
Introduction
Initially used in relatively lower risk industries such as consumer electronics, home appliances and online advertising, machine learning models are making their way into higher risk industries; automotive, healthcare, finance and even justice systems. While working on problems in these high risk industries where people’s lives are affected, machine learning practitioners have to take special care while developing ML models. At RBC Borealis, our mission is to responsibly build products and technologies that shape the future of finance and help our clients at RBC succeed. During our journey to execute on this mission, we have seen a rapid adoption of ML models in the financial industry. To reduce the risk that this wide adoption of ML models poses, Enterprise Risk Management (ERM) groups in many institutions have been coming up with new ways of validating these models.
In a previous blog post, we talked about how AI brings a host of new challenges which require enhancing governance processes and validation tools to ensure it is deployed safely and effectively within the enterprise. In a more recent blog post, we shared our approach to validation and introduced our model validation pipeline. Over the last year, our team took our model validation process (shown in Figure 1) and incorporated it into a developer-facing software platform that guides the user through the validation process. As we implemented our model validation pipeline, we encountered several engineering challenges. In this blog, we will talk about some of these and provide some insight as to how we tried to address them. In the following sections, we will cover some of the challenges we faced in our journey to develop this pipeline. Keep in mind that most of our models are for classification tasks and use tabular datasets. However, many of these ideas could be extended to other ML tasks.
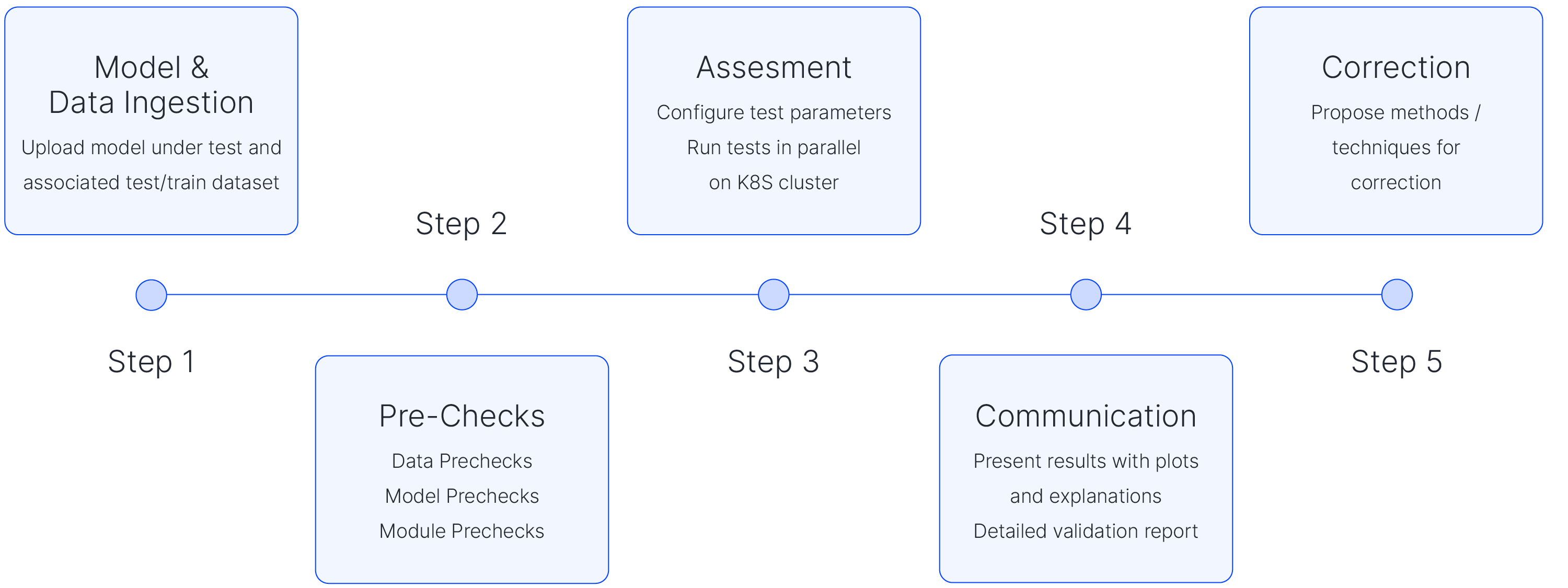
Figure 1: Model validation pipeline.
