
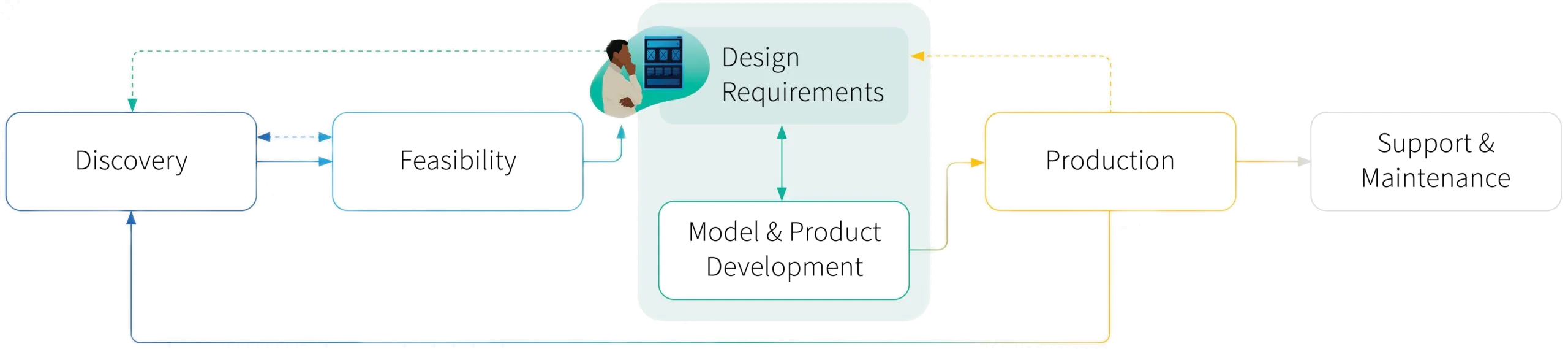
This is part 5 in our Field Guide to Machine Learning Product Development: What Product Managers Need to Know series. Learn about how to manage data throughout the machine learning product lifecycle, read up on the Discovery phase here and Feasibility phase here, and stay tuned for more deep dives into the six main stages of the machine learning PM process, with the Design and Requirments phase below.
A good user experience (UX) has always been at the heart of successful products. Ensuring you understand how users will engage with your product – their needs, problems and experiences – has always been key to good product design.
Traditionally, that meant doing lots of primary and secondary research. But with machine learning (ML), that approach is no longer fit-for-purpose. Instead, we need to acknowledge that our users are extremely dynamic – research can only tell us so much.
I believe that – in a machine learning context – great UX is created by watching users in action. That means getting something in front of your user as quickly as possible. And that, in turn, is about speed of development.
That is why, in this blog, I will share a framework and scoring system that I use to think about that intersection between UX and ML solution fit, with a clear prioritization on rapid prototype development, getting in front of your user and creating a great experience.

The right mindset
In previous blog posts, my colleagues have explored the nuances of machine learning in the discovery and the feasibility stages of the product development lifecycle. The design requirements stage is an extension of these initial phases. The goal is to cultivate a deep understanding of our end-users’ problems and determine if a machine learning solution is the right fit.
It’s not always easy – particularly when you rely on primary and secondary research – to ascertain what your users’ needs and problems will be. So, instead, the mindset should be around understanding how best to learn about your users in the fastest way possible. For some, that may mean developing quick and dirty prototypes of your application. Or it may mean thinking about possible outcomes that users may experience when facing a given context.
Ultimately, the design stage is about setting your team up to iterate, learn and incorporate. And that raises some key questions for the product manager: What are our users’ problems? Is machine learning the appropriate solution? What are the prediction trade-offs?

Understanding our users
As with any technology we build, our goal is to solve a user’s problem. To do that, we need to develop a fundamental understanding of the user, their needs and motivations, and the context surrounding the problem. The insights we uncover will start to form the foundation of any solution we create. Depending on the intersection between the human problem and the advantages ML can provide, we can then form an opinion on whether an ML solution is the right fit.
There are numerous resources on the topic – I am partial to methods by IDEO and UX Collective, for example. But based on my experience, here are four questions you can use to help kick-start your user research. It is not an exhaustive list. And it should be continuously iterated; throughout the product development process, you will learn more about your users which, in turn, will change the way you think and build for them.
- Given the same parameters, how confident would a human be if asked to make the prediction(s) liste
- A good solution drives _____ outcomes for users as measured by _____.
- A good solution solves our user’s problem of _____.
- A good solution makes our user feel _____.
- A good solution is used in the appropriate context, that context is _____.

Assessing the ML fit
Now that we understand our users’ problems, we can begin to explore whether machine learning is the appropriate solution for solving them.
That may sound like a daunting task; machine learning can be used to do many things from personalization and recommendations through to natural language understanding and outlier detection. But, at the root of all of those solutions is a prediction. Whether it is predicting what a user will like based on who they are, or predicting what text to display when prompted by a user, it all comes down to predictions (for more on the economics of ML, check out Prediction Machines by Agrawal, Avi, and Gans).
Therefore, our primary question at this stage should be:
- Our user’s problem is _____, and we believe we can solve it by predicting ____ (list options).
That’s a great start – at this point we understand the user’s problems and we have an idea of what we might want to predict in order to help solve those problems. Unfortunately, that does not necessarily mean we have a clear-cut ML problem. Machine learning is more nuanced. There are a range of other considerations that could shift the decision towards a more traditional solution set. More questions will need to be asked. And in the following sections, I’ll explore these nuances and help develop some more questions to help you decide if ML is the right fit.

