
SLAPS: Self-Supervision Improves Structure Learning for Graph Neural Networks
What problem does it solve?
Graph neural networks (GNNs) excel at performing semi-supervised classification with the aid of a graph structure for the set of input examples. In recent years, researchers have begun applying GNNs to semi-supervised datasets that don’t include graph-structure information, by generating a graph structure from the data. The paper identifies and solves a ‘supervision starvation’ problem in a promising approach called latent graph learning, which jointly optimizes a graph structure and a GNN classifier.
Why is this important?
Much of the great success of modern neural network methods comes from applying architectural inductive biases like convolution and attention to structured inputs. One reason that graph neural networks (GNNs) are an exciting area of research is the promise of applying similar architectural techniques to structure in the input domain as a whole, by treating input examples as nodes in a graph. Previous work demonstrates that it’s sometimes possible to leverage the strengths of GNNs even when no graph information is available, by using label and feature information to construct an inputs-example graph with GNN-friendly properties. Since GNN classifiers are known to excel on graphs with high label homophily (i.e. connected nodes often belong to the same class), graph construction typically focuses on label homophily and on feature homophily as a proxy. The simplest methods pre-construct a graph through a kNN algorithm, while more sophisticated methods try to infer a graph during training.
The approach taken and how it relates to previous work
In existing methods for latent graph learning, a neural network that assigns graph-structure to the input set is optimized together with a graph convolutional network (GCN) that classifies input examples based on their graph neighbors. The paper’s central observation is that in this setting, training for classification can’t properly optimize the graph: some edges, which the paper calls ‘starved edges,’ have no impact on the training loss but do affect the classifier’s predictions at test time. Since the values of these edges are learned without any training feedback, the model is at risk of making poor predictions at test time.
The existence of starved edges follows from the fact that an n-layers GCN makes predictions for input examples based on their n-hop neighbors. Edges between examples that are each ≥n hops from any labeled example cannot affect any supervised prediction, and will therefore be ‘starved’ for supervision. Furthermore, it turns out that in typical latent-graph learning scenarios we should expect most edges to be starved: The authors observe that in a random graph (aka Erdos-Rényi graph) or scale-free network with the statistics of graph-structured datasets like Cora, Citeseer, and Pubmed, a random edge is more likely to be starved than unstarved. In particular, they give a simple proof that for an Erdos-Rényi graph with n nodes and m edges, if we have labels for q nodes selected uniformly at random then the probability of an edge being a starved edge is:
\begin{equation}\left ( 1-\frac{q}{n} \right )\left ( 1-\frac{q}{n-1} \right )\prod_{i=1}^{2q}\left ( 1- \frac{m-1}{\binom{n}{2}-i} \right)\end{equation}
Furthermore, the proportion of starved edges in the actual Cora, Citeseer, and Pubmed datasets is very close to their probability in the analogue Erdos-Rényi graphs, so there is reason to believe that Erdos-Rényi graphs are a good model of natural graphs in this regard.
The paper proposes to solve the starved-edge problem by adopting SLAPS (Simultaneous Learning of Adjacency and GNN Parameters with Self-supervision), a multi-task learning framework that supplements the classification task with a self-supervised task. The self-supervised task is based on the hypothesis that a graph structure suitable for predicting the features of input examples is also suitable for predicting their labels. The authors add a denoising autoencoder GNN downstream of the graph generator, optimizing the full system (graph-generator, classifier, and denoising autoencoder) with a mixture of autoencoder loss and classifier loss.The training process thus encourages the graph generator to produce a graph structure that provides the denoising autoencoder with useful auxiliary information for denoising the input examples.