Model and Data Ingestion
Whether you’re developing a model validation library or an automated validation service, there are some challenges you might face when trying to load/ingest the user model and dataset. In the case of a library, ingestion might be trivial since the model developer or validator will directly use the package using their own development environment. Data ingestion gets more challenging when the validation pipeline is deployed away from the client’s environment. Here are some things to watch out for in the case of an automated validation service:
- Compliance and security regulations: Ensure that the users do not use the validation services with any data containing sensitive information. Even if the data is obfuscated, make sure to employ best practices when handling user data and delete the data at the end of the validation cycle. If working in an organization with a dedicated data team, get them involved early in the process to find the most optimal way to create the data pipeline and follow the best practices.
- Dataset size: Decide on a reasonable limit for dataset size that would work for your use case. Ideally, you want the users to be able to use their whole train/test dataset. However, test execution time grows with the size of the dataset and it might become infeasible to perform tests using the entire dataset. We implemented specific sub-sampling strategies for certain validation tasks since running them on vast datasets was not feasible. It is crucial to advise the user about such cases so they can configure the validation tests accordingly.
- Dataset file format: Use pandas or a similar data manipulation library that can load many different file formats used across the industry. Do not use pickle files as they pose a security risk.
- Incorrect formatting in the dataset: Check if the dataset is correctly formatted. We ran into many issues exclusively related to problems with the dataset and often times, it was because the dataset was not pre-processed properly. To address this issue and many more, we have added a step called “Pre-checks”, which help identify problems before executing any tests and running into issues in the downstream processes or potentially getting faulty results.
- Model ingestion: If your pipeline requires a model to be provided by the user, ensure that the model representation you chose to support works for all the models used in your organization. If your organization is committed to employing a specific deep learning framework only, you can choose to only use the model representation provided by that framework. However, the best option is to use an open source model representation framework adopted by most modern machine learning frameworks such as ONNX.
Pre-checks
This step aims to make sure that the user’s model and dataset pass all the requirements before assessment. Pre-checks ensure no unexpected errors occur during the actual assessment, which might be computationally expensive. We found it helpful to separate this step into three parts; data pre-checks, module-specific pre-checks, and model pre-checks. In each of these steps, we perform various checks and provide a list of warnings and errors if found.
It is also quite helpful to distinguish between errors and warnings to separate issues that are purely informative from those that would simply break the tests. For example, the validation pipeline will stop if we find errors or incompatibilities with the test requirements, and the user will not be able to continue unless these are resolved. In comparison, warnings are meant to inform the model developers about potential issues that might be present in their data, such as data imbalance, low feature permutability, high correlation between features, and missing values.
Data Pre-checks
Before validating the model, it is often helpful to check whether there are any issues with the dataset because most problems with ML models originate from the dataset. The checks mentioned in this section are ideally accounted for before model training, but we warn the model validators in case they have not been addressed.
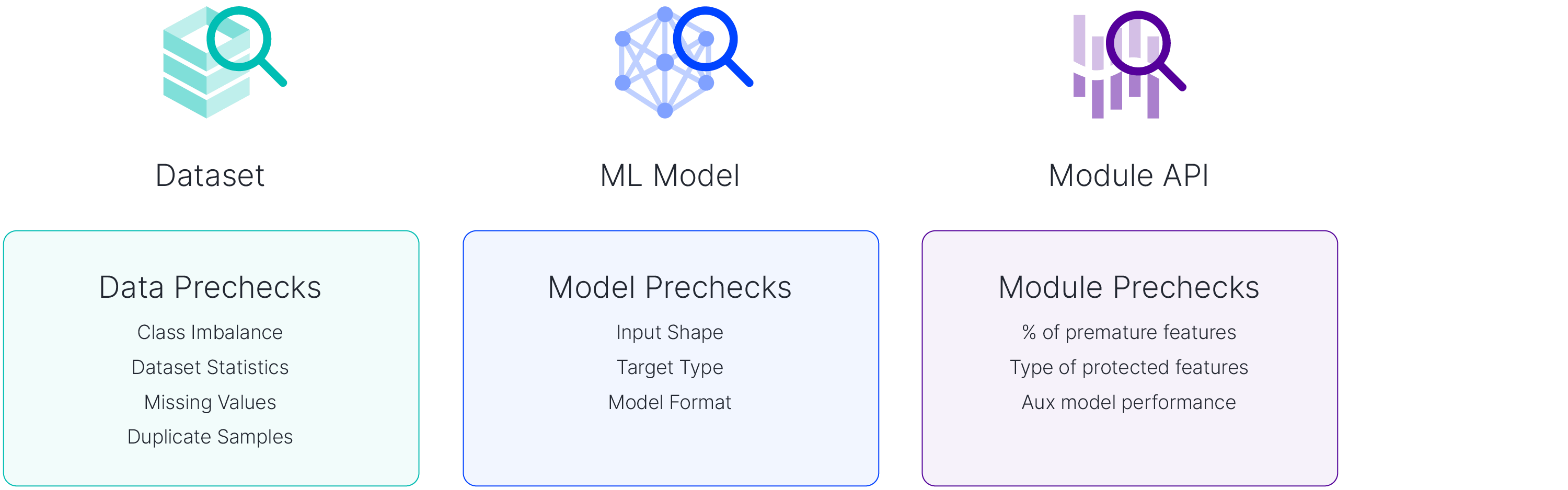
Figure 2: List of pre-checks performed on user model and dataset.
