
Our team had a busy and exciting time at the 2024 Conference on Neural Information Processing Systems (NeurIPS) in Vancouver last week. RBC Borealis was proud to attend NeurIPS 2024 as a silver sponsor and to have three main conference papers and six workshop papers accepted.
With over 4,000 papers presented, NeurIPS showcased the latest advancements in Artifical Intelligence (AI) and Machine Learning (ML). Many of our team members immersed themselves in the conference, attending sessions on a wide range of research topics, including Large Language Models (LLMs), Time Series, Generalization and Optimization, and more. If you were at NeurIPS, you likely experienced firsthand how overwhelming the sheer volume of content can be—it’s tough to decide what sessions to prioritize when they all sound compelling. And if you weren’t able to attend, we don’t want you to miss out on the key insights. That is why we’ve curated a catalogue of content that our team found particularly noteworthy.
We’re excited to share these recommendations with you and hope you find the content as interesting as we do!
NeurIPS 2024 Tutorials
Beyond Decoding: Meta-Generation Algorithms for Large Language Models
Sean Welleck, Amanda Bertsch, Matthew Finlayson, Alex Xie, Graham Neubig, Konstantin Golobokov, Hailey Schoelkopf, Ilia Kulikov, Zaid Harchaoui
This tutorial presents past and present classes of generation algorithms for generating text from autoregressive LLMs, ranging from greedy decoding to sophisticated meta-generation algorithms used to power compound AI systems. Authors place a special emphasis on techniques for making these algorithms efficient, both in terms of token costs and generation speed. The tutorial unifies perspectives from three research communities: traditional natural language processing, modern LLMs, and machine learning systems. In turn, they aim to make attendees aware of (meta-)generation algorithms as a promising direction for improving quality, increasing diversity, and enabling resource-constrained research on LLMs.
Opening the Language Model Pipeline
Kyle Lo, Akshita Bhagia, Nathan Lambert
This tutorial provides a detailed walkthrough of the language model development pipeline, including pre-training data, model architecture and training, adaptation (e.g., instruction tuning, RLHF). For each of these development stages, authors provide examples using open software and data, and discuss tips, tricks, pitfalls, and otherwise often inaccessible details about the full language model pipeline that they’ve uncovered in their own efforts to develop open models. Authors have opted not to have the optional panel given the extensive technical details and examples we need to include to cover this topic exhaustively.
Evaluating Large Language Models – Principles, Approaches, and Applications
Bo Li, Irina Sigler, Yuan (Emily) Xue
This tutorial delves into the critical and complex domain of evaluating large language models (LLMs), focusing on the unique challenges presented when assessing generative outputs. Despite the difficulty in assigning precise quality scores to such outputs, our tutorial emphasizes the necessity of rigorous evaluation throughout the development process of LLMs. This tutorial provides an extensive presentation of evaluation scopes, from task-specific metrics to broader performance indicators such as safety and fairness. Participants will be introduced to a range of methodological approaches, including both computation and model-based assessments. The session includes hands-on coding demonstrations, providing the tools and knowledge needed to refine model selection, prompt engineering, and inference configurations. By the end of this tutorial, attendees will gain a comprehensive understanding of LLM evaluation frameworks, contributing to more informed decision-making and ensuring the responsible deployment of these models in real-world applications.
Experimental Design and Analysis for AI Researchers
Katherine Hermann, Jennifer Hu, Michael Mozer
This tutorial discusses core techniques used in the experimental sciences (e.g., medicine and psychology) that are too often sidestepped by AI researchers. Topics include: classical statistical inference, hypothesis testing, one-way and multi-factor ANOVA, within-and between-subjects designs, planned vs. post-hoc contrasts, visualization of outcomes and uncertainty, and modern standards of experimental practice. Authors then focus on two topics of particular interest to AI researchers: (1) human evaluations of foundation models (LLMs, MLMs), e.g., in domains like intelligent tutoring; and (2) psycholinguistic explorations of foundation models, in which models are used as subjects of behavioural studies in order to reverse engineer their operation, just as psychologists and psycholinguists have done with human participants over the past century.