Results
The authors compare their multi-task framework with existing graph-construction and latent-graph learning methods on a range of semi-supervised classification datasets. The main experiment uses a ‘graphless’ version of the graph-structured semi-supervised classification benchmarks Cora, Citiseer, and Pubmed, showing that SLAPS recovers a useful graph-structure from input examples alone. SLAPS strongly outperforms the baseline MLP, and significantly outperforms GNN methods that rely on pre-constructing graphs or supervised latent graph learning:
| MODEL | Cora | Citeseet | Cora390 | Citeseer370 | Pubmed | ogbn-arxiv |
|---|---|---|---|---|---|---|
| MLP | 56.1 ± 1.6† | 56.7 ± 1.7† | 65.8 ± 0.4 | 67.1 ± 0.5 | 71.4 ± 0.0 | 51.7 ± 0.1 |
| MLP-GAM* | 70.7‡ | 70.3‡ | – | – | 71.9‡ | – |
| LP | 37.6 ± 0.0 | 23.2 ± 0.0 | 36.2 ± 0.0 | 29.1 ± 0.0 | 41.3 ± 0.0 | OOM |
| kNN-GCN | 66.5 ± 0.4† | 68.3 ± 1.3† | 23.2 ± 0.0 | 71.8 ± 0.8 | 70.4 ± 0.4 | 49.1 ± 0.3 |
| LDS | – | – | 71.5 ± 0.8† | 71.5 ± 1.1ƚ | OOM | OOM |
| GRCN | 67.4 ± 0.3 | 67.3 ± 0.8 | 71.3 ± 0.9 | 70.9 ± 0.7 | 67.3 ± 0.3 | OOM |
| DGCNN | 56.5 ± 1.2 | 55.1 ± 1.4 | 67.3 ± 0.7 | 66.6 ± 0.8 | 70.1 ± 1.3 | OOM |
| IDGL | 70.9 ± 0.6 | 68.2 ± 0.6 | 73.4 ± 0.5 | 72.7 ± 0.4 | 72.3 ± 0.4 | OOM |
| kNN-GCN + AdaEdge | 67.7 ± 1.0 | 68.8 ± 0.3 | 72.2 ± 0.4 | 71.8 ± 0.6 | OOT | OOM |
| kNN-GCN + self-training | 67.3 ± 0.3 | 69.8 ± 0.3 | 71.1 ± 0.3 | 72.4 ± 0.2 | 72.7 ± 0.1 | NA |
| SLAPS (FP) | 72.4 ± 0.4 | 70.7 ± 0.4 | 76.6 ± 0.4 | 73.1 ± 0.6 | OOM | OOM |
| SLAPS (MLP) | 72.8 ± 0.8 | 70.5 ± 1.1 | 75.3 ± 1.0 | 73.0 ± 0.9 | 74.4 ± 0.6 | 56.6 ± 0.1 |
| SLAPS (MLP-D) | 73.4 ± 0.3 | 72.6 ± 0.6 | 75.1 ± 0.5 | 73.9 ± 0.4 | 73.1 ± 0.7 | 52.9 ± 0.1 |
| SLAPS (MLP) + AdaEdge | 72.8 ± 0.7 | 72.6 ± 1.5 | 75.2 ± 0.6 | 72.6 ± 1.4 | OOT | OOT |
| SLAPS (MLP) + self-training | 74.2 ± 0.5 | 73.1 ± 1.0 | 75.5 ± 0.7 | 73.3 ± 0.6 | 74.3 ± 1.4 | NA |
The authors also study the application of SLAPS to semi-supervised classification on datasets with noisy or corrupted graph-structure information, and find that using noisy graph information to initialize SLAPS is greatly preferable to feeding the noisy graph information directly to a classifier GNN:
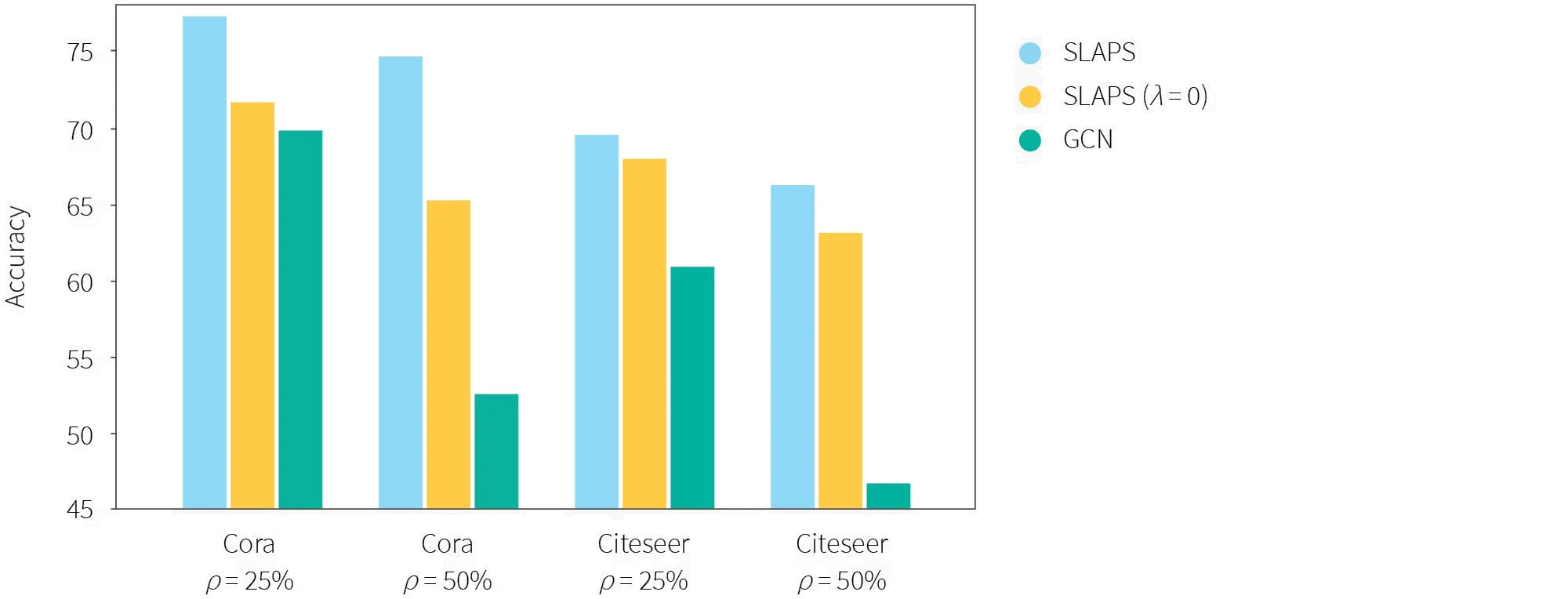
Figure 5: Performance comparison when noisy graphs are provided as input (ρ indicates the percantage of perturbations).

Continuous Latent Process Flows
What problem does it solve?
The paper studies the use of latent stochastic differential equations (SDEs) together with normalizing flows to learn continuous time-series dynamics. When learning continuous time-series dynamics, the objective is to maximize the observational log-likelihood of an inhomogeneous collection of training sequences with varying lengths and time stamps. At test-time, in addition to the maximization of observational log-likelihoods, we are also interested in sampling trajectories in a manner consistent with these log-likelihoods.
