
This published case study is a direct outcome of RBC’s partnership with the Vector Institute, demonstrating how Responsible AI (RAI) principles can be embedded into real-world financial applications.
This project was jointly conducted at the start of 2025 by RBC Borealis and Vector Institute, through the Vector Institute Federated Learning Bootcamp, as a result of a strategic ongoing partnership between the two organizations. It illustrates how joint research can translate into an implemented, measurable use case that addresses pressing industry challenges while meeting the highest standards of fairness, transparency, and accountability.
A Collaborative Approach to Responsible AI
During the Bootcamp, RBC Borealis team members Tochi Okeke, Harnoor Dhindsa, Anurag Bejju, and Diane Fenton collaborated with the Vector Institute to tackle the challenge of detecting mule accounts in the financial system. Addressing this issue requires both technical innovation and a commitment to RAI principles. The team explored how a federated learning approach – viewed through an RAI lens could detect mule accounts. Mule accounts often used to move illicit funds, present a complex problem for fraud prevention that demands both ethical and effective solutions.
By design, the solution applied federated learning algorithms to real-world business problems. Using the FL4Health library created by Vector, and combining Vector’s cutting-edge expertise with RBC’s deep practical insights, the team developed an RAI-driven fraud detection system, with a focus on mule accounts, that:
- Preserves data privacy by keeping information within institutional boundaries
- Maintains transparency in how suspicious activity is identified
- Ensures fairness and mitigates potential bias in fraud detection outcomes
From Partnership to Impact
This project builds on our partnership with the Vector Institute, resulting in a publicly shared case study that documents how the approach was developed and applied. By making the findings and methodology available, we aim to contribute to the broader understanding of how RAI can be implemented in the financial sector.
Advancing capabilities that deliver fair and transparent results requires partnerships that combine technical expertise with a shared commitment to Responsible AI. That is why we chose to work with Vector Institute. Together, we developed a solution that tackles the complexity of fraud detection, while upholding fairness, transparency and regulatory compliance.
Dr. Eirene Seiradaki
Director Research Partnerships, RBC Borealis
Collaborative projects like this case study, which came out of our federated learning bootcamp with RBC Borealis, are the key to unlocking AI’s transformative powers. By working closely together, we can supercharge AI adoption while delivering secure, ethical AI solutions for our partners that will benefit all Canadians.
Ali Tayeb
Director, Partnerships & Ecosystem, Vector Institute
Significance of Responsible AI in Fraud Detection
Responsible AI is critically important in mule account fraud detection, because it ensures that the systems used to identify suspicious activity are fair, transparent, and respectful of individual rights. It protects innocent users, safeguards personal data, addresses bias, and supports transparency and accountability. As fraudsters continue to evolve their methods, financial institutions must adopt AI systems that not only detect crime effectively but also uphold public trust and legal standards.
This case study demonstrates that AI innovation and ethics are not competing priorities, they can and must advance together. It also reflects our ongoing commitment to translating Responsible AI principles into concrete, real-world solutions.
Mule Account Fraud
Emerging as a growing threat within the financial services sector, These accounts are often used to move illicit funds and can involve innocent individuals unknowingly aiding criminal activity. If AI systems are not designed responsibly, they can wrongly flag such individuals as criminals, leading to account closures, financial harm, and reputational damage. By applying responsible AI principles, organizations can reduce the risk of harming innocent users and ensure that decisions are made fairly.
Privacy Protection
Fraud detection relies heavily on analyzing sensitive information, including financial transactions, device activity, and user behavior. Without proper safeguards, AI systems may collect excessive data, store it insecurely, or misuse it, which can lead to violations of privacy laws, such as the General Data Protection Regulation (GDPR) or the Personal Information Protection and Electronic Documents Act (PIPEDA). Responsible AI promotes the use of data only when necessary, with clear user consent and secure handling, to protect privacy and maintain compliance with regulations.
