
Over the past decade, the orchestration landscape has evolved significantly. Early on, workload managers like Slurm were commonly used to schedule jobs, but as data workflows became more complex, software engineering-oriented orchestration tools emerged. Today, we have a variety of orchestration frameworks designed for different use cases, including Airflow, Prefect, Kubeflow, and Dagster. While this provides flexibility, it also makes choosing the right tool more challenging.
When building modern data pipelines, projects often rely on multiple orchestration tools that need to work together. For example, Kubeflow is commonly used for machine learning workflows, while Airflow and Dagster are preferred for Extract, Load, Transform (ELT) pipelines and data engineering workloads. These tools often operate in isolated namespaces, but when projects need to collaborate, integration strategies become critical.
This blog will focus on Dagster, a declarative and asset-centric orchestration framework that differs from traditional task-based approaches. Dagster emphasizes data dependencies rather than just execution order, making it particularly well-suited for data-driven applications, ELT workflows, and machine learning (ML) pipelines. A key question is: How can different projects effectively collaborate within Dagster while minimizing required maintenance?
To address this, teams must decide on collaboration, maintenance, and deployment strategies that best fit their workflows. This blog will explore different approaches to achieving seamless integration between orchestration tools, with a focus on maximizing efficiency and maintainability.
Background on Dagster
As the 3 Vs (Volume, Velocity, Variety) of data have scaled over the past decade, orchestration has become a critical component of software architectural design. Whether you are developing frequently triggered ML pipelines, performing scheduled ETL ingestion, or generating analytics reports, orchestration ensures efficiency and governance.
Tools like Airflow have become standard for workflow scheduling, lineage tracking, and governance. However, among the many orchestration frameworks available, Dagster stands out for its declarative and asset-centric approach to data engineering.
When thinking about pipelines imperatively, it’s natural to define a Directed Acyclic Graph (DAG) of tasks/jobs. For example, in Airflow, we might define a job that runs every Sunday night, pulls data from Source A, performs transformations, and stores the result in a data sink. However, this imperative mindset focuses on task execution rather than the data itself, leading to several potential issues:
- Organizational Silos – Without incorporating data context, workflow managers like Airflow treat the data as hidden within the job itself, and they fail to provide a unified data plane, making it difficult for projects to gain visibility into data availability and lineage. As organizations scale, the complexity of answering questions like “Which partition has been ingested?” and “What shared transformed feature from other projects could I reuse?” becomes a major challenge to answer quickly.
- Unbundling Issue – Traditional workflow managers separate execution from orchestration, often outsourcing execution to tools like Airbyte, etc. This hides data dependencies from the orchestrator and eventually, pipelines end up using various tools without knowing the inner workings of the data platform and the assets managed. For example, Dagster addresses this problem with good integration with DBT, incorporating DBT models, tests, and incremental models.
In February 2022, with the release of Dagster 0.14.0, a new concept was introduced: Software-Defined Asset.
A software-defined asset is a description, in code, of an asset that should exist and how to produce and update that asset.
This philosophy shifts orchestration from a task-based approach to an asset-driven model, offering a new perspective on data and ML pipeline management. In this release, Sandy Ryza gave an in-depth explanation of Dagster’s declarative data management and how it integrates with modern stack tools like DBT. By treating assets as a first-class citizen, Dagster makes defining and managing data assets more intuitive and maintainable.
