
In part I of this blog, we presented a taxonomy of explainable AI methods (figure 1), and we discussed methods that take a pre-existing model and provide a local explanation about how a particular input example was classified. In this blog, we discuss the remaining three types of approaches to explainability.
First, we discuss global post-hoc explanations where we have a pre-existing model and want to provide insight into its global properties. Second, we discuss approaches that approximate the original model with a proxy model that is easier to understand. Finally, we discuss building models that are inherently interpretable in the first place.
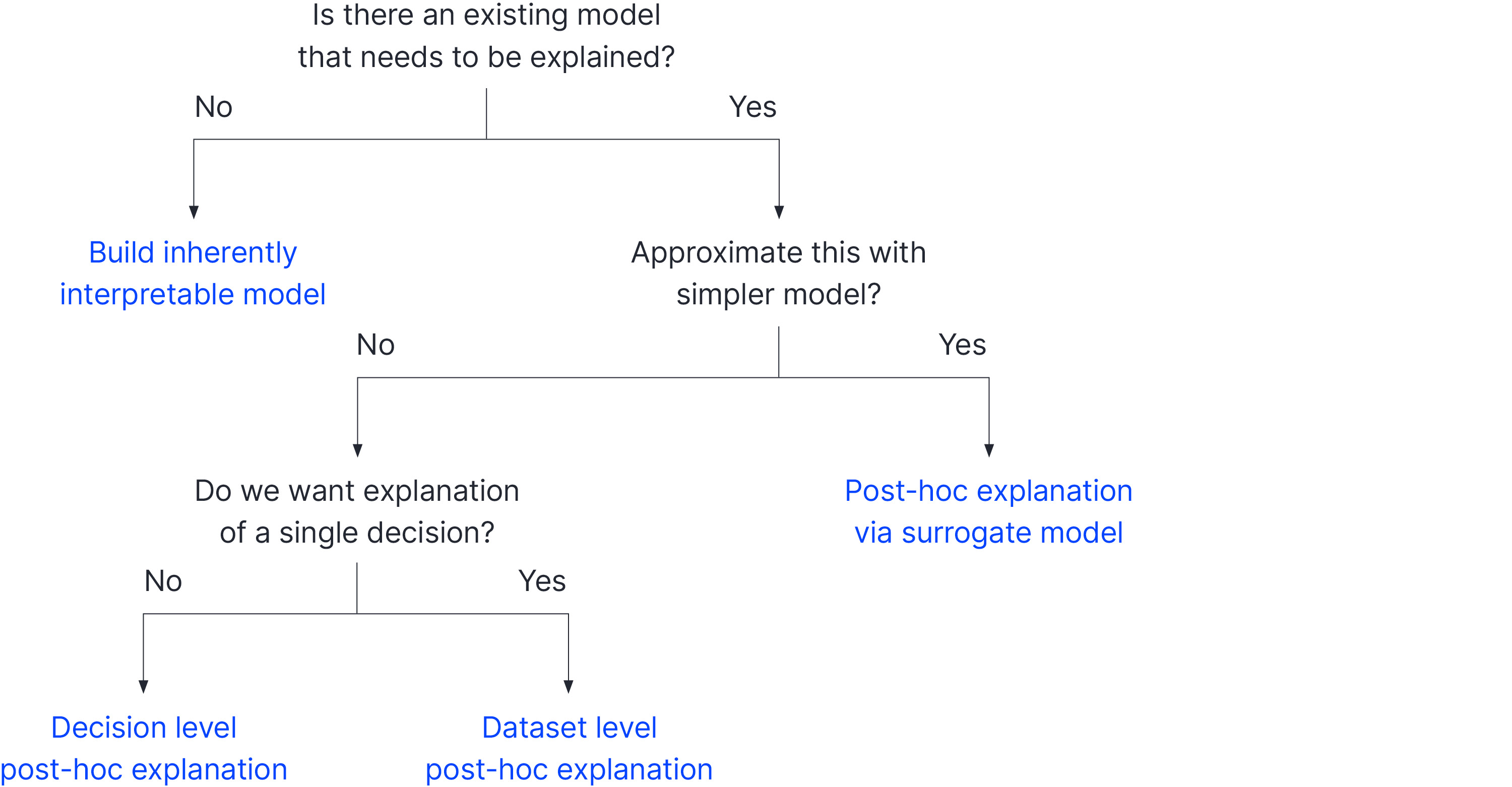
Figure 1. Taxonomy of XAI methods. If we do not already have a model that we need to explain, we can develop a model that is inherently interpretable. If we already have a model, then we must use a post-hoc method. One approach is to distill this into a simpler and more interpretable model. However, if we only use this for explanations, then the explanations are unreliable to the extent that the results differ. If we replace the original model entirely, then we may sacrifice performance. If we decide to work with just the existing model, then there are two main families of methods. Local models explain a single model at a time, whereas global models attempt to explain the entire model behaviour. See also Singh (2019).