NeurIPS 2024 Poster Sessions
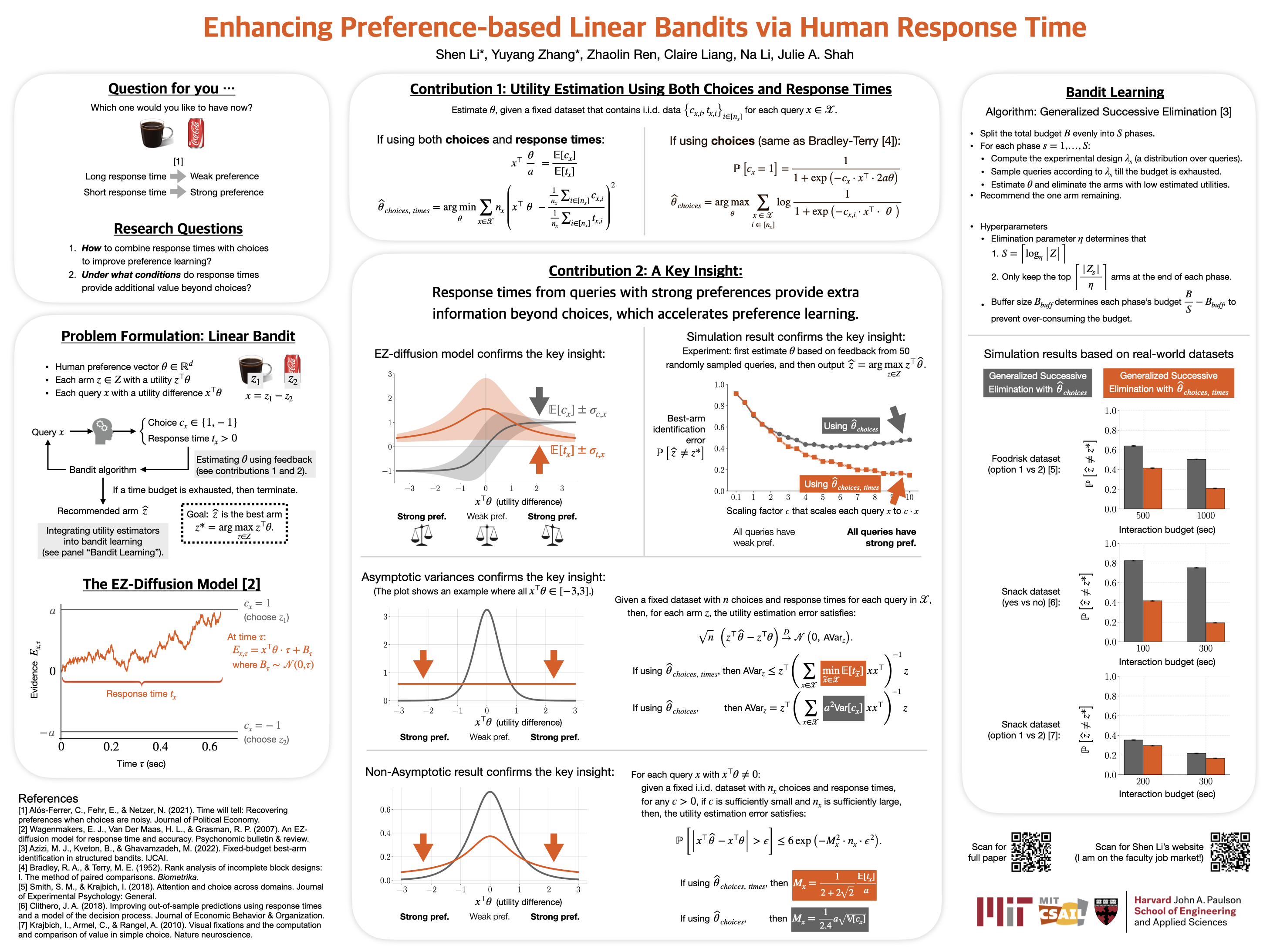
Enhancing Preference-based Linear Bandits via Human Response Time
Shen Li, Yuyang Zhang, Zhaolin Ren, Claire Liang, Na Li, Julie A. Shah
This work introduces a computationally efficient method based on the EZ-diffusion model, combining choices and response times to estimate the underlying human utility function. Theoretical and empirical comparisons with traditional choice-only estimators show that for queries where humans have strong preferences (i.e., “easy” queries), response times provide valuable complementary information and enhance utility estimates. Authors integrate this estimator into preference-based linear bandits for fixed-budget best-arm identification. Simulations on three real-world datasets demonstrate that incorporating response times significantly accelerates preference learning.