Open Source Dagster Architecture
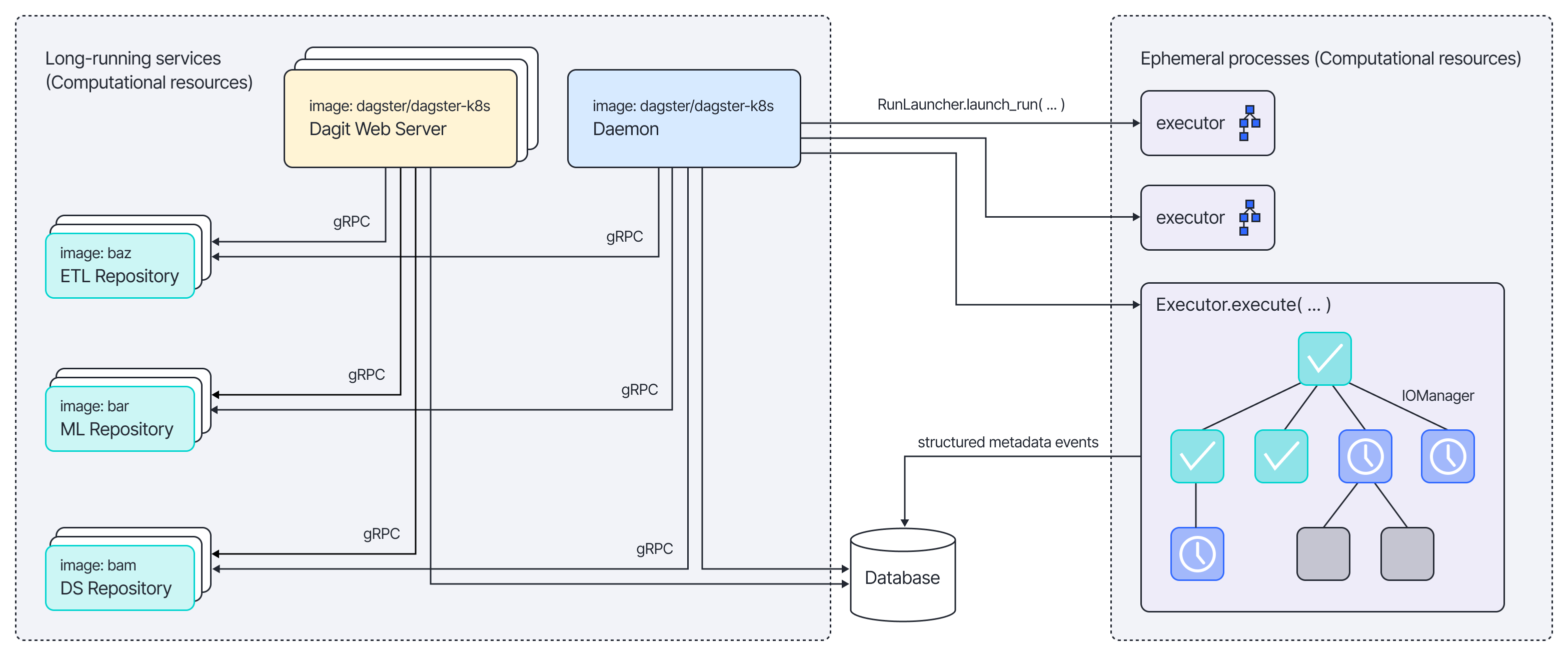
Figure 1. From Open Source Dagster Architecture Doc.
There are several components in the Dagster Open Source deployment:
- Code Location: Serves the user-defined assets for that location.
- Web Server: Dagster UI for users to interact with on the webpage.
- Daemon: Responsible for scheduling, sensors (auto-materialization, etc), and queuing the runs.
- Database: Storage for run event logs, other metadata, and powers much of the real-time and historical data visible in the UI. The default is SQLite.
In the above diagram, Dagster has a nice separation between its web server, daemon, and code locations. Each code location can be deployed independently of the core part (web server, daemon) of Dagster, which enables dependency separation and adds more flexibility around the data layer of the organization.
Motivation for Multiple Code Locations
As more projects develop within an organization, it is natural to consider the following question: Could projects share the webserver and daemon, and manage their own code locations within the project?
Pros:
- Simplified management for each project:
- Each project only needs to handle its own code locations.
- The Dagster web server and daemon grab necessary information (grpc host and port) from the workspace file, reducing setup effort.
- Compared to full deployment management (e.g., version upgrades, workspace additions), this approach minimizes overhead, allowing teams to focus on the data itself.
- Enhanced transparency and cross-project collaboration:
- As teams align on a shared data plane (e.g., Data Lake/Warehouse), data reuse becomes easier.
- Benefits include aggregating business data insights from multiple sources or scheduled business intelligence reports. (For example, Project B sets up a sensor to start once Project A’s ingestion job finishes).
- Flexibility for multiple code locations for separate pipelines with a project:
- As applications scale, services often need independent execution environments.
- Instead of maintaining a monolithic structure, projects can separate concerns (e.g., training and inference pipelines in different locations).
