
This blog post is based on our paper accepted to International Conference on Learning Representations (ICLR) 2024. Please refer to the paper ConR: Contrastive Regularizer for Deep Imbalanced Regression for full details. Additionally, our code is publicly available here.
Imbalanced data distributions are common in real-world contexts, and they pose challenges for Deep Neural Networks to represent minority labels and prevent bias towards majority labels. There is a solid body of work on imbalanced learning for categorical label spaces. However, in regression tasks, the label space is continuous, potentially boundless and high-dimensional. Thus imbalanced classification methods struggle to effectively extend to regression tasks. On the other hand, the local and global correlations in the continuous label space offer valuable insights for modelling relationships in the feature space. In regression tasks, minority sample features collapse into the majority ones [2] and effective translation of label similarities to the feature space will penalize the bias toward majority samples.
Motivations
LDS and FDS [2] locally model these relationships using kernel smoothing in label and feature space respectively. RankSim [2] translates local and global label relationships from the label space to the feature space by penalizing the non-corresponding rankings of pairwise similarities in the label space and feature space. These methods are based on explicit assumptions and don’t smoothly extend to all the regression problems, especially tasks with high-dimensional label spaces. For example, order relationships cannot be defined for all the label spaces. Given the importance of the correspondence between the label space and feature space for imbalanced regression, can we effectively transfer inter-label relationships, regardless of their complexity, to the feature space?
Method
We propose ConR that is a Contrastive Regularizer to enforce this correspondence. ConR is a multi-positive-pair version of infoNCEloss [1] that addresses continuous label space. Fig 1 illustrates an intuitive example for ConR from the task of age estimation from images of individuals with ages: 1, 21, 25 and 80, where 1 and 80 are the minority examples. Without using ConR, similarities in the feature space are not aligned with the relationships in the label space. Thus, the minority samples’ features are collapsed to the majority sample, and have similar predictions (Fig 1a). ConR regularizes the feature space by simultaneously encouraging locality via pulling together positive pairs and preserving global correlations by pushing negative pairs. Assuming an anchor of the 21 year-old, ConR 1) weights the contrastive objective for minority examples more than majority examples to provide better separation in feature space, and 2) increases weighting based on how heavily mis-labelled an example is (Fig 1b.1 to Fig 1b.3). We demonstrate that ConR effectively translates these properties from label and feature space, and boosts the regression performance on minority samples (Fig 1c).
Fig 2 shows the pipeline of ConR and its main contributions:
1. Label and prediction similarities are measured by considering a similarity window around each value in the label space. Thus, pulling together similar samples implicitly imposes local feature sharing.

Figure 1: ConR key insights. a) Without ConR, it is common to have minority examples mixed with majority examples in terms of predicted age (pred. age). b) ConR adds additional loss weight for minority, and mis-labelled examples, resulting in better feature representations and c) better prediction error
2. Negative pairs are sampled based on the degree of deviation they introduce to the correspondence of similarities in feature and label space and compensate for the under-represented samples.