Global post-hoc models
Global post-hoc models aim to take an existing but un-interpretable model and provide an overview of its behaviour which is easier to understand. This often involves considering the aggregate effect of individual features or pairs of input features. In this section, we review a number of methods of this type.
Global feature importance
One of the simplest ways to understand a model is to measure the overall importance of each input feature. Breiman et al. (2001) propose shuffling the values of the feature of interest across the training or test set and then re-measuring the performance of the model. The shuffling procedure breaks the relationship between the input and the output. If this makes no difference, then this suggests the feature is not being used to make the prediction (figure 2).
A closely related approach adds noise to each input rather than permuting the values ( Yao et al., 1998; Scardi and Harding, 1999 ). This has the advantage that it is less likely to generate combinations of features that are not realizable in practice but has the disadvantage that it modifies the marginal statistics of the feature.
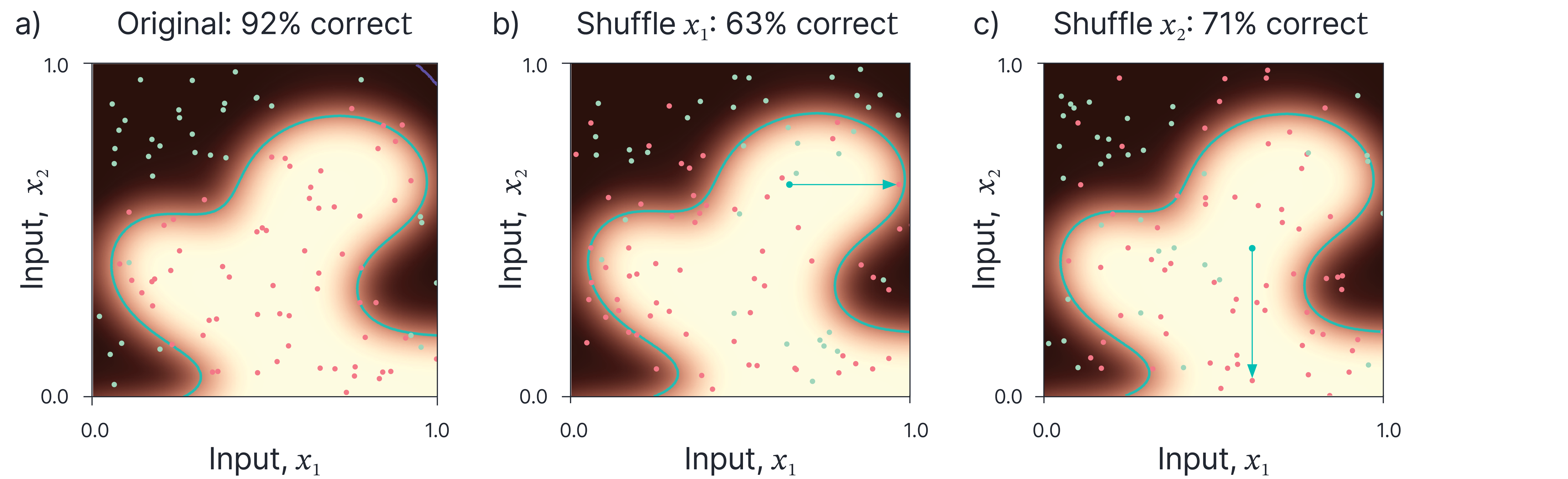
Figure 2. Global feature importance. One way to rank the importance of the features is to systematically remove the contribution of each feature in turn and see what effect this has on the model. a) Original data is classified $92\%$ correct. b) If we shuffle the $x_{1}$ values between the examples, the performance drops to $63\%$ correct. The Blue arrow shows movement of one point due to this perturbation. b) If we shuffle the $x_{2}$ values, then the performance drops to $71\%$ correct. We conclude that both features are important, but $x_{1}$ is more important. Note that the exact result will vary depending on the random shuffling, so typically, this would be done many times, and the results averaged.