- This encourages parallel development and isolation, improving maintainability.
Cons:
- Lack of fine-grained RBAC (Role based Access Control) in open-source Dagster:
- The open-source version lacks built-in authentication and authorization.
- While adding a sidecar container for authentication is an option, there’s no fine-grained control over user permissions (e.g., view/edit access is not available).
- With a shared Dagster UI and daemon, users from different projects can execute any job once they gain UI access, which could be a deal-breaker for some teams.
Multiple Code Locations Design on K8s
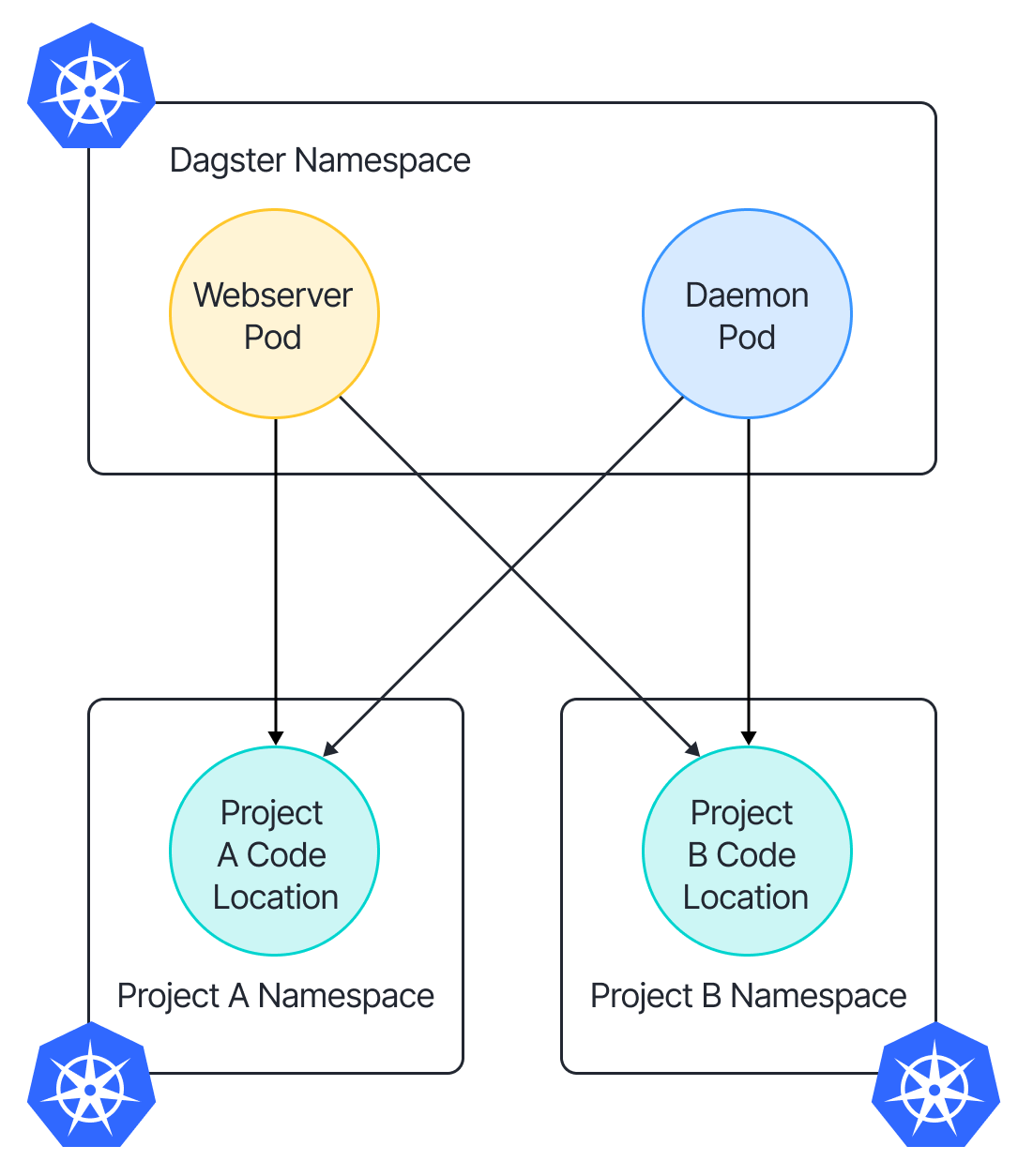
Figure 2. Simple setup with 2 code location on K8s.
