
Our AI needs to drive responsible actions and decision-making in rapidly changing environments. With the Causmos program at RBC Borealis, we aim to build machine intelligence beyond predictive ML for financial services by conducting research in areas such as causality, out-of-distribution (OOD) generalization, reasoning and planning in large language models (LLMs) and reinforcement learning.
The Tale of Three Actors



What do a motel owner in a small town near Banff, a recommendation system and future autonomous agents (perhaps powered by LLMs) for a Mars colonization have in common? The answer: they all need to make decisions and take actions directly or via mediation that affect the real world. These actions require them to have a model of their respective domains beyond correlation.
The motel owner would know that despite the correlation of high price with low vacancy, it is due to confounding by the higher demand in peak seasons. Raising the price will not help fill rooms generally. Training a recommendation system must account for selection bias in the data introduced by any previous system’s policy and also learn from the outcomes of its own doings. Finally, the LLM-powered autonomous agent acting in the new world must be able to plan its actions beyond scenarios similar to existing observed or simulated data.
Likewise, in the financial services sector, ensuring our AI systems drive the right decisions for our clients amidst complex, evolving landscapes is crucial. Even when human oversight is integrated as a safety net in mission-critical tasks, AI influences real-world outcomes through human mediation. The Causmos research program at RBC Borealis is dedicated to advancing machine intelligence beyond predictive ML in this domain. Our focus encompasses different facets and approaches to model actions and their consequences, including reinforcement learning, planning, causal inference, and experimental design. Additionally, we delve into crucial related areas to ensure the safety of actions, such as reasoning, interpretability, adversarial robustness, and out-of-distribution (OOD) generalization. For some of our relevant publications, please see the list at the end.
Reinforcement Learning, Planning and Causal Inference
One way to comparatively understand the different approaches to intelligence for actions is through the lens of how much-structured knowledge of the world is used and where the knowledge is coming from.
The simplest and most classical framework for learning to act is arguably the bandits. This framework captures the essence of learning about the environment through exploration and using that knowledge to maximize the effectiveness of exploitation. The hallmark of bandits is their minimal reliance on prior or learned knowledge. Indeed, Bandits assume a stateless environment, and in the multi-armed bandit setting, the only information learned is some (partial) knowledge of the reward distribution of different levers. Extending the same core ideas to sequential decision-making yields model-free reinforcement learning (RL). Through essentially the same trial-and-error, model-free RL algorithms decipher the “goodness” of states without explicitly modelling the mechanisms of the environment. Bandits and model-free RL are particularly suitable when the feedback loop is quick and the cost of exploration is relatively low. This characteristic renders them apt for scenarios where the task at hand can be learned through direct interaction with the environment, eschewing the necessity for an elaborate world model. Most Internet platforms use some kind of bandit or model-free RL for their advertising or recommendation platforms (for example, Netflix’s use of multi-arm bandit and Google’s use of RL in YouTube recommendations). In the world of financial services, RBC Borealis and RBC Capital Market built a highly successful RL-based trading agent for market-making called Aiden.
The downside of this model-free approach is that solving hard problems with- out structured knowledge of the world would necessitate lots of data through trial-and-error exploration. This high sample complexity quickly becomes infeasible in settings where feedback from the environment is sparse, delayed, costly or if certain exploration can be unsafe. In financial services, an example is the pricing of products, where outcomes require human negotiation to play out. This is where planning shines if a good domain model is available. In problems where the states are discrete and fully observed, the transition dynamics are deterministic; planning is equivalent to finding a path in a graph that traverses from the initial state node to the goal state node. In continuous problems, this is akin to trajectory optimization and control. There is little need for trial and error exploration while dangerous or desirable states can be avoided. There are variants of the problem with relaxed requirements and corresponding planning algorithms, but generally, a complete and accurate domain model is still needed, even if it is probabilistic. However, engineering robust domain models or simulators is challenging and hard to scale with the complexity of the domain. As we transition to open-domain problems, the feasibility of such an engineered domain model wanes, accentuating the importance of learning a competent world model. There are proposals to learn the domain models as part of the RL agent, giving rise to model-based RL. Despite its appealing premise and its introduction quite some time ago (for instance, the renowned Dyna architecture (Sutton, 1991)), model-based RL has yet to achieve widespread success.
