
Introduction
The 38th Conference on Computer Vision and Pattern Recognition was held on June 14-19 and, for the first time, was held as a fully virtual conference. The first CVPR was held in 1977 (although under a different name) and had only 63 papers which certainly would have made going through the proceedings a much easier endeavour. Since then it has grown into the premier conference in the field of computer vision with a massive technical program. This year there were the usual highlights at CVPR: the plenary talks (fireside chats with Satya Nadella and Charlie Bell), the award winning papers (presented by Greg Mori, CVPR 2020 program chair and RBC Borealis’s Senior Research Director) and the retrospective Longuet-Higgins Prize. (Be sure to check out this excellent post by Michael J Black about one of the Longuet-Higgins Prize winning papers.) But there’s much more to CVPR 2020; this year alone had nearly 1,500 papers along with a wide array of tutorials and workshops. Our researchers have picked out a few of their favourites to highlight.
Towards Visually Explaining Variational Autoencoders
Wenqian Liu, Runze Li, Meng Zheng, Srikrishna Karanam, Ziyan Wu, Bir Bhanu, Richard J. Radke, and Octavia Camps.
Related Papers:
What problem does it solve?
The paper proposed a gradient-based method to explain Variational Autoencoders (VAE) for images. The proposed method is also able to localize anomalies in images, which are examples that are not seen in training.
Why is this important?
The method extends the widely-used Grad-CAM method to explain generative models, specifically VAEs. It can produce visual explanations for images that are generated from VAEs. For example, what is the most important image region for the digit 5? Which region of the digit 7 is different from that of digit 1? Visual explanations for these questions provide a clear understanding of the reasoning behind an algorithms’ predictions and adds robustness and performance guarantees.
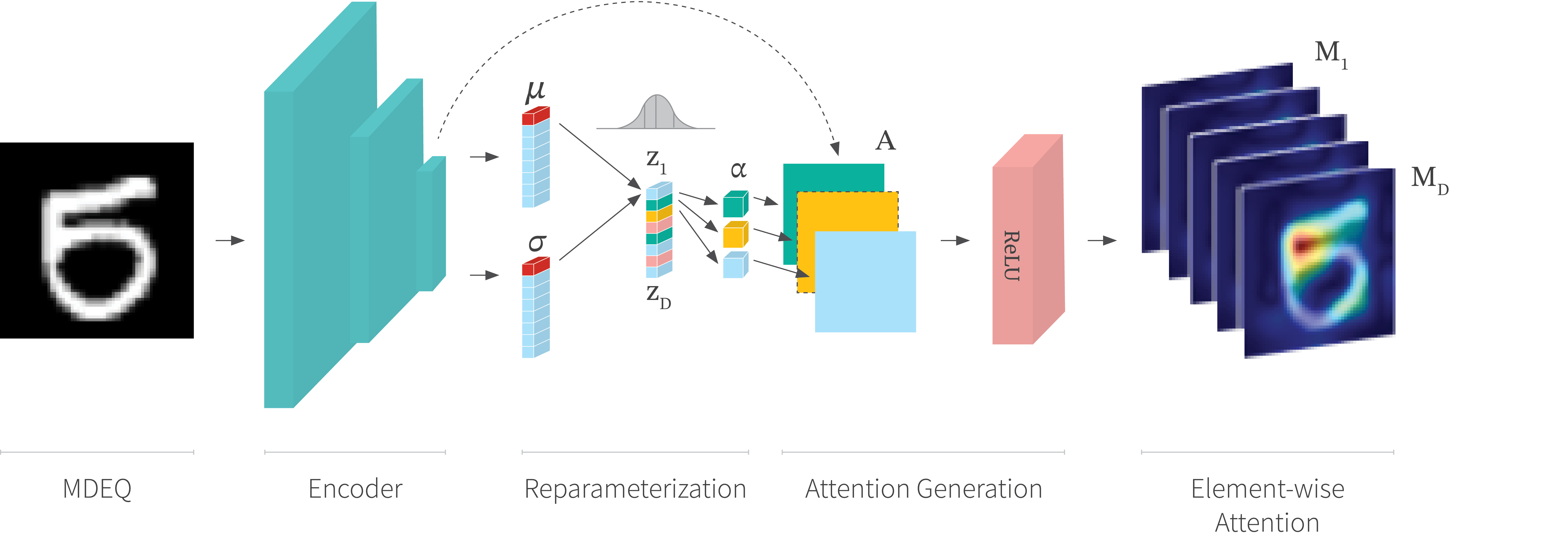
Figure 1. Element-wise attention generation with a VAE. The method backpropagates the gradients of the element $\mathbf{z}_i$ of the latent vector to the last CNN layer of the encoder. Then, the attention map is generated using the Grad-CAM method.