To make sure that the webserver and daemon are able to communicate with user-defined DAGs, we could define `workspace.yaml` as something like the following:
load_from:
- grpc_server:
host: project-A-code-location-service.${PROJECT_A_NAMESPACE}.svc.cluster.local
port: 4000
location_name: "project-A"
- grpc_server:
host: project-B-code-location-service.${PROJECT_B_NAMESPACE}.svc.cluster.local
port: 4000
location_name: "project-B"In the above, project A and B each created their code location server in their respective namespace, and used Kubernetes Service to communicate across namespace.
Challenges Faced & Solutions
1. Testing Challenge
Context:
Dagster official docs have provided lots of useful tools and tips on how to properly test your defined functions, especially in the section on Separating Business Logic from Environments. We also separated our business logic from the orchestration codebase. As a result, our orchestration code only invokes the functions imported from the business logic codebase, which made it super easy for us to integrate existing business code into the Dagster pipeline, and also potentially migrate to other tooling flexibly in the future.
Solution:
Having a separation between business logic and orchestration environment. The engineering focus and effort should be put more on the business logic development itself. In the case of developing data transformation pipelines, we could define assets like the following to help developers implement, test, and troubleshoot their complex data pipelines.
from typing import Any
from dagster import asset, AssetExecutionContext
from src.utils import my_filter, my_transform
@asset
def transformed_data(context: AssetExecutionContext, raw_data: pd.DataFrame) -> pd.DataFrame:
filtered_data = my_filter(raw_data)
transformed_data = my_transform(filtered_data)
metadata = {}
....
context.add_output_metadata(metadata)
return transformed_dataDevelopers can work on `my_filter` and `my_transform`, and easily unit test them before going into more integrated Dagster testing
By implementing and enforcing this decoupling, code components can plug in different resource configurations. For example, development and production could have different data sources and sinks or even the same data sources and sinks but different ways of handling IO. For example, in the official “Transitioning Data Pipelines from Development into Production” doc, we have:
resources = {
"local": {
"snowflake_io_manager": SnowflakePandasIOManager(
account="abc1234.us-east-1",
user=EnvVar("DEV_SNOWFLAKE_USER"),
password=EnvVar("DEV_SNOWFLAKE_PASSWORD"),
database="LOCAL",
schema=EnvVar("DEV_SNOWFLAKE_SCHEMA"),
),
},
"production": {
"snowflake_io_manager": SnowflakePandasIOManager(
account="abc1234.us-east-1",
user="system@company.com",
password=EnvVar("SYSTEM_SNOWFLAKE_PASSWORD"),
database="PRODUCTION",
schema="HACKER_NEWS",
),
},
}
deployment_name = os.getenv("DAGSTER_DEPLOYMENT", "local")
defs = Definitions(
assets=[items, comments, stories], resources=resources[deployment_name]
)Code Location could load different config settings based on different application environments.
2. Project-Owned Workers Challenge:
Context:
In most cases, projects don’t care which namespace the worker pods are launched in. However, for separation, access control, or resource monitoring, some teams may prefer dynamically assigned namespaces via the Dagster Launcher (see Figure 3). While developing k8sRunLauncher, we could define custom configurations for the executor but haven’t yet found a straightforward way for the Dagster daemon to launch workers in the same namespace as the deployed code location without requiring a super-powered service account.