- Class imbalance: Detect whether each class is equally represented in the dataset. Imbalance is a common issue, and it could be expected in a lot of cases. However, this information plays a crucial role in understanding the test results. For example, it might be more important to observe the behavior of the class with fewer data points when checking for robustness in case there is a severe imbalance.
- Missing values: Report the number of samples with missing values. Depending on the ML model used, the data points with missing values could cause errors during the assessment.
- Duplicate samples: Report the number of duplicate samples. These are typically removed as they might cause over-fitting. There might be cases where duplicate samples are allowed, but they are relatively rare.
- Dataset statistics: Gather statistics of the dataset such as correlation, variance, and coefficients of variation. If there is a need to remove some features, model developers can consider removing a feature if it shares a high correlation with another feature. This might be especially useful in light of some adversarial robustness assessment if some features are found to be risky/sensitive and should be considered for removal. If there are a lot of features with high correlation, this might also indicate poor data pre-processing prior to model training.
Model Pre-checks
Model pre-checks verify that the model under test satisfies all the requirements, which are mostly imposed by the limitations of the validation framework.
- Model input shape: Ensure that the model input shape matches the number of features in the provided dataset.
- Target type: Ensure that the model output matches with the target type i.e. binary classification, regression, multi-class etc.
- Model format: Ensure that you can load the model and it is one of the supported model types.This check depends heavily on how the model validation framework is structured and what type of tests are being performed i.e., white box, gray box, or black box testing. In our use case, we initially started our framework with a limited number of models that we decided to support. In that instance, we would need to perform this check to ensure that the model format matches one of the supported models (PyTorch, XGBoost, LightGBM and Scikit-Learn models). As our use cases grew over time, we progressively moved towards a model-agnostic approach.
Module Pre-checks
Conceptually module pre-checks are meant to detect any issues users might run into when running specific validation tests, which we refer to as modules. Since these are application specific, they will vary significantly from one particular test to the next. Therefore we will provide some example pre-checks that we use rather than giving any high-level guidance.
- Percentage of perturbable features: Return the number of real-valued features. In our adversarial robustness testing, only real valued features can be perturbed and are therefore relevant.
- Protected feature type: Check whether the user-specified protected feature is a binary feature which is required for our individual fairness test.
- Auxiliary model performance: Ensure that the auxiliary model used in individual fairness testing has a reasonable performance. For more information on our individual fairness testing, you can check our previous blog post on
fAux: Testing Individual Fairness via Gradient Alignment.