3. Negative pairs are pushed away proportional to their label similarity and the density of the anchor’s label.
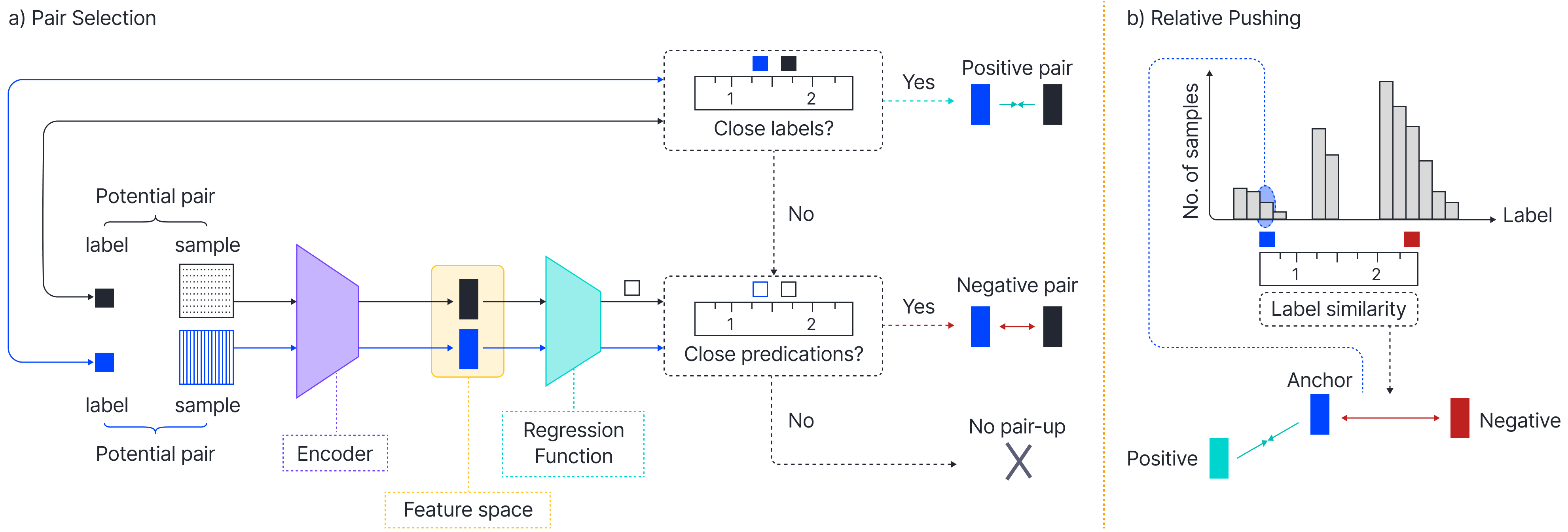
Figure 2: The framework of ConR is to translate label similarities to the feature space. a) Per each augmented sample, ConR selects positive and negative pairs with regards to the label similarities and prediction similarities. b) ConR pulls positive pairs together while pushing away Negative pairs regarding their label similarities and label distribution for the anchor. In this way, the minority anchor
pushes negative samples harder and pushing power is relative to the label similarities.
Main Results
ConR is orthogonal to imbalanced learning techniques and functions seamlessly on high-dimensional label spaces. Our comprehensive experiments on large-scale Deep Imbalanced Regression (DIR) benchmarks for facial age and depth estimation show that ConR significantly boosts the DIR performance, especially on depth estimation, which has a complicated and high-dimensional label space. Fig 3 compares the considerable performance gain resulting from plugging ConR into the deep imbalanced regression baselines (LDS, FDS and Balanced MSE) for NYUD2-DIR benchmark.

Figure 3: Comparison of the performance gain by regularizing the DIR baselines (LDS, FDS, Balanced MSE) with ConR on NYUD2-DIR benchmark.
Concluding Remarks
ConR, is a novel regularizer that encapsulates desirable properties for deep imbalanced regression without any explicit assumption about inter-label dependencies. ConR is complementary to all regression models. Our extensive experiments on uni- and multi-dimensional DIR benchmarks show that regularizing a regression model with ConR considerably lifts its performance, especially for the under-represented samples and high-dimensional label spaces.
Ultimately, our findings demonstrate that ConR opens a new perspective to contrastive regression and is inspiring for further studies. Contrastive methods rely on rich data augmentations and the best performance of ConR on tasks with no well-defined data augmentations requires further work to define task-specific data augmentations. Our future study is to investigate the impact of task-agnostic data augmentations to imbalanced contrastive regression.
References
[1] Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018.
[2] Yuzhe Yang, Kaiwen Zha, Yingcong Chen, Hao Wang, and Dina Katabi. Delving into deep imbalanced regression. In International Conference on Machine Learning, pages 11842–11851. PMLR, 2021.
Work With Us!
RBC Borealis is looking to hire for various roles across different teams. Visit our career page now and discover opportunities to join similar impactful projects!
Careers at RBC Borealis