Outside the RL and planning literature, causal inference represents an alternative to studying the effect of actions, i.e. treatments in this context. Tools of causal inference leverage domain knowledge and limited data to separate causation from mere correlation. Through meticulously designed experiments or observational studies, it endeavours to infer how the world might react to various treatments. In causal inference, there is a much stronger reliance on domain knowledge, usually imparted by humans. Still, it can be learned from data via causal discovery, given some human-supplied assumptions. Unlike the model-free RL, causal inference hinges on a more structured understanding of the domain. And unlike planning, causal inference does not require a complete model of the domain but only what is necessary to complement the data to answer specific causal queries. On the one hand, this allows for more informed actions with less data; conversely, CI requires more human design effort and is typically less autonomous. Finally, the formulation in CI is not centred around the notion of reward but can be combined with a decision framework for optimizing actions. For example, in causal bandit learning, inferring some structural information about the bandit’s arms makes bandit learning probably more efficient. More generally, there is an emergent field of causal reinforcement learning. Finally, there is an interesting new class of model called Generative Flow Networks (GFlowNets) (Bengio et al., 2021), which allows neural networks to learn from rewards like in RL to model graph structures like causal graphs.
In summary, bandits and model-free RL perform well in domains with a high volume of rapid feedback, and the cost associated with exploration is minimal. However, in certain areas of financial services, regulatory constraints or other limitations often result in actions that yield delayed or sparse feedback, making exploration costly or restricted. In such scenarios, it is unsurprising that having a deeper understanding of the domain reduces the need for trial-and-error exploitation. We have achieved some success in building systems capable of making intelligent decisions despite encountering delayed or sparse feedback, which we hope to reveal and delve deeper into in the future. Figure 2 summarizes the comparisons of the different types of technologies for intelligent actions.
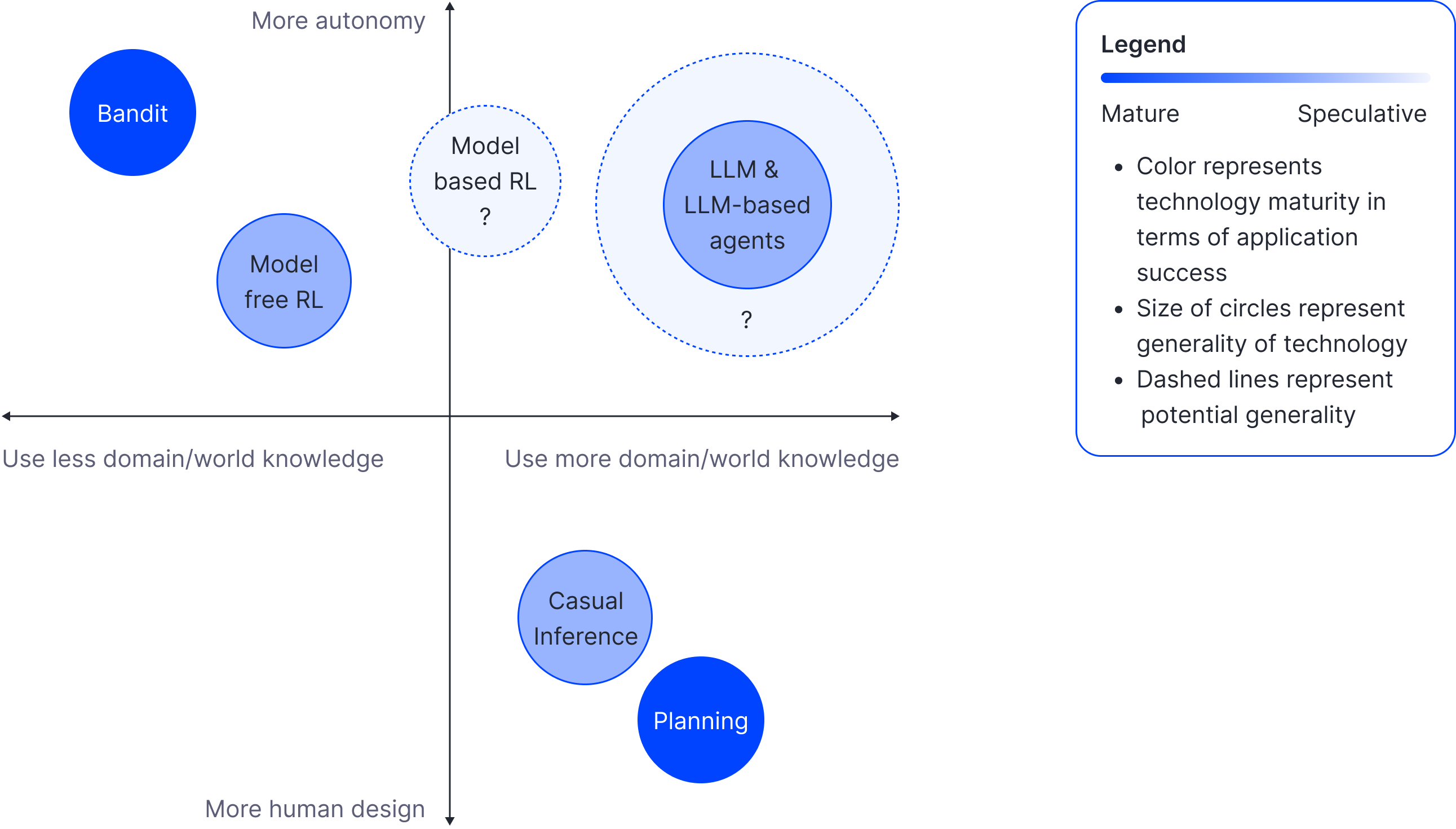
Figure 2: Comparing the different frameworks for intelligent actions on four dimensions: (1) the amount of domain/world knowledge used (x-axis); (2) the degree of autonomy versus human design required for building the system (y-axis); (3) the maturity of the technology (colour) and (4) the generality or potential generality of the technology (size). Before LLMs, among methods that have found some commercial successes, unsurprisingly, there is a negative correlation between the amount of domain knowledge the method requires and the degree of autonomy. These technologies are all limited in their generality. Bandit and model-free RL are not sample efficient enough to be applicable in scenarios with slow or sparse feedback. Traditionally, both causal inference and planning require too much human design effort in complex problems. So, the solution would not be commercially viable unless the problem is extremely valuable. Model-based RL has promised to break this pattern, but the technology is not yet working well.