The approach taken and how it relates to previous work:
The method is based on Grad-CAM in which the key technique is the choice of differentiable activation. The differentiable activation will be back-propagated to the last CNN layer to obtain channel-wise weights and thus a visual attention map. This paper uses the latent vector $\mathbf{z}$ as the differentiable activation. Specifically, each element $\mathbf{z}_i$ is backpropagated independently to generate an element-wise attention map. Then, the overall attention map is the mean of element-wise attention maps. Figure 1 illustrates the process of element-wise attention generation.
By modifying the differentiable activation to the sum of all elements in the (inferred) mean vector, the method is also able to generate anomaly attention maps. Further, the method can help the VAE to learn improved latent space disentanglement by adding an attention disentanglement loss.
Results
The performance of the method is demonstrated qualitatively and quantitatively.
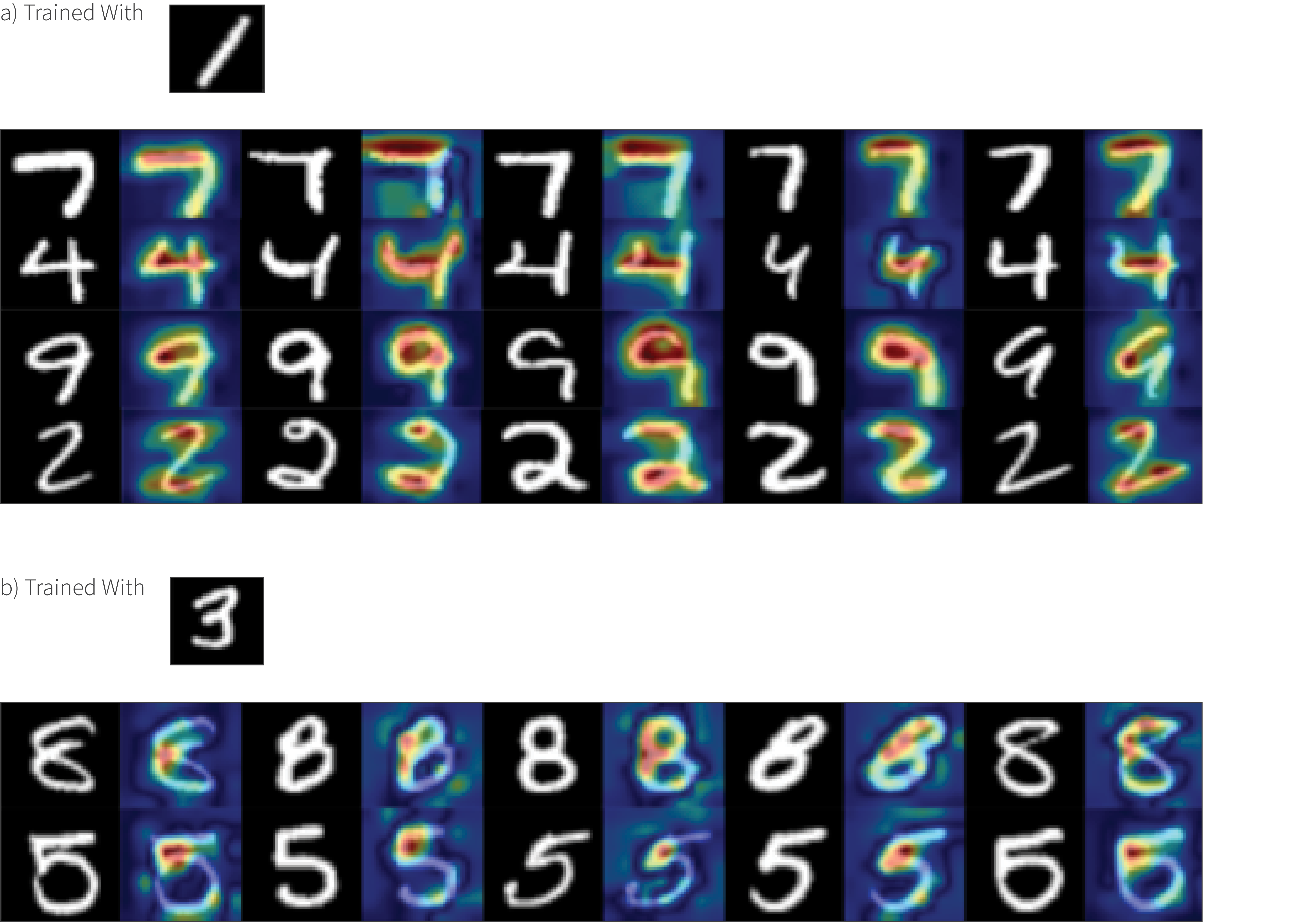
Figure 2. Anomaly localization results from the MNIST dataset.
Figure 2 shows qualitative results on the MNIST dataset for anomaly attention explanations. The method correctly highlights the difference between the training digit and the testing digits. For example, the heatmap highlights a key difference region between the “1” and the “7”, which is the top-horizontal bar in “7”.
The paper also shows quantitative results on a pedestrian video dataset (UCSD Ped 1) and a more comprehensive anomaly detection dataset (MVTec AD) using pixel-level segmentation scores. Its performance is significantly better than vanilla-VAE on UCSD Ped 1 and moderately better than previous work on MVTec AD.
CvxNet: Learnable Convex Decomposition