These methods are also subject to the criticism that they do not fully take into account interactions between features; if several features are very correlated, then the model may distribute its dependence on them; removing any one of them may have a small effect even though they individually contain enough information to drive the model and their relative contribution is really an artifact of the training process.
Partial dependence plots
The methods in the prior section tell us something about how important each feature is, but not how the output varies as we manipulate the feature. In Part I of this blog, we described the individual conditional expectation (ICE) method. This provides a local explanation of a model by showing the effect of modifying a single feature (or sometimes a pair of features) while keeping the remaining ones constant. Partial dependence plots (Friedman, 2001) are the global analogues of individual conditional explanations. However, rather than explain the effect of changing a feature for a single data example, they show the aggregate variation over all of the training points.
More formally, the ICE plot for feature $x_{1}$ in a model with output $y$ conditions on the point $x^*$ and depicts $Pr(y|x_{1}, x_{2}=x_2^*)$. The partial dependence plot marginalizes over all the other features except the one under consideration and so depicts $Pr(y|x_{1})$. In practice, this is done by taking every data point, varying $x_{1}$ over the whole range while keeping the other variables constant and then averaging the resulting plots.
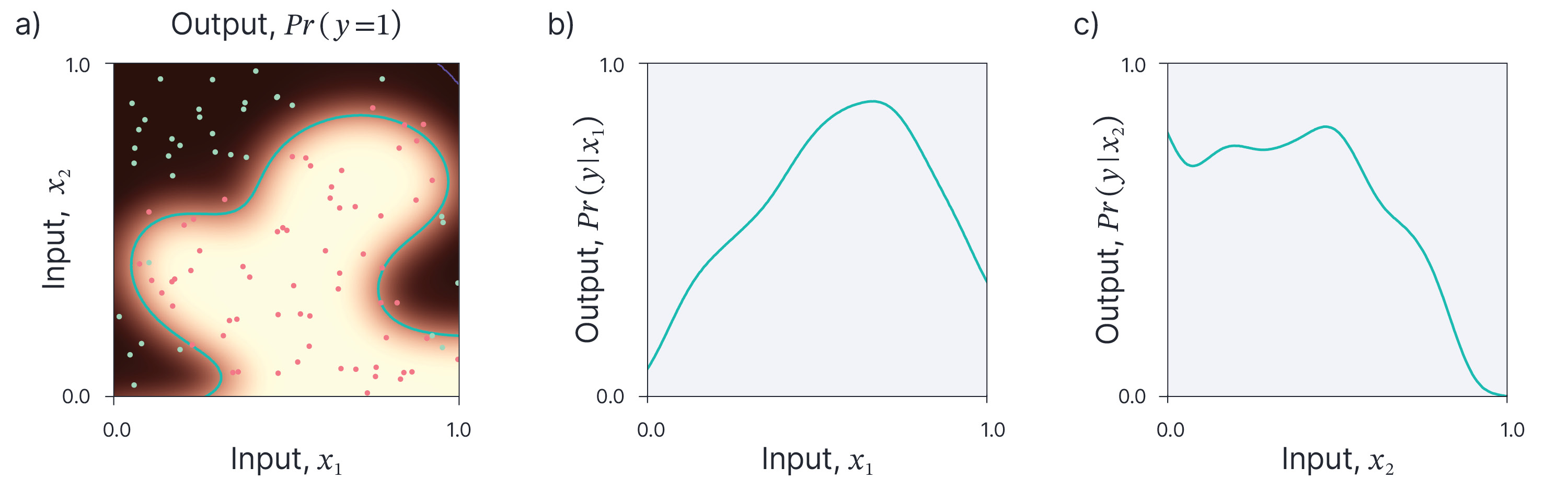
Figure 3. Partial dependence plots show the average behaviour of the dataset as we vary each dimension independently. a) Fitted model with data points. b) Partial dependence plot for features $x_{1}$. c) Partial dependence plot for feature $x_{2}$.