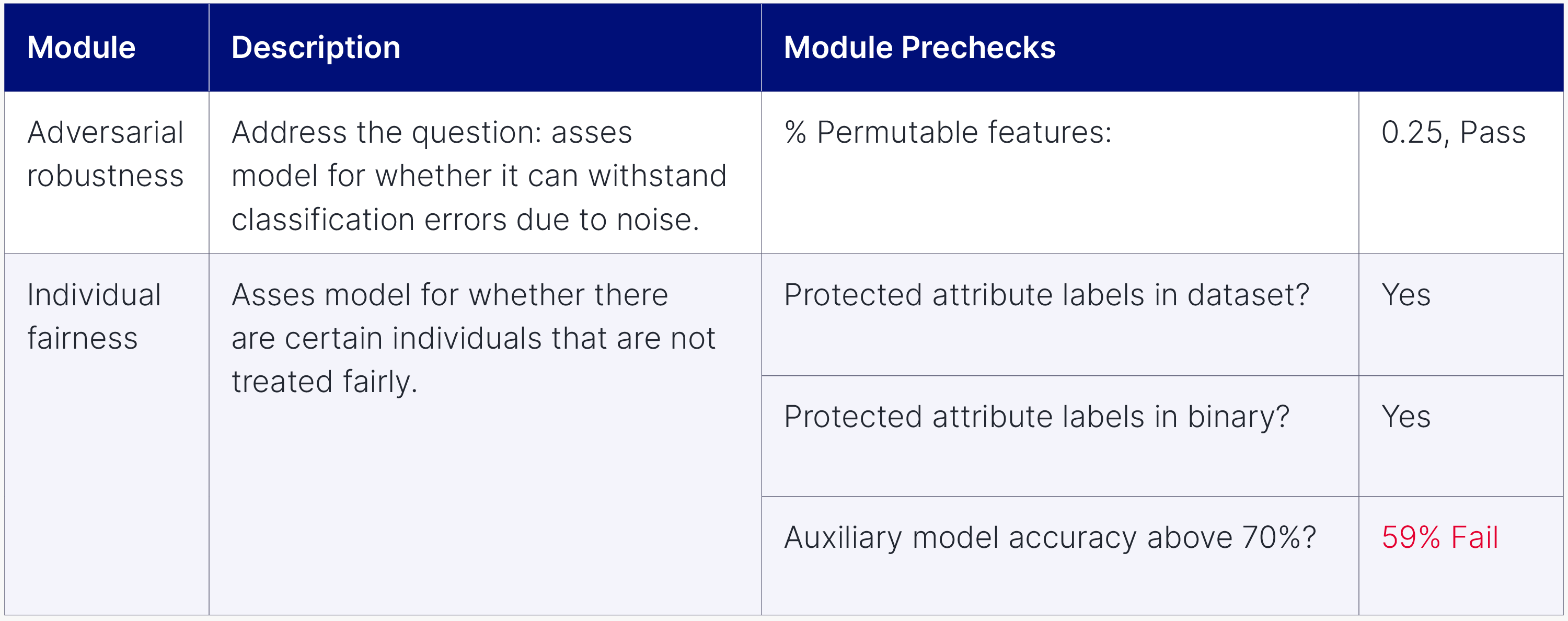
Figure 3: User is presented with a summary of module pre-checks before proceeding with the tests. Some pre-checks will not allow the user to continue whereas others are presented as potential weaknesses.
Assessment
One of the major challenges anybody will face during model validation is the lack of sufficient computing power. ML model validation is a very time-consuming process because hundreds of tests need to be run during the assessment process. For adversarial robustness alone, the search for adversarial examples could take more than a day for a large dataset, and it might need to be repeated with different hyper-parameters to find the suitable configurations for a given model. Furthermore, adversarial robustness is only a single test in a long list of rigorous tests validators have to go through to reduce risk. Therefore it is vital to keep scalability in mind when designing a framework for model validation. Our validation tests are designed so they can be performed in batches which allows us to use multiple workers when performing validation on large test sets. To further alleviate some of the computational challenges, we have designed an automated validation system that could perform validation testings on our clusters in a distributed fashion. The automated workflow itself poses many different challenges as it adds some limitations in terms of what the validators can do. However, it creates the flexibility for the validators to run multiple tests in parallel with no manual intervention.