Boyang Deng, Kyle Genova, Soroosh Yazdani, Sofien Bouaziz, Geoffrey Hinton and Andrea Tagliasacchi.
Related Papers:
What problem does it solve?
This paper presents a new, differentiable representation of 3D shape based on convex polytopes.
Why this is important?
There are numerous shape representations that are widely used in computer vision and computer graphics. However, most are extremely expensive to work with, not easily differentiable or impractical to use in some settings. A good, compact representation of 3D shape which is differentiable and efficient to work with would be a boon to a wide range of applications which work with 3D shape, e.g., 3D reconstruction from images, recognition of 3D objects, and rendering and physical simulation of 3D shapes.
Previous work:
There are many different shape representations in common use including voxel grids, signed distance functions, implicit surfaces, meshes, etc. In computer vision one of the most common is in terms of voxels where a 3D object is represented by a 3D grid of values which indicate whether the object is occupying a given point. Voxel grids are convenient because modern machine learning tools like convolutional networks can be naturally used, just as with images. Unfortunately, the memory requirements for voxel representations grows cubicly (i.e., $O(n^3)$) with resolution $n$, quickly outgrowing the available memory on GPUs. This has led to the development of OctTrees and other specialized methods to attempt to save memory. Other approaches, including shape primitives, implicit shape representations and meshes have been used but come with their own challenges, for instance being too simplistic to capture real geometry, non-differentiable or computationally expensive.