This technique is simple but is subject to the same criticism as ICE plots; it does not describe the interaction of the features. Indeed, the partial dependence plots may average out very different behaviours of the individual points. For example, if for some values of feature 1, the output increases with feature 2 and for other values of feature 1, the output decreases, then the partial dependence plot may imply that feature 2 does modify the output.
Family of ICE plots
In fact, it is in some ways, preferable to illustrate the aggregate behaviour of a model is to show ICE plots for all of the training data points simultaneously (figure 4). Often, these are aligned at a certain point (most commonly the start of the feature range), to help visualize the changes (figure 5).
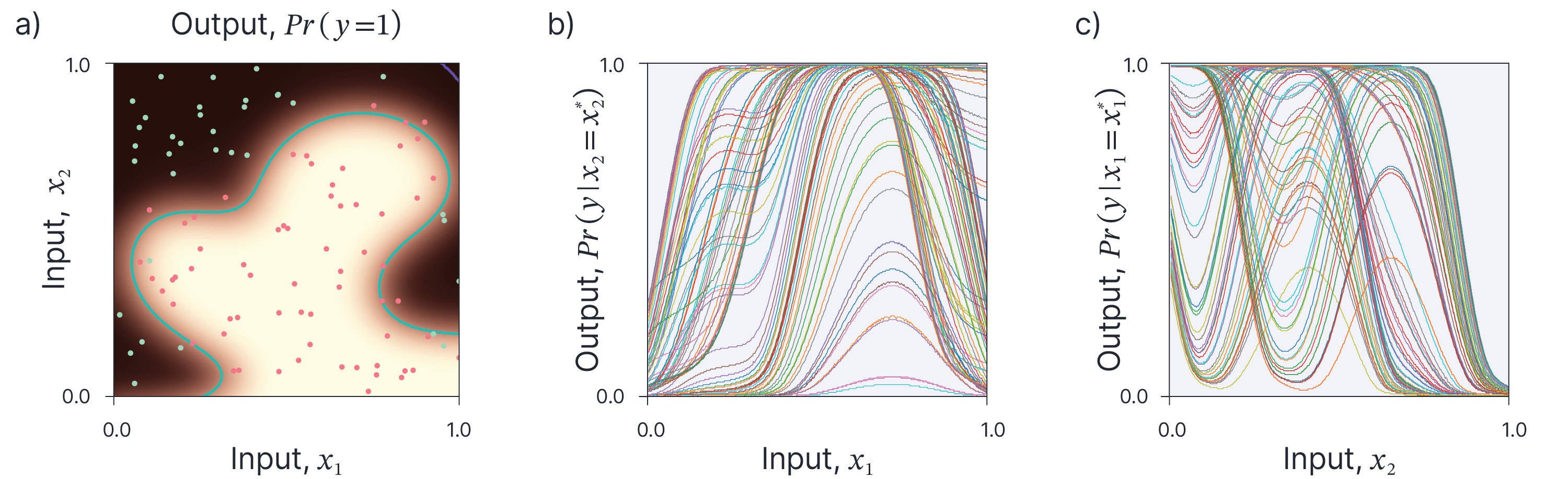
Figure 4. Individual conditional expectations for whole training set. a) The original model and the training points. b) We can get a sense of the overall effect of feature $x_{1}$ by superimposing ICE plots for many different points (here the whole training set. We can see low values of $x_{1}$ generally result in negative classification so $Pr(y)<0.5$, intermediate values usually result in positive classification and large values produce a variety of results. c) Superimposed ICE plots for feature $x_{2}$.