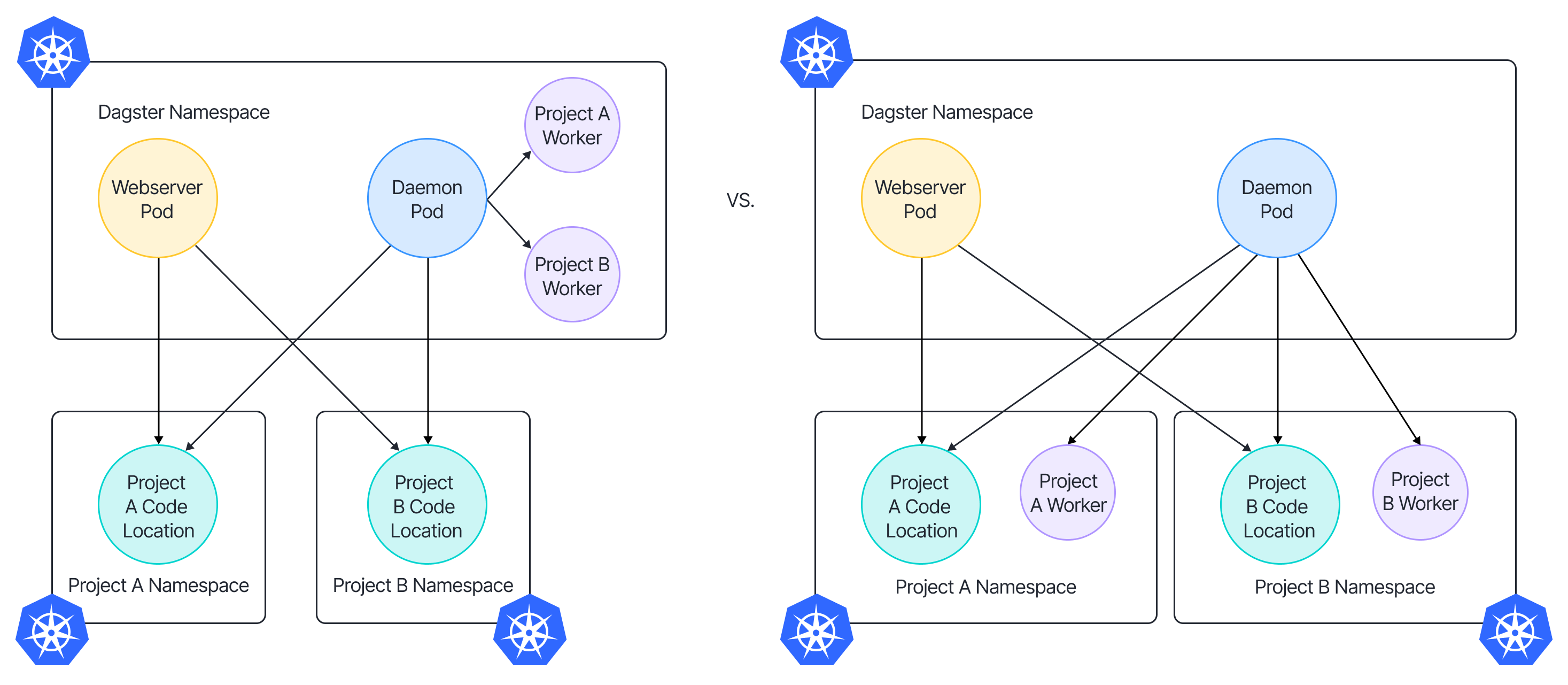
Figure 3. Comparison between different setup on K8s designs.
Solution:
Dagster Celery. Dagster has integration with Celery. With Dagster Celery setup, dagster-celery executor submits the Celery task to the broker (redis etc). The dagster-celery workers then pick up tasks from corresponding work queues, and execute the steps accordingly (see Figure 4).
By using dagster-celery, we can use the message broker to implement the distributed queue where users materialize the assets, push the job to the message broker, and then the project worker picks up the job from the project queue. This pattern gives projects full control of their own queue and their workers within their own namespace. In our case, we chose RabbitMQ as our message broker and deployed the workers into each project namespace. For an overview of our solution see Figure 5.