The authors improve on the state of the art in the field by employing a normalizing flow as a time-dependent decoder for a flexible latent SDE, achieving greater expressivity compared to methods that rely on a normalizing flow alone. The price of the increase in expressivity is that the observational log-likelihood becomes intractable, making variational approximations necessary. The authors formulate a principled variational approximation of the observational log-likelihood, based on a piecewise construction of the posterior distribution of the latent SDE.
Why is this important?
Sparse and irregular observations of continuous dynamics are common in many areas of science, including finance, healthcare, and physics. Time-series models driven by stochastic differential equations provide an elegant framework for this challenging scenario and have recently gained popularity in the machine learning community. The SDEs are typically implemented by neural networks with trainable parameters, and the latent processes defined by the SDEs are then decoded into an observable space with complex structure.
Despite great recent progress in the field, it remains challenging to produce models that are both computationally tractable and flexible. Cutting edge methods built around combining a simple latent process with invertible transformations have the benefit of giving exact and efficient likelihood evaluation of observations, but can only model a limited class of stochastic processes. In particular, the otherwise highly effective flow-based method CTFP (‘continuous-time flow process’) is provably incapable of modeling some commonplace stochastic processes, from simple processes like the Ornstein-Uhlenbeck (OU) process to more complex non-Markov processes. A more formal difficulty with models like CTFP is that standard neural networks practice for constructing reversible transformations implies Lipschitz continuity, and Lipschitz-continuous reversible transformations of simple processes are especially limited. Transforming a simple stochastic process into Brownian motion, for example, requires a non-Lipschitz function and therefore non-standard network architecture.
The approach taken and how it relates to previous work
The paper introduces Continuous Latent Process Flows (CLPF). CLPF treats an observed sequence as a partial realization of a continuous-time observable stochastic process Xt, and treats Xt in turn as a function of the trajectory of a flexible SDE process Zt together with the trajectory of a simple stochastic process Ot. (e.g., an OU-process).