LLMs and Autonomous Agents
With recent advancements, Large Language Models (LLMs) can now seamlessly leverage an extensive reservoir of knowledge and skills. This has ignited a new-found hope that LLM-based autonomous agents can formulate plans to tackle intricate problems, utilizing their pre-existing knowledge acquired through pre-training or acquiring new skills on the fly through in-context learning in novel situations. Furthermore, using text as the unified communication interface, AI agents fulfilling human requests can formulate their own subgoals, plan accordingly, and perform various tasks toward achieving the human-specified goal, all by composing calls to LLMs and external tools. Or so it seems.
Underneath the excitement generated by ambitious demos and rapid progress from academia, industry and hobbyists alike, there lurks fundamental challenges. We see at least three core issues as of today:
- restrictions from LLMs’ communication bandwidth;
- inherent limitations in LLMs’ reasoning and planning ability;
- misalignment between LLMs’ representation of knowledge and states with that of humans or reality.
For the first issue, LLM agents must retrieve external data, read and write to external memory, and use tools. All of these require them to communicate via a text interface with a finite context window. But both the length of the messages and the information density per unit length of the message are limited. Additionally, many advanced approaches for enhancing reasoning and planning involve layers of LLMs calls, such as Tree-of-Thought (Yao et al., 2023a), Graph-of-Thought (Besta et al., 2023), ReAct (Yao et al., 2023b), Reflexion (Shinn et al., 2023). Therefore, the limitation in communication bandwidth makes it hard for the agent to maintain consistency of its reasoning and actions without losing local nuances or global context when performing complex tasks. With the rapid progress in scaling the context window size, this is likely the easiest problem to resolve. At the time of writing, GPT-4-Turbo has a 32K token context size. However, it remains to see whether the long but finite communication bandwidth is sufficient when LLM agents need to tackle complex real-world challenges that could require a variable number of steps.
For the second issue, several studies have shown that even the most powerful LLMs can fail to extrapolate to longer tasks involving composing or repeating the same simple steps, for example, in arithmetic (Dziri et al., 2023). While arithmetic can be solved by giving LLMs access to a calculator (Schick et al., 2023), in the context of planning complex actions, the same underlying issue means LLMs can fail to track state dynamics properly. Understanding the root cause of such limitation, whether it is the Transformer architecture, the auto-regressive nature of training and inference, the data, or something else, is an open problem and active area of research.