{kind=link}
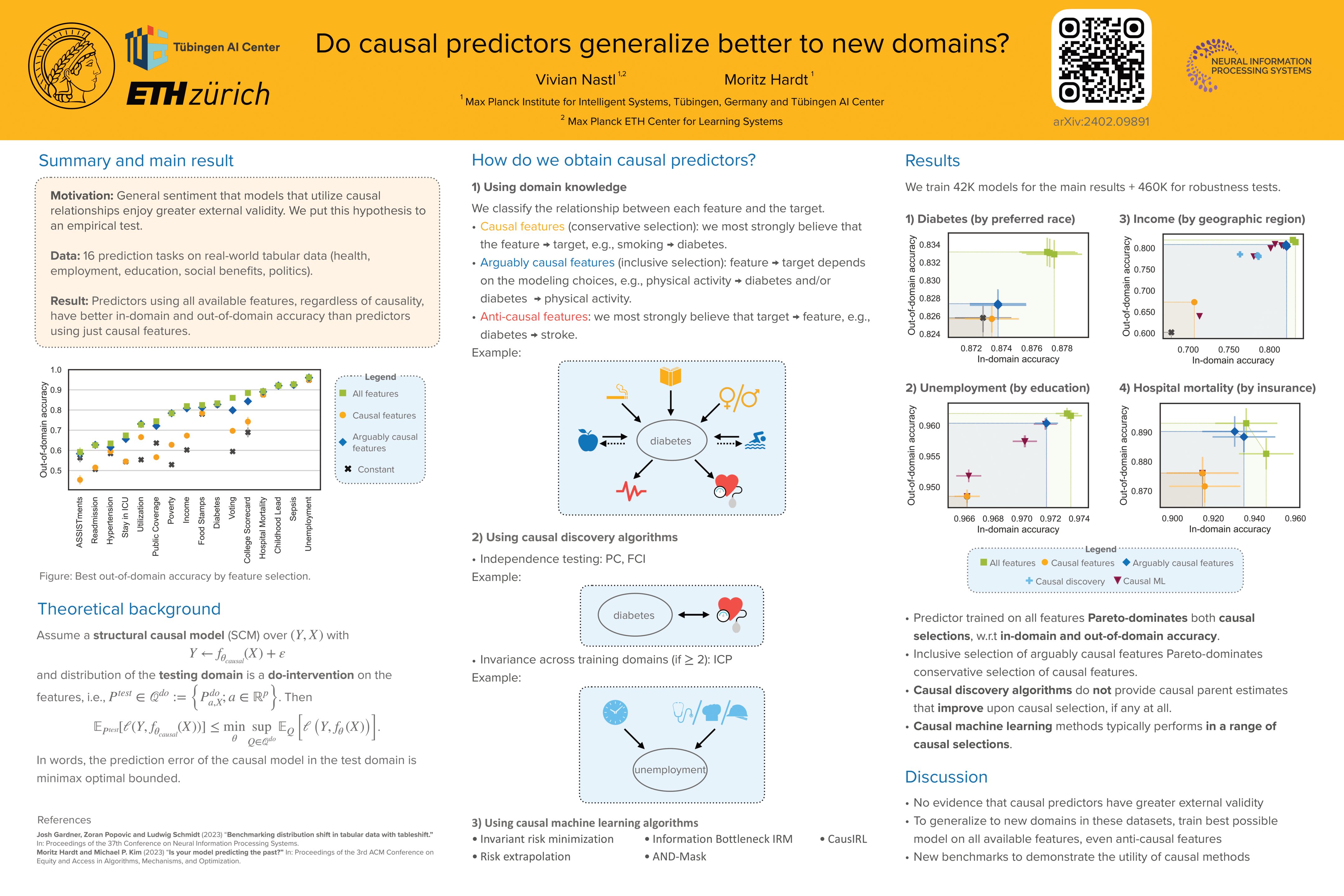
Do causal predictors generalize better to new domains?
Vivian Y. Nastl, Moritz Hardt
In this work, authors study how well machine learning models trained on causal features generalize across domains. They consider 16 prediction tasks on tabular datasets covering applications in health, employment, education, social benefits, and politics. Each dataset comes with multiple domains, allowing us to test how well a model trained in one domain performs in another. For each prediction task, we select features that have a causal influence on the target of prediction. The goal is to test the hypothesis that models trained on causal features generalize better across domains. Without exception, they find that predictors using all available features, regardless of causality, have better in-domain and out-of-domain accuracy than predictors using causal features. Moreover, even the absolute drop in accuracy from one domain to the other is no better for causal predictors than for models that use all features. In addition, they show that recent causal machine learning methods for domain generalization do not perform better in our evaluation than standard predictors trained on the set of causal features. Likewise, causal discovery algorithms either fail to run or select causal variables that perform no better than their selection. Extensive robustness checks confirm that their findings are stable under variable misclassification.