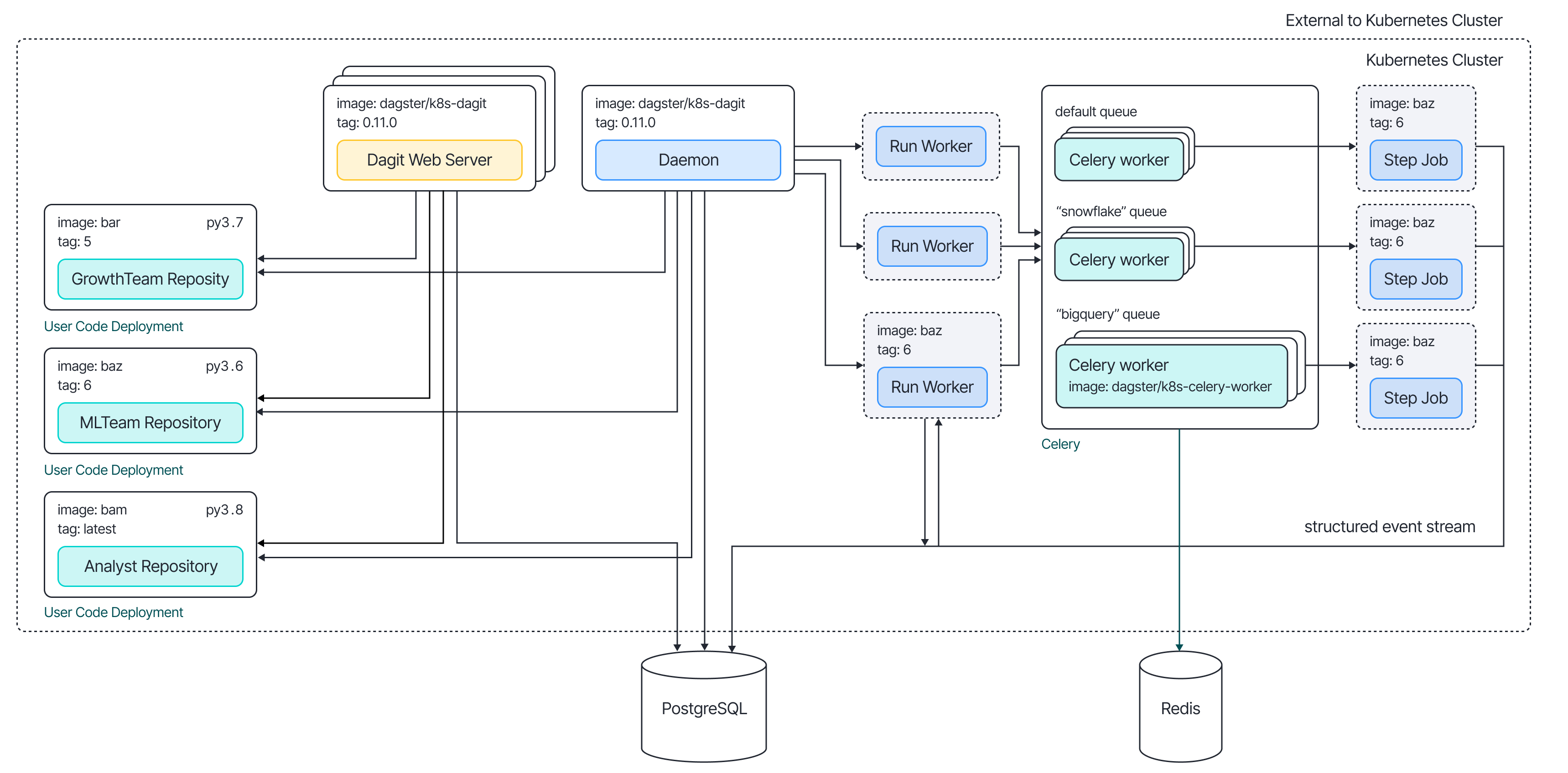
Figure 4. Deployment architecture diagram from the official Dagster Celery Helm Doc.