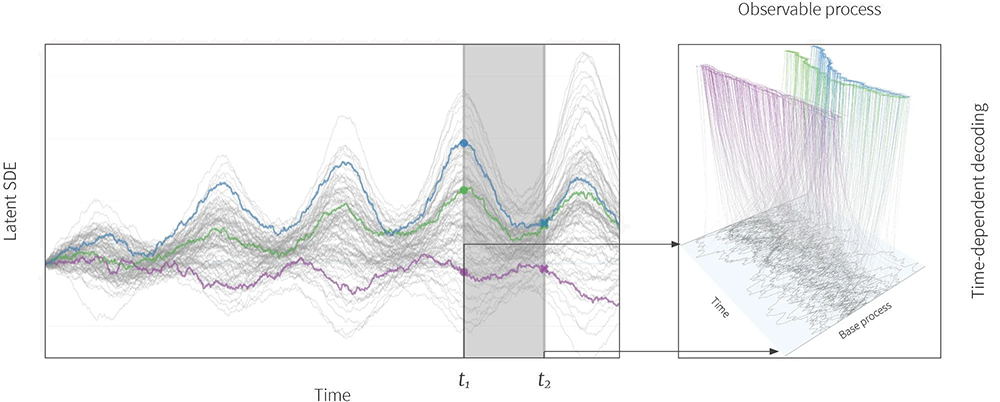
Figure 2: Overview. Our architecture uses a stochastic differential equation (SDE; left) to drive a time- dependent normalizing flow (NF; right). Attime t1, t2 (grey bars), the values of the SDE trajectories (colored trajectories on the left) serve as conditioning information for the decoding of a simple base process (grey trajecto-ries on the right) into a complex observable process (colored trajectories on the right). The color gradient on the right shows the individual trajectories of this transformation, which is driven by an augmented neural ODE. Since all stochastic processes and mappings are time-continuous, we can model observed data as partial realizations of a continuous process, enabling modelling of continuous dynamics and inference on irregular time grids.
Concretely, the CLPF framework models the evolution of an m-dimensional time-continuous latent state Zₜ in the time interval [0,T] using a flexible stochastic differential equation
\begin{equation}\mathrm{d} \boldsymbol{Z}_{t}=\boldsymbol{\mu}_{\gamma}\left(\boldsymbol{Z}_{t}, t\right) \mathrm{d} t+\sigma_{\gamma}\left(\boldsymbol{Z}_{t}, t\right) \mathrm{d} \boldsymbol{W}_{t}\end{equation}
where Wₜ is an m-dimensional Wiener Process and γ denotes the (shared) learnable parameters of the drift function µ and variance function σ.
The latent SDE dynamics then produce an observable process Xt as follows:
\begin{equation}X_{t}=F_{\theta}\left(O_{t} ; Z_{t}, t\right)\end{equation}
where Oₜ is a d-dimensional Ornstein–Uhlenbeck process with closed-form transition density and Fθ( · ; zₜ, t) is a normalizing flow parameterized by θ for any zₜ, t.
Because CLPF latent dynamics follow a generic, flexible SDE process, exact computations of the observational log-likelihood are generally intractable. It’s therefore necessary to use a variational approximation to compute the training gradient of a CLPF model or perform inference. To this end, the authors construct a novel evidence lower bound (ELBO)
\begin{equation}\mathbb{E}_{\omega^{(1)}, \ldots, \omega^{(n)} \sim W_{t}^{(1)} x \ldots \times W_{t}^{(n)}}\left[\sum_{i=1}^{n} \log p\left(x_{t_{1}} \mid x_{t_{1-1}}, \tilde{z}_{t_{1}}, \tilde{z}_{t_{i-1}}, \omega^{(i)}\right)+\sum_{i=1}^{n} \log M^{(i)}\left(\omega^{(i)}\right)\right]\end{equation}
where wt⁽1⁾,…,wt⁽ⁿ⁾ are independent Wiener processes that (speaking informally for brevity) construct Wt piece-wise and M is an importance weight between the prior and posterior latent SDE.
Results
The authors compare CLPF with previous continuous dynamics methods for modelling irregular observations of a continuous process, as well as with a non-continuous Variational RNN (VRNN) baseline that excels in likelihood estimation but cannot properly generate trajectories.