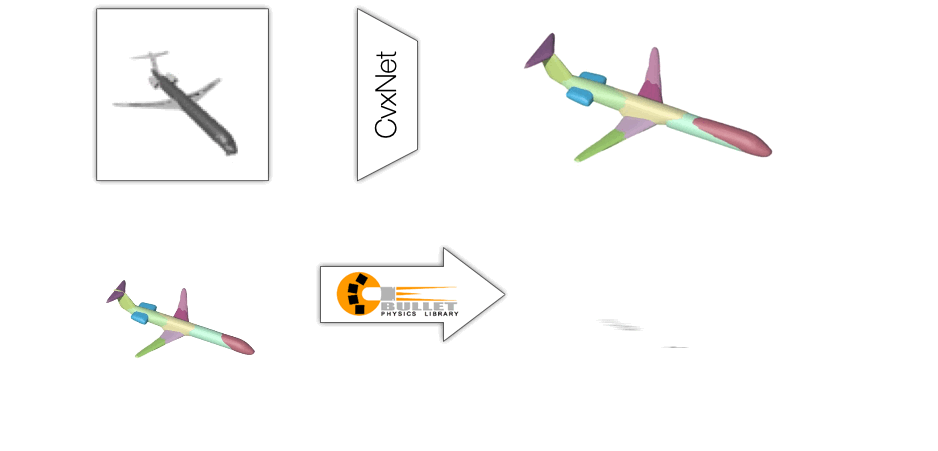
Figure 3. CvxNet defines a differentiable and efficient representation of shape using a set of hyper-planes which define a set of smooth, signed distance functions which can be then smoothly combined to produce a shape.
Approach taken:
Instead, this paper proposes to represent a shape by a combination of convex shapes which are themselves defined by a set of planes. The signed distance from a plane $h$ is defined as\[
\mathcal{H}_h(\mathbf{x}) = \mathbf{n}_h \cdot \mathbf{x} + d_h
\]
where $\mathbf{n}_h$ is the (unit) normal of the plane and $d_h$ is the distance of the plane from the origin. A convex shape can then be defined as the set of all points which are on the positive side of every plane. To do this smoothly, CvxNet makes use of the Sigmoid and LogSumExp functions, i.e.,
\[
\mathcal{C}(\mathbf{x}) = \textrm{Sigmoid}(-\sigma \textrm{LogSumExp}_h \delta \mathcal{H}_h(\mathbf{x}) )
\]
where $\mathcal{C}(\mathbf{x})$ is close to 1 for points inside the shape and close to 0 for points on the outside. The values $\sigma$ and $\delta$ control the smoothness of the shape. This construction is show in Figure 4. The result of this is a function $\mathcal{C}(\mathbf{x})$ which is fast to compute to determine inside/outside for a given convex shape. More complex (i.e., non-convex) shapes can then be constructed by a union of these convex parts. Further, the underlying planes themselves can be used directly to efficiently construct other representations like polygonal meshes which are convenient for use in simulation.
The paper then goes on to train an autoencoder model of these planes on a database of shapes. The result is a low dimensional latent space and a decoder which can be used for other tasks such as reconstructing 3D shapes from depth or RGB images.
Results:
They demonstrate both the fidelity of the overall representation as well as it’s usefulness in 3D estimation tasks. Quantitatively, the results shows significant improvement in the depth-to-3D task and competitive performance on RGB-to-3D task. The traditional table of numbers can be found in the paper. However more interestingly, the latent space representation finds natural and semantically meaningful parts (i.e., the individual convex pieces) in an entirely unsupervised manner. These can be seen in Figure 4.
Figure 3. CvxNet defines a differentiable and efficient representation of shape using a set of hyper-planes which define a set of smooth, signed distance functions which can be then smoothly combined to produce a shape.
Figure 4. The CvxNet learned representation produces natural and often semantically meaningful parts in a representation which is compact and computationally efficient.
Deep Declarative Networks
Organizers: Stephen Gould, Anoop Cherian, Dylan Campbell and Richard Hartley
Related Papers:
What problem does it solve?
“Deep Declarative Networks” are a new class of machine learning model which indirectly defines a transformation.
Why this is important?
The current success of machine learning to date has been driven by explicitly defining parametric functions which transform inputs into the desired output. However, these models are growing increasingly large (e.g., the recently released GPT-3 has over 175 billion parameters) and data hungry. Further, some recent work has suggested that many of the parameters in these massive models are redundant. In contrast, declarative networks operate by defining these transformations indirectly. For instance, the transformation may be the solution to Ordinary Differential Equation, the minimum of an energy function or the root to a non-linear equation. The result are methods which are more compact and efficient and may be the future of machine learning.