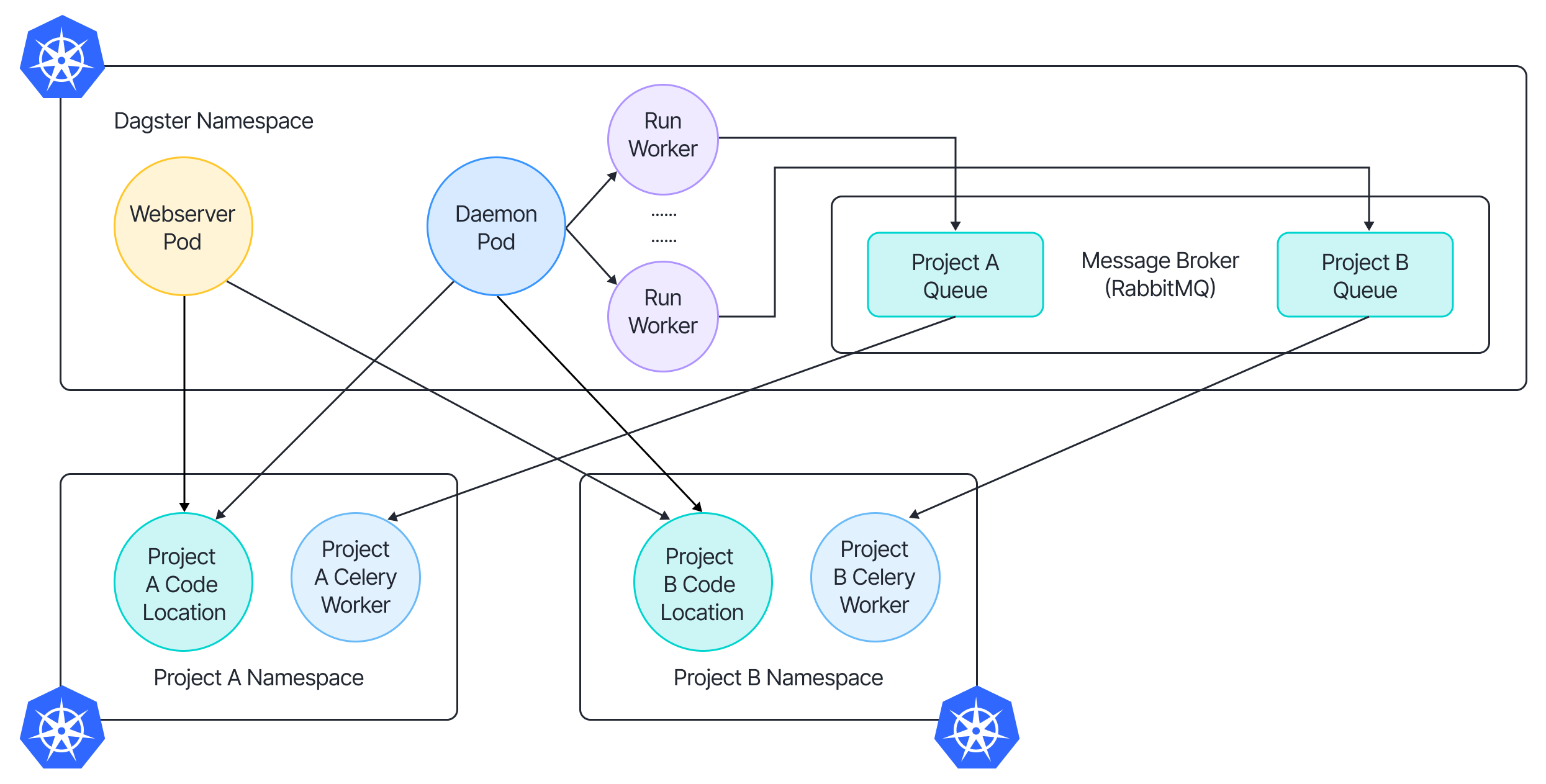
Figure 5. Overview of our solution with Dagster Celery worker and Rabbit MQ as message broker.
So, what does it look like for the project?
from dagster import Definitions, load_assets_from_package_module
from dagster_celery_k8s.executor import celery_k8s_job_executor
from . import assets
all_assets = load_assets_from_package_module(package_module=assets)
defs = Definitions(
assets=all_assets,
executor=celery_k8s_job_executor.configured(
{
"broker": "pyamqp://guest:guest@rabbitmq//",
"backend": "rpc://",
"job_namespace": "project-a-namespace",
}
),
)Code Location setup for connecting to the message queue.