The authors first evaluate CLPF on synthetic data sampled from known stochastic processes, to verify its ability to capture a variety of continuous dynamics. They compare CLPF with previous continuous methods on the synthetic cases Geometric Brownian Motion, Linear SDE, Continuous AR(4) Process, and Stochastic Lorenz Curve:
| Model | GBM | LSDE | CAR | SLC | ||||
|---|---|---|---|---|---|---|---|---|
| λ=2 | λ=20 | λ=2 | λ=20 | λ=2 | λ=20 | λ=20 | λ=40 | |
| VRNN | 0.425 | -0.650 | -0.634 | -1.665 | 1.832 | 2.675 | 2.237 | 1.753 |
| LatentODE[33] | 1.916 | 1.796 | 0.900 | 0.847 | 4.872 | 4.765 | 9.117 | 9.115 |
| CTFP[12] | 2.940 | 0.678 | -0.471 | -1.778 | 383.593 | 51.950 | 0.489 | -0.586 |
| LatentCTFP[12] | 1.472 | -0.158 | -0.468 | -1.784 | 249.839 | 43.007 | 1.419 | -0.077 |
| LatentSDE[25] | 1.243 | 1.778 | 0.082 | 0.217 | 3.594 | 3.603 | 7.740 | 8.256 |
| CLPF(ours) | 0.444 | -0.698 | -0.831 | -1.939 | 1.322 | -0.077 | -2.620 | -3.963 |
In order to evaluate CLPF on real data, the authors generate irregular time-series data by sampling from the Mujoco-Hopper, Beijing Air-Quality Dataset (BAQD), and PTB Diagnostic Database (PTBDB) datasets at irregular time-intervals. The authors find that CLPF outperforms existing continuous-dynamics models in likelihood estimation, and nearly closes the gap with VRNN in sequential prediction:
| Model | Mujoco[33] | BAQD[37] | PTBDB[5] |
|---|---|---|---|
| VRNN[10] | -15876 | -1.204 | -2.035 |
| LatentODE[33] | 23551 | 2.540 | -0.533 |
| LatentSDE[25 | 3071 | 1.512 | -1.358 |
| CTFP[12] | -7598 | -0.170 | -1.281 |
| LatentCTFP[12] | -12693 | -0.480 | -1.659 |
| CLPF-ANODE(ours) | -14694 | -0.619 | -1.575 |
| CLPF-iRes(ours) | -10873 | -0.486 | -1.519 |
| Model | GBM | LSDE | CAR | SLC |
|---|---|---|---|---|
| CLPF-Global | 0.447 | -0.821 | 1.552 | -3.304 |
| CLPF-Intependent | 0.800 | -0.326 | 4.970 | 7.924 |
| CLPF-Wiener | 0.390 | -0.790 | 1.041 | -1.885 |
| Latent SDE | 1.243 | 0.082 | 3.594 | 7.740 |
| CLPF | 0.444 | -0.831 | 1.322 | -2.620 |
| Model | Mujoco[33] | BAQD[37] | PTBDB[5] |
|---|---|---|---|
| VRNN[10] | 1.599,[0.196,1.221] | 0.519, [0.168, 0.681] | 0.037, [0.005, 0.032] |
| LatentODE[33] | 13.959, [9.857, 15.673] | 1.416, [0.936, 1.731] | 0.224, [0.114, 0.322] |
| LatentSDE[25] | 7.627, [2.384, 8.381] | 0.848, [0.454, 1.042] | 0.092, [0.032, 0.111] |
| CTFP[12] | 1.969, [0.173, 1.826] | 0.694, [0.202, 10966] | 0.055, [0.006, 0.046] |
| LatentCTFP[12] | 1.983, [0.167, 1.744] | 0.680, [0.189, 0.943] | 0.065, [0.007, 0.059] |
| CLPF-ANODE(ours) | 1.629, [0.149, 1.575] | 0.542, [0.150, 0.726] | 0.048, [0.005, 0.041] |
| CLPF-iRes (ours) | 1.846, [0.177, 1.685] | 0.582, [0.183, 0.805] | 0.055, [0.006, 0.049] |

Not Too Close and Not Too Far: Enforcing Monotonicity Requires Penalizing The Right Points
What problem does it solve?
It is often desirable for a neural network to be monotonic: informally, to have an output function that is non-decreasing with respect to certain features. This paper identifies problems with existing general methods for training a neural network to be monotonic, and proposes a superior general method.
Why is this important?
Monotonicity is a common requirement in real-life applications of prediction models. For example, in the case of models used to accept/reject job applications, we expect acceptance scores to be monotonically non-decreasing with respect to features such as a candidate’s years of experience. Such expectations of monotonicity often reflect accepted institutional best practices, or ethical or legal norms, so that predictors that fail on monotonicity are unacceptable for real-life use.