Detecting and Reducing Bias and Discrimination in Datasets
AI systems often learn from historical data, which may contain biases related to race, nationality, gender, socioeconomic background, and more. Biases in data can result in unjust overrepresentation of certain social groups in fraud alerts, leading them to be unfairly flagged, even though no wrongdoing has occurred. Responsible AI includes practices such as using diverse and representative data, performing fairness audits, and adjusting models to prevent such outcomes. These steps help ensure that fraud detection systems treat all users equitably.
The Approach Followed
This use case addresses a high-impact challenge in the banking industry: early detection of mule account fraud during account openings. Solving this problem requires advanced machine learning methods combined with a strong foundation in Responsible AI, ensuring models are developed with fairness, privacy, and transparency as core principles.
To that end, we apply federated learning, a privacy-preserving technique that allows institutions to collaboratively train models without sharing sensitive customer data while benefiting from patterns spread across multiple banks. In this setup, each participating bank trains a local model on its own data, and only the learned model parameters are securely aggregated into a shared global model. This enables the detection of fraud patterns that may be invisible to any single institution, while maintaining compliance with data protection regulations. This is especially crucial in identifying mule accounts, which often operate across multiple institutions to obfuscate their activities. We specifically employed Horizontal Federated Learning; a type of federated learning where participating banks hold the same feature set but different client groups.
To illustrate how this technique works in the context of this use case, the diagram below shows the horizontal federated learning architecture applied for mule account fraud detection:
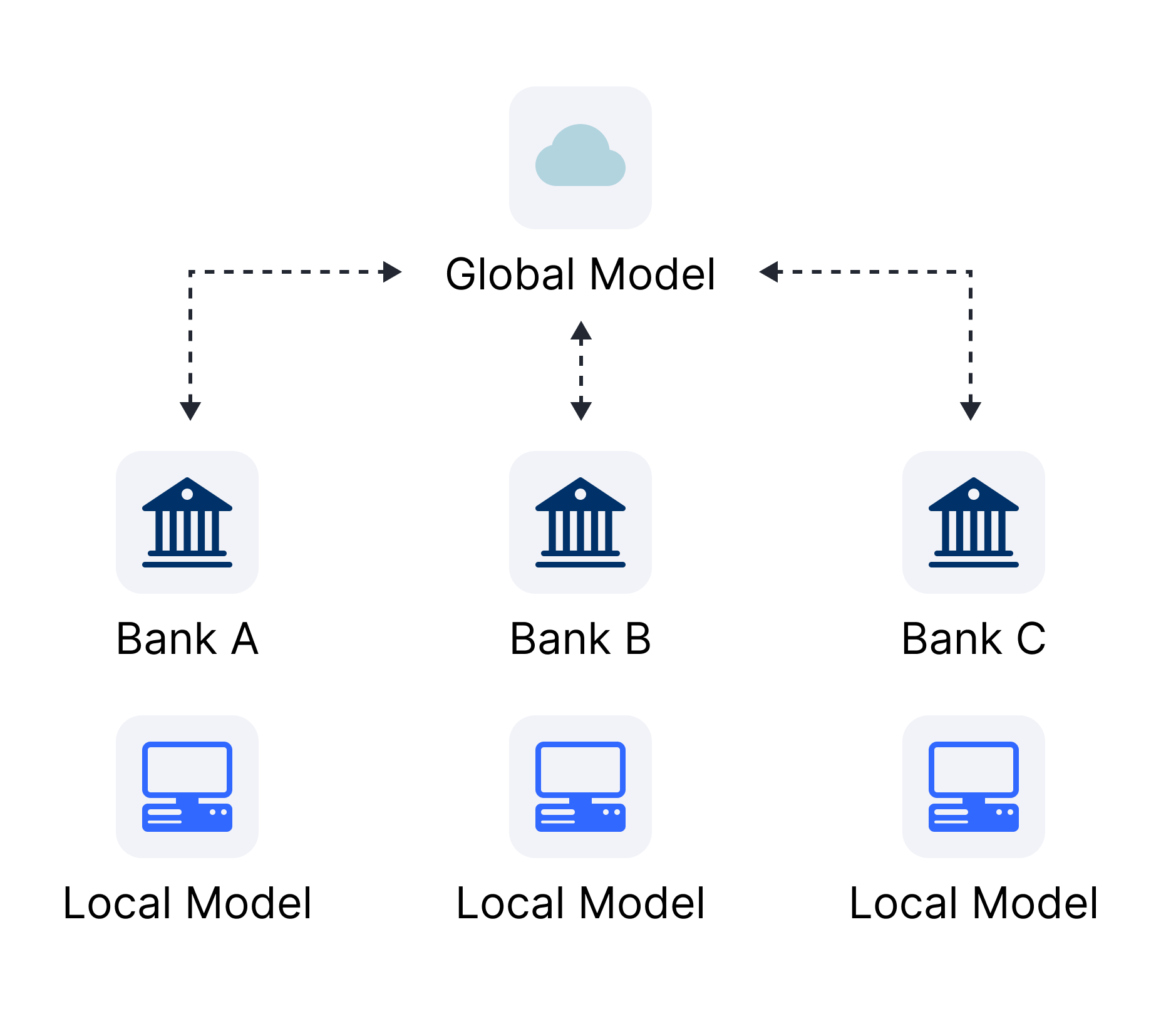
Figure 1: Horizontal Federated Learning for Detecting Mule Account Fraud. Each participating bank holds the same feature set but a different set of clients. Each bank trains a local model on its own data. The models are then securely aggregated into a global model without sharing any sensitive customer information, enabling collaborative fraud detection while preserving data privacy and compliance.
About the Dataset
To evaluate the applicability of horizontal federated learning for mule account fraud detection, we used the Bank Account Fraud (BAF) dataset suite. The BAF dataset
