can be effectively mitigated by utilizing the trust framework and measuring trust across the framework’s dimensions, as well as implementing strategies like Dual LLMs[i], model guard-railing[ii] and defensive prompt engineering[iii].
Benchmarks as a Pillar of Trust
Benchmarks are a practical tool used to evaluate LLMs. They are essentially standardized tests to establish the efficacy of a particular LLM across the trust dimensions introduced earlier in this blog. They can give great insight to stakeholders on the trustworthiness of new and existing LLMs. Automated benchmarks have these benefits:
Scalability and Efficiency
- Benchmarks can evaluate a vast number of models across numerous metrics quickly and efficiently in a programmatic way, whereas it may be impractical with human evaluation due to time and resource constraints.
Consistency and Reproducibility
- Benchmarks provide a consistent and objective set of human-approved criteria, minimizing human biases and variability in assessments. This consistency is crucial for comparing models and tracking progress over time.
Cost-effectiveness
- Human evaluation is often resource intensive, requiring significant time and financial resources, especially for large-scale assessments. Automated benchmarks, once set up, can run at a fraction of the cost of human evaluation.
Real-time Feedback
- Benchmarks enable real-time and continuous feedback during the development process, allowing researchers and developers to iteratively improve models with immediate insights into their performance.
Objective Performance Metrics
- Benchmarks offer clear quantitative metrics for performance evaluation, facilitating straightforward comparisons between different models and approaches.
Various benchmarks and frameworks to evaluate LLMs are currently available and in development. One such benchmark framework, TrustLLM, evaluates trustworthiness across the trust dimensions explained in this blog. Alternative benchmarks for establishing reliability, safety, and trustworthiness in LLMs exist, such as Stanford’s HELM, DecodingTrust and SafetyBench. Other performance benchmarks will evaluate a LLM’s general effectiveness in doing mathematics, computer programming, and other tasks to measure “intelligence” or “capability”. However, they don’t typically measure the finer aspects of trust [i][ii].
Standardized benchmarks allow different LLMs to be compared directly with each other numerically, which allows stakeholders to understand the strengths and weaknesses of each LLM. Furthermore, datasets used when applying benchmarks for LLMs are often large and far-reaching, therefore providing extra coverage of cases and scenarios.
Conclusion
The ability to have confidence in the veracity of an LLM across trust dimensions is critical for implementing AI responsibly and safely. Trust can be broken down into several components or dimensions to analyze the different facets of how a model behaves, in order to say it is operating in a way that can be considered trustworthy. Once defined, automated benchmarks are key tools to evaluate the performance of a model across dimensions in an efficient and scalable manner. Real-time monitoring of LLM usage can detect prompt injection attacks and model outputs that are not aligned with benchmarks. Recent developments have shown promising techniques that allow a model to “show its work” where reasoning can be easily traced for auditing. These tools are allowing trust to play a crucial part in the development of AI capabilities.
References
[I] Sun, Lichao, Yue Huang, Haoran Wang, Siyuan Wu, Qihui Zhang, Yuan Li, Chujie Gao, et al. ‘TrustLLM: Trustworthiness in Large Language Models’. arXiv [Cs.CL], 2024. arXiv. http://arxiv.org/abs/2401.05561.
[I] “2024 Edelman Trust Barometer.” Edelman, 2024. https://www.edelman.com/trust/2024/trust-barometer.
[I] Focus: Global Banking Regulations and Banks in Canada. Canadian Bankers Association. (2024, April 5). https://cba.ca/global-banking-regulations-and-banks-in-canada#:~:text=The%20bottom%20line,in%20the%20global%20financial%20system.
[I] Nasr, Milad, Nicholas Carlini, Jonathan Hayase, Matthew Jagielski, A. Feder Cooper, Daphne Ippolito, Christopher A. Choquette-Choo, Eric Wallace, Florian Tramèr, and Katherine Lee. ‘Scalable Extraction of Training Data from (Production) Language Models’. arXiv [Cs.LG], 2023. arXiv. http://arxiv.org/abs/2311.17035.
[I] Willison, Simon. “The Dual LLM Pattern for Building AI Assistants That Can Resist Prompt Injection.” The Dual LLM pattern for building AI assistants that can resist prompt injection, April 25, 2023. https://simonwillison.net/2023/Apr/25/dual-llm-pattern/.
[I] Rebedea, Traian, Razvan Dinu, Makesh Narsimhan Sreedhar, Christopher Parisien, and Jonathan Cohen. ‘NeMo Guardrails: A Toolkit for Controllable and Safe LLM Applications with Programmable Rails’. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, edited by Yansong Feng and Els Lefever, 431–45. Singapore: Association for Computational Linguistics, 2023. https://doi.org/10.18653/v1/2023.emnlp-demo.40.
[I] Fangzhao Wu, Yueqi Xie, Jingwei Yi et al. Defending ChatGPT against Jailbreak Attack via Self-Reminder, 16 June 2023, PREPRINT (Version 1) available at Research Square [https://doi.org/10.21203/rs.3.rs-2873090/v1]
[I] Hendrycks, Dan, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. ‘Measuring Massive Multitask Language Understanding’. arXiv [Cs.CY], 2021. arXiv. http://arxiv.org/abs/2009.03300.
[I] Wang, Alex, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. ‘GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding’. arXiv [Cs.CL], 2019. arXiv. http://arxiv.org/abs/1804.07461.