This workshop brought together researchers who have been pushing in this direction in one place to both review the results to date and discuss the outstanding problems in the area. For people unfamiliar with this exciting new direction, the talks and papers of this workshop are an excellent starting point. Further, they contain previews of exciting new work to come.
How does this relate to previous work:
Deep Equilibrium Models, Neural ODEs and Differentiable Convex Optimization Layers were proposed in 2019 and 2018 respectively and this workshop is a natural outgrowth of this interest in finding new ways to define the transformations we aim to learn.
Results:
The presented papers and invited talks at this workshop contained many exciting results. However, one notable result was in the talk by Zico Kolter. There he previewed the latest results with Multiscale Deep Equilibrium Models which was just recently released on arXiv. The results, some of which can be seen in Figure 5, show that these models are both competitive with state-of-the-art methods on image problems like classification and semantic segmentation but result in models which are smaller. Further, for size-constrained models (e.g., with limited numbers of parameters or memory usage), these models can significantly outperform existing techniques.
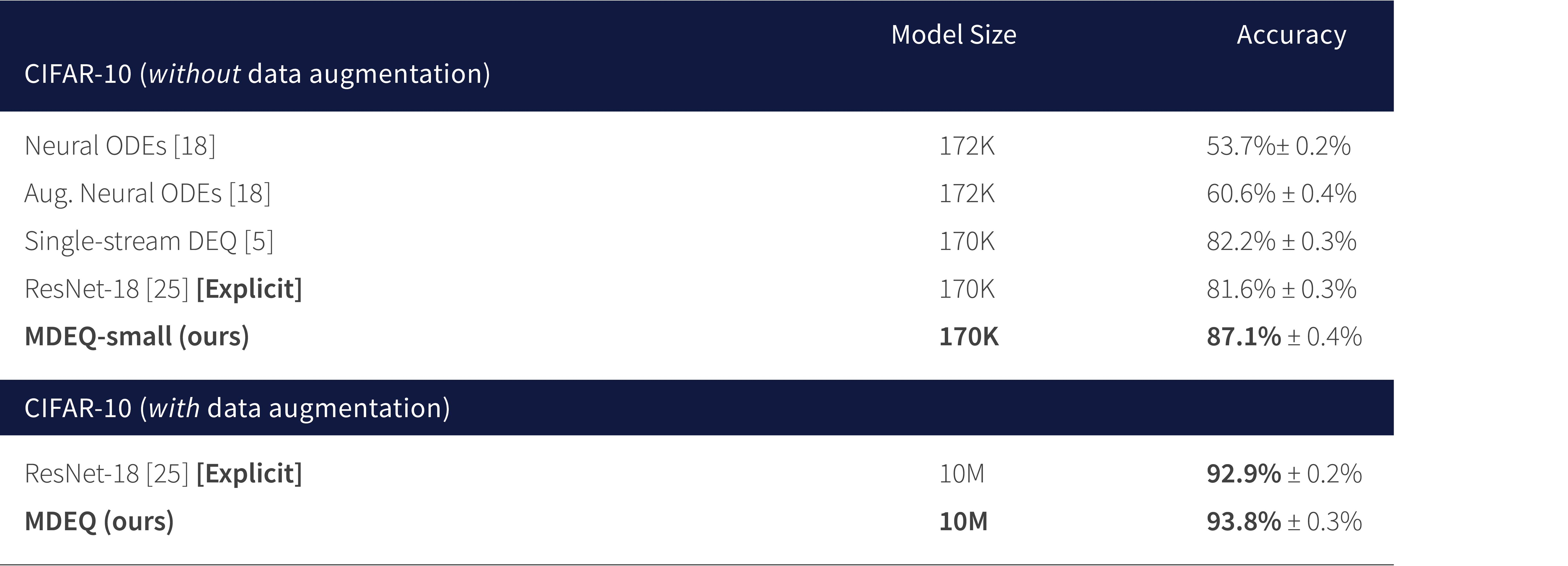
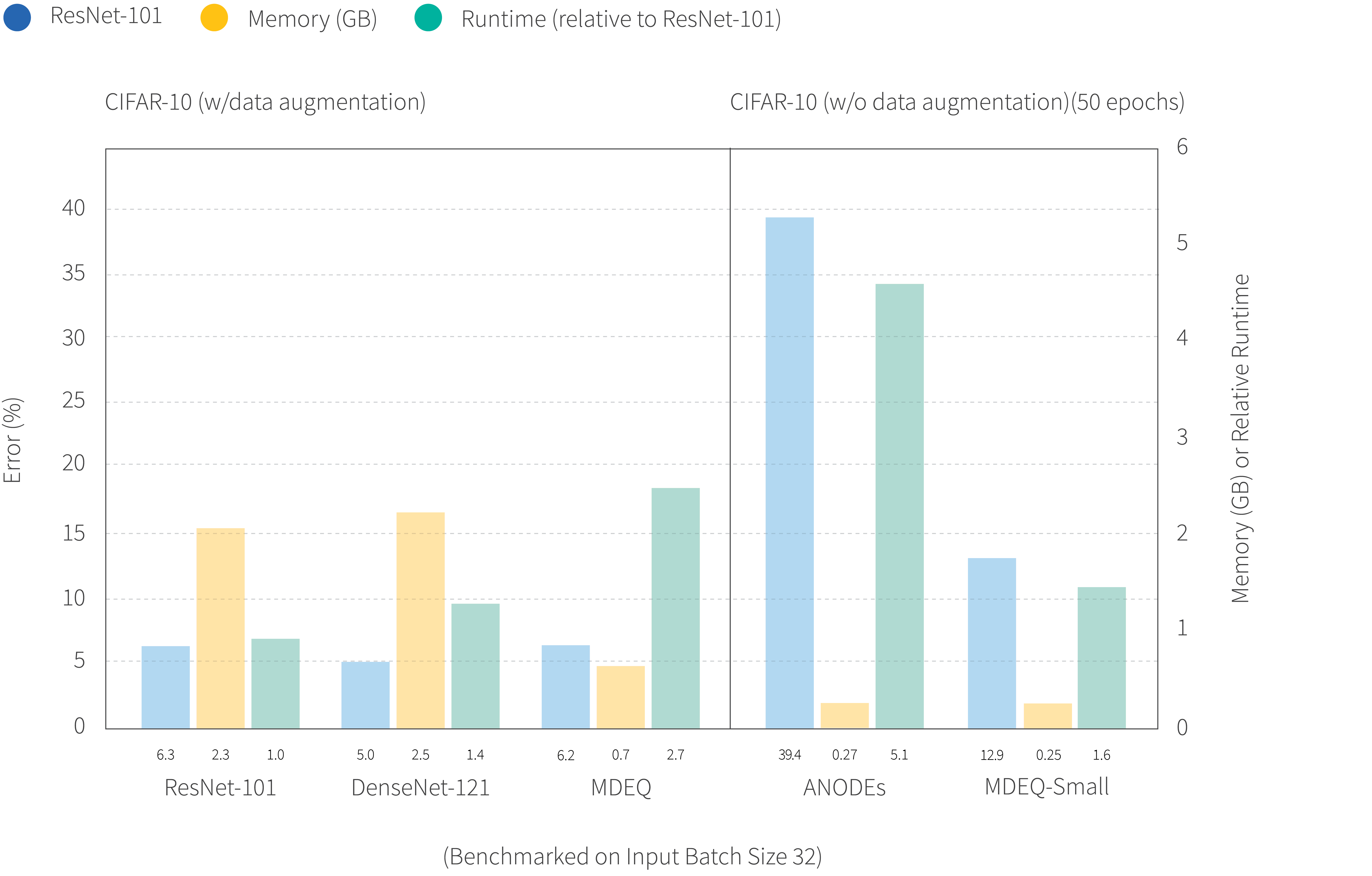
Figure 5. CIFAR-10 Classification. Multiscale Deep Equilibrium models outperform explicit methods for image classification with the same number of parameters (left). Further they are competitive with state-of-the-art models but with significantly lower memory requirements (right).