simulates real-world fraud scenarios while allowing controlled experimentation with different types of bias and distributional shifts. The dataset suite consists of a base dataset (where no bias was induced in the sampling process) and five controlled variants (I to V), each designed to represent specific biases and operational challenges, such as group imbalance, prevalence disparity, or temporal shift. The suite is composed of those 6 datasets, each one with 1M instances, for a total of 6M instances, each labelled to indicate fraudulent or legitimate behaviour. These records span a diverse set of customer demographics, transaction behaviours, and account activities. Each data point includes 31 features, covering both numerical and categorical variables, and one boolean target variable indicating Fraud or Not Fraud.
Traditional models trained on static, imbalanced datasets risk poor generalization and biased outcomes, resulting in missed fraud or unfairly denied accounts. By testing federated models across these diverse bias settings, this use case exemplifies a Responsible AI approach that prioritizes robustness, fairness, and adaptability. Below is the summary of the variants, each designed to simulate specific biases commonly encountered in financial fraud detection settings:
| Variant I | Group Size Disparity | One group is underrepresented, making generalization harder in imbalanced setting |
| Variant II | Prevalence Disparity Bias | Fraud rates differ across groups of equal size, challenging model generalization. |
| Variant III | Separability Bias | Features correlate with protected attributes, leading to shortcut learning and the need for robust training. |
| Variant IV | Temporal Prevalence Bias | Fraud prevalence changes over time, testing model robustness and time shifts. |
| Variant V | Temporal Separability Bias | Feature-label relationships drift over time, requiring adaptable models for long-term use. |
*Note: Variant III and V include synthetic features X1 and X2 to induce separability bias but were excluded from modeling.
**More details on the data can be found on their data sheet.
Methods and Experiments
To apply Federated Learning (FL) to the dataset, we structured the experiments in
four stages.
- First, we developed a base neural network to predict fraud using Base dataset. This model was trained using Focal Loss to address the significant class imbalance present in the data. Training was conducted for 25 epochs using a batch size of 32.