{kind=link}
Keeping LLMs Aligned After Fine-tuning: The Crucial Role of Prompt Templates
Kaifeng Lyu, Haoyu Zhao, Xinran Gu, Dingli Yu, Anirudh Goyal, Sanjeev Arora
This paper is about methods and best practices to mitigate such loss of alignment. Authors focus on the setting where a public model is fine-tuned before serving users for specific usage, where the model should improve on the downstream task while maintaining alignment. Through extensive experiments on several chat models (Meta’s Llama 2-Chat, Mistral AI’s Mistral 7B Instruct v0.2, and OpenAI’s GPT-3.5 Turbo), this paper uncovers that the prompt templates used during fine-tuning and inference play a crucial role in preserving safety alignment, and proposes the “Pure Tuning, Safe Testing” (PTST) strategy — fine-tune models without a safety prompt, but include it at test time. This seemingly counterintuitive strategy incorporates an intended distribution shift to encourage alignment preservation. Fine-tuning experiments on GSM8K, ChatDoctor, and OpenOrca show that PTST significantly reduces the rise of unsafe behaviors.
The Road Less Scheduled
Aaron Defazio, Xingyu Yang, Ahmed Khaled, Konstantin Mishchenko, Harsh Mehta, Ashok Cutkosky
Existing learning rate schedules that do not require specification of the optimization stopping step T are greatly out-performed by learning rate schedules that depend on T. Authors propose an approach that avoids the need for this stopping time by eschewing the use of schedules entirely, while exhibiting state-of-the-art performance compared to schedules across a wide family of problems ranging from convex problems to large-scale deep learning problems. Their Schedule-Free approach introduces no additional hyper-parameters over standard optimizers with momentum. Their method is a direct consequence of a new theory we develop that unifies scheduling and iterate averaging.
The PRISM Alignment Dataset: What Participatory, Representative and Individualised Human Feedback Reveals About the Subjective and Multicultural Alignment of Large Language Models
Hannah Rose Kirk, Alexander Whitefield, Paul Rottger, Andrew M. Bean, Katerina Margatina, Rafael Mosquera-Gomez, Juan Ciro, Max Bartolo, Adina Williams, He He, Bertie Vidgen, Scott A. Hale
This work introduces PRISM, a dataset that maps the socio-demographics and stated preferences of 1,500 diverse participants from 75 countries, to their contextual preferences and fine-grained feedback in 8,011 live conversations with 21 LLMs. With PRISM, authors contribute (i) wider geographic and demographic participation in feedback; (ii) census-representative samples for two countries (UK, US); and (iii) individualised ratings that link to detailed participant profiles, permitting personalisation and attribution of sample artefacts. They target subjective and multicultural perspectives on value-laden and controversial issues, where they expect interpersonal and cross-cultural disagreement. Authors use PRISM in three case studies to demonstrate the need for careful consideration of which humans provide what alignment data.
BABILong: Testing the Limits of LLMs with Long Context Reasoning-in-a-Haystack
Yury Kuratov, Aydar Bulatov, Petr Anokhin, Ivan Rodkin, Dmitry Sorokin, Artyom Sorokin, Mikhail Burtsev
This work introduces the BABILong benchmark, designed to test language models’ ability to reason across facts distributed in extremely long documents. BABILong includes a diverse set of 20 reasoning tasks, including fact chaining, simple induction, deduction, counting, and handling lists/sets. These tasks are challenging on their own, and even more demanding when the required facts are scattered across long natural text. Evaluations show that popular LLMs effectively utilize only 10-20% of the context and their performance declines sharply with increased reasoning complexity. Among alternatives to in-context reasoning, Retrieval-Augmented Generation methods achieve a modest 60% accuracy on single-fact question answering, independent of context length. Among context extension methods, the highest performance is demonstrated by recurrent memory transformers after fine-tuning, enabling the processing of lengths up to 50 million tokens. The BABILong benchmark is extendable to any length to support the evaluation of new upcoming models with increased capabilities, and we provide splits up to 10 million token lengths.
RBC Borealis at NeurIPS 2024!
Explore our accepted papers and discover how we’re transforming finance through world-class AI.
Learn more