Finally, despite efforts to align LLMs for safety and usefulness for chat, such alignment is just guard-railing LLMs’ interaction with humans. It may not correct fundamental mistakes in how its representation deviates from the true causality of the world or the representation of humans. For example, Zeˇcevi ́c et al. (2023) showed theoretically and Jin et al. (2023) empirically that today’s LLMs do not understand causality. The deviation from causal reality means that LLMs will learn shortcuts and spurious correlations that fail in out-of-distribution settings, as shown for mathematical reasoning by Stolfo et al. (2023). Deviation from humans’ representation means they are prone to adversarial attacks (Zou et al., 2023), a failure mode that humans do not fall prey to.
Closing Remarks
From the motel owner’s intuitive grasp of their trade to the recommendation systems that permeate the digital realm to the awe-inspiring prospects of autonomous Martian colonization, one simple truth remains evident: intelligent actions need world knowledge. On the other hand, it is fair to ask: does knowledge need action? In other words, can robust world knowledge be acquired through passive observations alone? Or would it be fundamentally flawed without training on the outcomes of one’s own actions?
In restricted domains, fitting curves with the correct hypothesis class could potentially yield perfect OOD generalization. In the open domain, with the success of LLMs pre-trained on massive corpora, many people believe that scaling, perhaps with multi-modal data, is “all you need” for AI, while others think there are fundamental flaws in the current approach. Time and more research will tell, but one thing is sure: answers to questions like this have profound im- plications for both the long-term roadmap of the AI community and immediate applications that demand robustness, such as in financial services.
Appendix: Selected Relevant Borealis Work
RL & Planning
-
Robust Risk-Sensitive Reinforcement Learning Agents for Trading Markets
Robust Risk-Sensitive Reinforcement Learning Agents for Trading Markets
*Y. Gao, K. Y. C. Lui, and P. Hernandez-Leal. International Conference on Machine Learning Workshop (ICML), 2021
-
Maximum Entropy Monte-Carlo Planning
Maximum Entropy Monte-Carlo Planning
C. Xiao, R. Huang, J. Mei, D. Schuurmans, and M. Müller. Conference on Neural Information Processing Systems (NeurIPS), 2019
-
On Principled Entropy Exploration in Policy Optimization
On Principled Entropy Exploration in Policy Optimization
*J. Mei, *C. Xiao, R. Huang, D. Schuurmans, and M. Müller. International Joint Conference on Artificial Intelligence (IJCAI), 2019
-
Action Guidance with MCTS for Deep Reinforcement Learning
Action Guidance with MCTS for Deep Reinforcement Learning
*B. Kartal, *P. Hernandez-Leal, and M. E. Taylor. AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment (AIIDE), 2019
-
Using Monte Carlo Tree Search as a Demonstrator within Asynchronous Deep RL
Using Monte Carlo Tree Search as a Demonstrator within Asynchronous Deep RL
B. Kartal, P. Hernandez-Leal, and M. E. Taylor. Association for the Advancement of Artificial Intelligence Workshop on Reinforcement Learning in Games (AAAI-19), 2018
-
Meet Aiden, an AI-powered electronic trading platform
Meet Aiden, an AI-powered electronic trading platform
Interpretability and disentanglement
-
TURING: an Accurate and Interpretable Multi-Hypothesis Cross-Domain Natural Language Database Interface
TURING: an Accurate and Interpretable Multi-Hypothesis Cross-Domain Natural Language Database Interface
*P. Xu, *W. Zi, H. Shahidi, A. Kádár, K. Tang, W. Yang, J. Ateeq, H. Barot, M. Alon, and Y. Cao. Association for Computational Linguistics (ACL) & International Joint Conference on Natural Language Processing (IJCNLP), 2021
-
On Variational Learning of Controllable Representations for Text without Supervision
On Variational Learning of Controllable Representations for Text without Supervision
P. Xu, J. Chi Kit Cheung, and Y. Cao. International Conference on Machine Learning (ICML), 2020
-
Polarized-VAE: Proximity Based Disentangled Representation Learning for Text Generation
Polarized-VAE: Proximity Based Disentangled Representation Learning for Text Generation
V. Balasubramanian, I. Kobyzev, H. Bahuleyan, and O. Vechtomova. Conference of the European Chapter of the Association for Computational Linguistics (EACL), 2021
Reasoning and OOD generalization
-
Optimizing Deeper Transformers on Small Datasets
Optimizing Deeper Transformers on Small Datasets