- We trained five “solo” models independently, one per variant, using a standard 70/30 train-test split. These served as baselines.
- For the FL setup, we used the same model architecture and preprocessing steps and trained the federated models using 25 server rounds and one local epoch per round. Evaluation focused on fraud-specific metrics, particularly recall at 5% false positive rate (FPR), which is commonly used in fraud detection settings.
- We experimented with two FL algorithms: FedAvg, the standard method that averages client weights at each round, and FedProx, which introduces a proximal term in the loss function to mitigate the effects of client drift and heterogeneity by keeping client updates closer to the server model.
Results
To assess the impact of Federated Learning (FL), we compared the performance of models trained in three settings across five bank variants: (1) individually trained solo models, (2) federated models using FedAvg, and (3) federated models using FedProx. We evaluated each model on the recall at 5% FPR metric. Results are summarized in the tables below:
Solo Models (Trained individually Per Client)
Each client trained their own model using local data, with no collaboration. The performance varied based on the underlying data distribution of each client. Local-only training produced reasonable results but was limited by data availability and generalization capacity.
| Client | Variant 1 | Variant 2 | Variant 3 | Variant 4 | Variant 5 |
| Recall at 5% FPR | 0.55 | 0.62 | 0.57 | 0.59 | 0.55 |
Federated Learning with FedAvg
With the FedAvg approach, models are trained collaboratively across clients by averaging updates after each round. This setup led to notable improvements in performance metrics for all clients.
| Client | Variant 1 | Variant 2 | Variant 3 | Variant 4 | Variant 5 |
| Recall at 5% FPR | 0.61 +(0.06) | 0.64 +(0.02) | 0.61 +(0.04) | 0.66 +(0.07) | 0.59 +(0.04) |
*() indicates the improvement from the solo models
FedAvg enabled clients to benefit from shared patterns learned across institutions, leading to stronger performance compared to local training. The algorithm performed particularly well for Variant 4, which had a temporal prevalence bias. With federated learning, the model was better able to learn the fraud patterns over time.
Conclusion
Across all evaluation metrics, both FedAvg and FedProx demonstrated improved performance compared to the solo models trained on individual clients. The use of FedAvg led to clear gains in recall, ROC-AUC, and F1 score, indicating that shared learning across clients helped generalize better to fraud patterns, even without direct data sharing. While the FedProx algorithm did not provide further improvements in these experiments, further tuning and a different experimental environment could produce different results. These results affirm that federated approaches not only preserve privacy but also enhance performance.
Future Work
In the BAF dataset used, each client is generated independently. This means there were no relationships across and within variants. Transactions-based data more closely models real life, where clients interact with each other and with merchants. It would be interesting to explore how well a Federated Learning model performs in this more complex environment. One possible public dataset that provides these scenarios is the PaySim dataset.
References
- Fraudio. (n.d.). Money mule detection. Retrieved May 5, 2025, from Fraudio
- Jesus, S., Pombal, J., Alves, D., Cruz, A., Saleiro, P., Ribeiro, R. P., Gama, J., & Bizarro, P. (2022). Turning the tables: Biased, imbalanced, dynamic tabular datasets for ML evaluation. Advances in Neural Information Processing Systems. https://doi.org/10.48550/arXiv.2211.13358
- Emerson, D.B., Jewell, J., Ayromlou, S., Carere, S., Tavakoli, F., Zhang, Y., Lotif, M., Fajardo, V. A., & Krishnan, A. FL4Health (Version 0.3.0) [Computer software]. https://doi.org/10.5281/zenodo.1234
- E. A. Lopez-Rojas , A. Elmir, and S. Axelsson. “PaySim: A financial mobile money simulator for fraud detection”. In: The 28th European Modeling and Simulation Symposium-EMSS, Larnaca, Cyprus. 2016