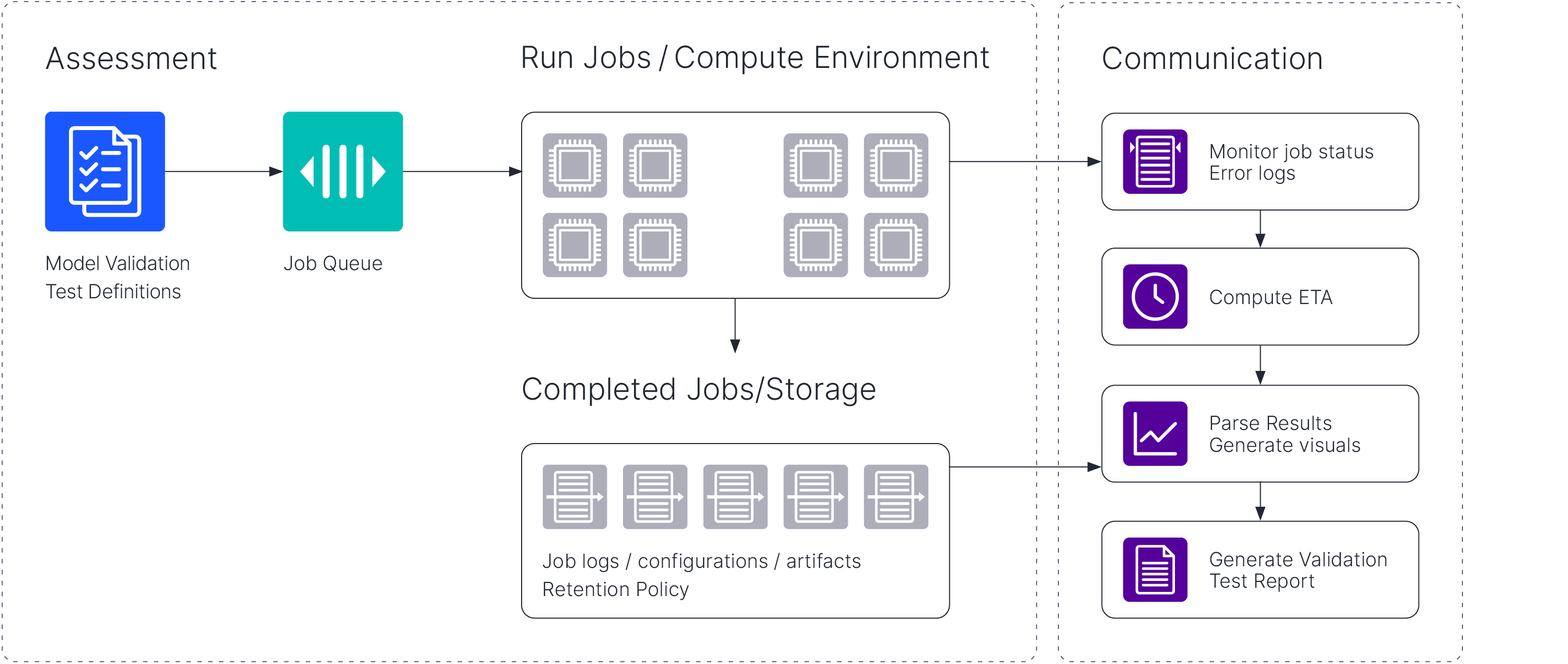
Figure 4: Model validation tests are run as jobs and the test results are stored in a storage with a
short-term retention policy unless marked for immediate deletion by the validators.
Communication
When we talk about communication, we refer to many different ways in which we relay some information to the end user. These can vary from logs to monitor the status of the validation tests to visuals generated to present the results of these tests. We have integrated both monitoring and reporting capabilities into our automated validation pipeline. Users can track the progress of the batch jobs during the assessment step as shown in Figure 4. These jobs can be very long-running. Therefore, it is helpful for the users to receive regular updates on the progress, such as the number of batches completed, the number of adversarial examples found, and the errors encountered if there are any. Based on these logs from running jobs, we also provide an estimated time to complete the validation. The results are parsed after the jobs are complete, and the test results become available. Finally, we offer the option to generate a validation report at the end. The validation report incorporates technical background on the methods used, a summary of all the results, visuals that were generated and explanations on how to interpret the visuals.
The communication step is one of the most important and arguably the most challenging step to design in the entire workflow. It is not a technical challenge but rather a design challenge. If the output of the tests are not easily understood by the validators, the value of these tests provide significantly diminishes. Therefore, the biggest challenge in this step has been finding ways to communicate the results in an intuitive way to the end users. Unfortunately, what is intuitive to us is not always intuitive to our users.
In order to tackle this challenge, we have been iterating and improving the way we communicate our results through many user feedback sessions. You can find out about the metrics and some of the visuals we have been using in presenting our validation results in the adversarial robustness and individual fairness blog posts.
Conclusion
In this blog, we covered some of the engineering and design challenges we have faced while taking on the task of ML model validation. We aim to help both the model validators and model developers test their models with the tools we have developed. We hope to achieve faster model development cycles while minimizing the risk by closing the gap between the developers and validators and providing them with the right tools at every step of the product development cycle.