Establishing a human baseline
In 2016, Andrew Ng argued that “if a typical person can do a mental task with less than one second of thought, we can probably automate it using AI either now or in the near future.” Ng’s adage reminds us that it’s important to develop a human baseline for performance on the task you are looking to solve.
A human baseline serves as both a feasibility test and as a method for understanding requirements moving forward. Just as importantly, it sets an expectation for what metrics your ML model would require in order to be considered ‘good enough’.
Consider, for example, an application that aims to label dog breeds from photos. And let’s assume humans have a moderately high baseline accuracy of 60%. That baseline can then be written into the project as a requirement which, in turn, will help solidify the approximate timelines for the project. The baseline can be used to indicate if the model is over-fitting or under-fitting – something that can often be difficult to assess.
Contrast that example against an ML application that attempts to properly value a piece of art. Since the price would likely vary widely depending on who you ask, establishing a human baseline would be extraordinarily difficult. Knowing this, a PM may decide to re-think the solution or re-phase the user problem.
Ultimately, we should assume that – from a user’s perspective – the human baseline represents the absolute minimum performance the application must achieve before release. If people can identify a dog accurately 60% of the time, they won’t want to use a machine that only gets it right 50% of the time.
The new question we need to add, therefore, is:
- Given the same parameters, how confident would a human be if asked to make the prediction(s) listed above?

Evaluating the experience of uncertainty
Throughout this Field Guide article series, a common theme has been the uncertainty that machine learning applications create. ML is all about predictions. And anyone who makes predictions knows that sometimes they are going to be wrong. What is important is to understand how these mistakes will impact your end-user’s experience. In ML terms, that means deciding with your team the right balance between the recall and precision of the application.
To start, you may want to host a brainstorming session to create a confusion matrix with your cross-disciplinary team. This will help them understand the realm of possible outcomes a user may experience. It will also allow the team to reflect on not only what the prediction will be, but also how that prediction might affect the end-user’s experience. Your team can then use this information to optimize for the appropriate user outcomes which, in turn, will help solidify your design requirements.

Let’s say that we are designing a news recommender system where a false negative leads to recommendations users will not engage with. The impact on the user will be a negative experience which, over time, would be detrimental to the application as users start to disengage entirely. Knowing this, a decision can be made to optimize for false negatives.
This may lead to entirely new conversations about how the team can achieve the desired metric, perhaps through data labelling, application design, system design or other improvements.
With this in mind, the next question we need to add is:
- For the product to be successful, what is the cost of an error from the user’s perspective?
Considering the need for generalization
One of the great things about machine learning systems is that they evolve as our users’ mental models change over time. Knowing and planning how a system may change over time can be incredibly important as applications that are created to generalize their predictions will require more data than those created for a specific use case.
In our earlier example where users were identifying breeds of dogs, the data sample will be fairly contained. If the task were to be generalized to identify all animals of all types in photos, an entirely new set of data requirements will be needed (one that contains photos of all target animals we want to classify).
While these more expansive data sets can often be tricky to obtain, it is possible to design interaction patterns that make it easy (even rewarding) for users to give feedback to the system. Even so, PMs will find that the more generalized the requirements the more complex it is to build an application that not only outperforms a human baseline, but also controls for the experience of uncertainty.
The final question we need to add, therefore, is:
- For the product to be successful, will the predictions have to generalize to many domains?

Putting it all together
So, let’s quantify all of this for you. Here are the four questions I believe PMs should be asking themselves as they consider the ML design stage, aligned to a scoring system.
- Our user’s problem is _____, and we believe we can solve it by predicting ____ (list options).
Now for each of these options, answer the following questions and assign the appropriate score:
- Given the same parameters, how confident would a human be if asked to make the prediction(s) listed above (1- low, 3 -high)
- For the product to be successful, what is the cost of an error from the user’s perspective? (1- low, 3- high) (reverse coded)
- For the product to be successful, will the predictions have to generalize to many domains? (1 — low, 3- high) (reverse coded)
The prediction with the lowest score will likely be the easiest to tackle and will probably make the best candidate to quickly prototype and learn from.
History teaches us that the ability to iterate and learn is the primary driver of successful products. And in the ML world, that means iterating rapidly, assessing user needs and problems, understanding the value that ML could deliver and properly identifying the downstream risks and challenges. It also means assessing whether ML would be a good fit.
Ultimately, the goal is to start with your users’ needs and experience in mind and then quickly move into identifying what you need in order to rapidly test and learn. To be sure, adding machine learning to your projects can increase the layers of complexity in your application. I hope this article helps you cut through some of that complexity and hasten your product development cycle.
News
The (never-ending) production stage
News
Support & Maintenance … without the ‘hand over’
News
Encouraging diversity in AI: Why RBC Borealis and RBC are supporting the AI4Good Lab
We're Hiring!
We are scientists, engineers and product experts dedicated to forging new frontiers of AI in finance, backed by RBC. The team is growing! Please view the open roles, including Product Manager, Business Development Lead, Research Engineer - Data Systems, and more.
View all jobs