celery-worker
apiVersion: apps/v1
kind: Deployment
metadata:
name: worker-queue-${APPLICATION_NAME}
labels:
app: ${APPLICATION_NAME}
spec:
replicas: 1
selector:
matchLabels:
app: ${APPLICATION_NAME}
template:
metadata:
labels:
app: ${APPLICATION_NAME}
spec:
serviceAccountName: default
initContainers:
- name: check-db-ready
image: postgres:14
imagePullPolicy: Always
command: ['sh', '-c', 'pg_isready -h $POSTGRES_HOST -p $POSTGRES_PORT -U $POSTGRES_USER']
env:
- name: POSTGRES_HOST
value: ${POSTGRES_HOST}
- name: POSTGRES_PORT
value: ${POSTGRES_PORT}
- name: POSTGRES_USER
value: postgres_user
containers:
- name: worker-queue
imagePullPolicy: Always
image: dagster/dagster-celery-k8s
command: ["dagster-celery"]
args: ["worker", "start", "-A", "dagster_celery_k8s.app", "-y", "${DAGSTER_HOME_PATH}/celery.yaml", "-q", "${APPLICATION_NAME}-queue"]
env:
- name: DAGSTER_PG_PASSWORD
value: postgres_password
- name: DAGSTER_HOME
value: ${DAGSTER_HOME_PATH}
volumeMounts:
- name: ${APPLICATION_NAME}-core-map
mountPath: ${DAGSTER_HOME_PATH}
- name: ${APPLICATION_NAME}-celery
mountPath: ${DAGSTER_HOME_PATH}/dagster_celery
volumes:
- name: ${APPLICATION_NAME}-core-map
configMap:
name: ${APPLICATION_NAME}-core-config
items:
- key: dagster.yaml
path: dagster.yaml
- key: celery.yaml
path: celery.yaml
- name: ${APPLICATION_NAME}-celery
emptyDir:
sizeLimit: 10GiDeployment for the Dagster Celery worker.
3. Authentication and Authorization Challenge
Context:
In the open-source version of Dagster, there is no authentication; anyone with the URL can access Dagster UI. There is also no authorization; users can launch jobs, enable/disable scheduling etc from the UI. (If your jobs are idempotent and overwriting data isn’t a concern, this may not be an issue.)
Solution:
During our development, we implemented an authentication mechanism using an Active Directory (AD) group. As a user, you need to: Apply for the required AD group access to log in and use the Dagster UI.
How it Works:
In Kubernetes, we map the AD group to the corresponding namespace, ensuring users apply for the correct access. Using the Sidecar Container, we route traffic through an authentication Sidecar Container, which verifies access before redirecting users to the Dagster web server.
Implementation:
We use an OAuth container as a Sidecar Container. In the webserver deployment, we add the following:
containers:
- name: oauth-proxy
image: oauth2-proxy:latest
imagePullPolicy: IfNotPresent
ports:
- name: oauth-proxy
containerPort: "${{OAUTH_PROXY_PORT}}"
env:
- name: NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
args:
- >-
-https-address=:${OAUTH_PROXY_PORT}
- --provider=openshift
- --openshift-service-account=default
- >-
-upstream=http://localhost:${WEBSERVER_PORT}
- --tls-cert=/etc/tls/private/tls.crt
- --tls-key=/etc/tls/private/tls.key
- --cookie-secret=SECRET
- '-openshift-ca=/etc/pki/tls/cert.pem'
- '-openshift-ca=/var/run/secrets/kubernetes.io/serviceaccount/ca.crt'
- >-
-openshift-sar={"resource": "namespaces", "verb": "get",
"resourceName": "$(NAMESPACE)", "namespace": "$(NAMESPACE)"}
- '-tls-cert=/etc/tls/private/tls.crt'
- '-tls-key=/etc/tls/private/tls.key'
- >-
-client-secret-file=/var/run/secrets/kubernetes.io/serviceaccount/token
- '-skip-auth-regex=^/metrics'
volumeMounts:
- mountPath: /etc/tls/private
name: proxy-tlsContainer config for setting up authentication.
Conclusion
As more projects onboard to Dagster for its asset-centric and declarative approach, cross-project collaboration becomes an interesting area to explore and contribute. In development environments, multi-project setups reduce operational silos and maintenance overhead. However, in the open-source version of Dagster, the lack of fine-grained Role Based Access Control (RBAC) presents a challenge making it difficult to implement cross-project code location design functions in production environments.
Work with us!
RBC Borealis is looking to hire for various roles across our data engineering teams. Visit our career page to explore our career opportunities and join our team!
View open roles