P. Xu, D. Kumar, W. Yang, W. Zi, K. Tang, C. Huang, J. Chi Kit Cheung, S. Prince, and Y. Cao. Association for Computational Linguistics (ACL) & International Joint Conference on Natural Language Processing (IJCNLP), 2021
-
Object Grounding via Iterative Context Reasoning
Object Grounding via Iterative Context Reasoning
L. Chen, M. Zhai, J. He, and G. Mori. International Conference on Computer Vision Workshop on Multi-Discipline Approach for Learning Concepts at IEEE International Conference on Computer Vision (ICCV), 2019
-
A Cross-Domain Transferable Neural Coherence Model
A Cross-Domain Transferable Neural Coherence Model
P. Xu, H. Saghir, J. Kang, L. Long, A. J. Bose, and Y. Cao. Association for Computational Linguistics (ACL), 2019
Adversarial learning and robustness
-
On the Sensitivity of Adversarial Robustness to Input Data Distributions
On the Sensitivity of Adversarial Robustness to Input Data Distributions
G. W. Ding, K. Y. C. Lui, T. Jin, L. Wang, and R. Huang. International Conference on Learning Representations (ICLR), 2019
-
Adversarial Contrastive Estimation
Adversarial Contrastive Estimation
*A. J. Bose, *H. Ling, and *Y. Cao. Association for Computational Linguistics (ACL), 2018
-
Max-Margin Adversarial Training: Direct Input Space Margin Maximization through Adversarial Training
Max-Margin Adversarial Training: Direct Input Space Margin Maximization through Adversarial Training
G. W. Ding, Y. Sharma, K. Lui, and R. Huang. International Conference on Learning Representations (ICLR), 2020
-
On the Effectiveness of Low Frequency Perturbations
On the Effectiveness of Low Frequency Perturbations
Y. Sharma, G. W. Ding, and M. Brubaker. International Joint Conference on Artificial Intelligence (IJCAI), 2019
References
Emmanuel Bengio, Moksh Jain, Maksym Korablyov, Doina Precup, and Yoshua Bengio. Flow network-based generative models for non-iterative diverse candidate generation. Advances in Neural Information Processing Systems, 34: 27381–27394, 2021.
Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Lukas Gi- aninazzi, Joanna Gajda, Tomasz Lehmann, Michal Podstawski, Hubert Niewiadomski, Piotr Nyczyk, and Torsten Hoefler. Graph of Thoughts: Solv- ing Elaborate Problems with Large Language Models, 2023.
Nouha Dziri, Ximing Lu, Melanie Sclar, Xiang Lorraine Li, Liwei Jiang, Bill Yuchen Lin, Sean Welleck, Peter West, Chandra Bhagavatula, Ronan Le Bras, Jena D. Hwang, Soumya Sanyal, Xiang Ren, Allyson Ettinger, Zaid Harchaoui, and Yejin Choi. Faith and fate: Limits of transformers on compo- sitionality. In the Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=Fkckkr3ya8.
Zhijing Jin, Jiarui Liu, Zhiheng Lyu, Spencer Poff, Mrinmaya Sachan, Rada Mihalcea, Mona Diab, and Bernhard Sch ̈olkopf. Can large language models infer causation from correlation?, 2023.
Timo Schick, Jane Dwivedi-Yu, Roberto Dess`ı, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. ArXiv, abs/2302.04761, 2023. URL https://api.semanticscholar.org/CorpusID:256697342.
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning, 2023.
Alessandro Stolfo, Zhijing Jin, Kumar Shridhar, Bernhard Schoelkopf, and Mrinmaya Sachan. A causal framework to quantify the robustness of mathematical reasoning with language models. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 545–561, Toronto, Canada, July 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.32. URL https: //aclanthology.org/2023.acl-long.32.
Richard S. Sutton. Dyna, an integrated architecture for learning, planning, and reacting. SIGART Bull., 2(4):160–163, jul 1991. ISSN 0163-5719. doi: 10.1145/122344.122377. URL https://doi.org/10.1145/122344.122377.
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of Thoughts: Deliberate problem solving with large language models, 2023a.
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. In International Conference on Learning Representations (ICLR), 2023b.
Matej Zeˇcevi ́c, Moritz Willig, Devendra Singh Dhami, and Kristian Kersting. Causal parrots: Large language models may talk causality but are not causal. Transactions on Machine Learning Research, 2023. ISSN 2835-8856. URL https://openreview.net/forum?id=tv46tCzs83.
Andy Zou, Zifan Wang, J. Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models, 2023.
Explore Causmos
The team’s commitment to creating real-world impact through scientific pursuit led to RBC Borealis establishing a set of challenging North Star research problems, such as Causmos: Machine Intelligence beyond Predictive ML.
Learn more