The approach taken and how it relates to previous work
While it is possible to guarantee monotonicity by defining a ‘monotonous by construction’ model class, such model classes have limited use since they exclude many commonly used neural network architectures. More generally applicable approaches focus on finding monotonic candidates within a general class of models while performing empirical risk minimization. Since the verification of a model’s monotonicity can be extremely computationally expensive, these approaches typically do not provide a guarantee. Instead, they rely on regularization penalties that bias a learning algorithm towards monotonic predictors.
The general form of the regularization penalty is:
\begin{equation}\mathbb{E}_{x \sim \mathcal{D}}\left[\sum_{i \in M} \max \left(0,-\frac{\partial h(x)}{\partial x_{i}}\right)^{2}\right]\end{equation}
where M is the set of input dimensions with respect to which monotonicity is desired, and
)/xi indicates the gradients of the predictor h relative to the input dimensions i ∈ M. In other words, we penalize h for behaving non-monotonically at points sampled from some distribution D.
The paper’s novel contribution concerns the choice of distribution D. In previous work, the chosen D was either the empirical distribution of the training sample, or a uniform distribution over the input space. The paper demonstrates that both choices have serious shortcomings: When D is the empirical training distribution, monotonicity is only enforced close to the training data, and may fail on the test data in the case of a covariate shift. When D is the uniform distribution, the sampled points will likely lie far from the training data, thus failing to enforce monotonicity around the training data. (This is particularly likely given a high-dimensional input space, where points sampled in uniform are likely to lie close to the input space’s boundary.)
The paper’s solution is to compute the regularization penalty on points generated by mixing up points from the training data and random points. To sample from the ‘mixup’ distribution D, the regularizer augments a minibatch of N training examples with N random points, then samples random interpolations of random pairs of points from the augmented minibatch. The authors hypothesize that performing mixup applies monotonicity to parts of the space that are disregarded if one focuses only on either observed data or random draws from uninformed choices of distributions such as the uniform.
Results
The authors first test their hypotheses on synthetic data manifolds with a covariate shift between the training/validation data and test data. The results show that applying the monotonicity regularizer to the mixup distribution enforces monotonicity on both the test data and random points, whereas applying the regularizer to the training data or at random is effective for one condition at most. In addition, the results suggest that when scaling to high dimensions, the covariate shift weakens the effect of training-set enforcement but not of mixup enforcement.
| | M | / D | 20/100 | 40/200 | 80/400 | 100/500 | ||||
|---|---|---|---|---|---|---|---|---|
| ρrandom | ρtest | ρrandom | ρtest | ρrandom | ρtest | ρrandom | ρtest | |
| Non-mon. | 99.90% | 99.99% | 97.92% | 94.96% | 98.47% | 96.56% | 93.98% | 90.01% |
| Ωrandom | 0.00% | 3.49% | 0.00% | 4.62% | 0.01% | 11.36% | 0.02% | 19.90% |
| Ωtrain | 1.30% | 0.36% | 4.00% | 0.58% | 9.67% | 0.25% | 9.25% | 5.57% |
| Ωmixup | 0.00% | 0.35% | 0.00% | 0.44% | 0.00% | 0.26% | 0.00% | 0.42% |
The results generalize to real datasets, where mixup regularization archives the best monotonicity under every evaluation condition. The authors additionally observe that successfully enforcing monotonicity has no effect on prediction performance, suggesting that monotonic predictors are viable as predictors:
| Non-mon. | Ωrandom | Ωtrain | Ωmixup | |
|---|---|---|---|---|
| ValidationRMSE | 0.213±0.000 | 0.223±0.002 | 0.222±0.002 | 0.235±0.001 |
| Test RMSE | 0.221±0.001 | 0.230±0.001 | 0.229±0.002 | 0.228±0.001 |
| ρrandom | 99.11%±1.70% | 0.00%±0.00% | 14.47%±7.55% | 0.00%±0.00% |
| ρtrain | 100.00%±0.00% | 7.23%±7.76% | 0.01%±0.01% | 0.00%±0.00% |
| ρtest | 100.00%±0.00% | 6.94%±7.43% | 0.04%±0.03% | 0.00%±0.00% |
The authors note that the mixup strategy introduces no computational overhead over the existing strategies, and is therefore strictly preferable. They propose that in future work the mixup strategy could be used to improve interpretability in complex neural network models, by enforcing homogeneity between a network’s outputs and a subset of its high-level representations.
News
Empowering and engaging: RBC Borealis and the Women in Machine Learning (WiML) Workshop at NeurIPS Conference
News