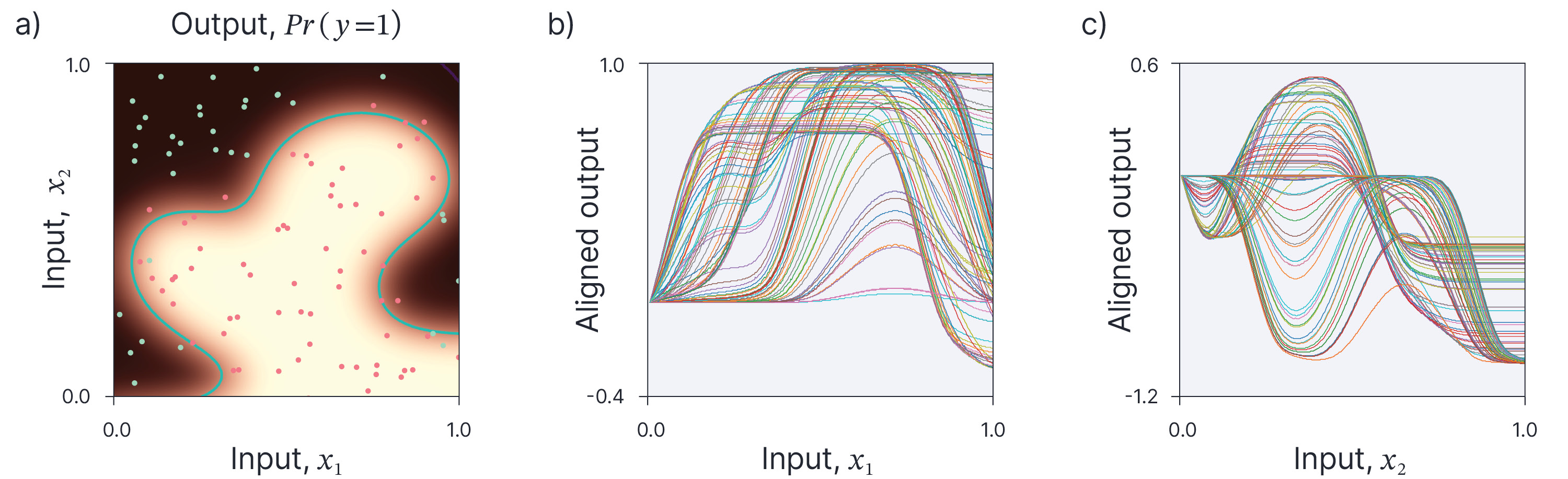
Figure 5. Aligned Individual conditional expectations for whole training set. a) Original model and training points b) Sometimes, we can better visualize the effect of a feature by aligning all of the curves at some point (here $x_{1}=0$). c) Aligned curves for feature $x_{2}$.
Accumulated local effects (ALE)
One possible criticism of both partial dependence plots and ICE plots for the entire training set is that in each case, we may include positions in the feature space that do never occur in practice in the results. For example, consider the case where two features are closely correlated. If we fix one of these features and vary the other over its entire range (either for individual curves in ICE plots or to contribute to an average in partial dependence plots), we will inevitably move to positions in the input space that never really occur (figure 6). The model here may give atypical results as it has never seen inputs of this type. Accumulated local effects or ALE Apley and Zhu, 2019 attempts to compensate for this problem by only moving the variable of interest within its vicinity and measuring the effect on the output.

Figure 6. Feature correlation. Imagine that all of the training data lie close to the diagonal, so as $x_{1}$ increases, $x_{2}$ decreases. If we shuffle one of the input variables to assess global feature importance or vary it over the possible range to computed PDP or ICE plots, then we will inevitably wind up evaluating the function far from the diagonal. The function may do anything in this region, but it is not useful to understand this since data points do not occur there in practice.
ALE uses the following procedure to investigate the effect of feature $x_{1}$ (figure 7). First, $x_{1}$ is divided into a set of fixed-size bins. For every example in a bin, we change the value of $x_{1}$ to the maximum value of the bin and to the minimum value of the bin while keeping the other features constant. We compute the difference of these two points to get an estimate of how the model changes with small local perturbations to $x_{1}$. We average these differences for all examples within a bin. Finally, we plot the cumulative change to the output variable as we increase $x_{1}$ from the minimum value (i.e, we re-integrate the differences).
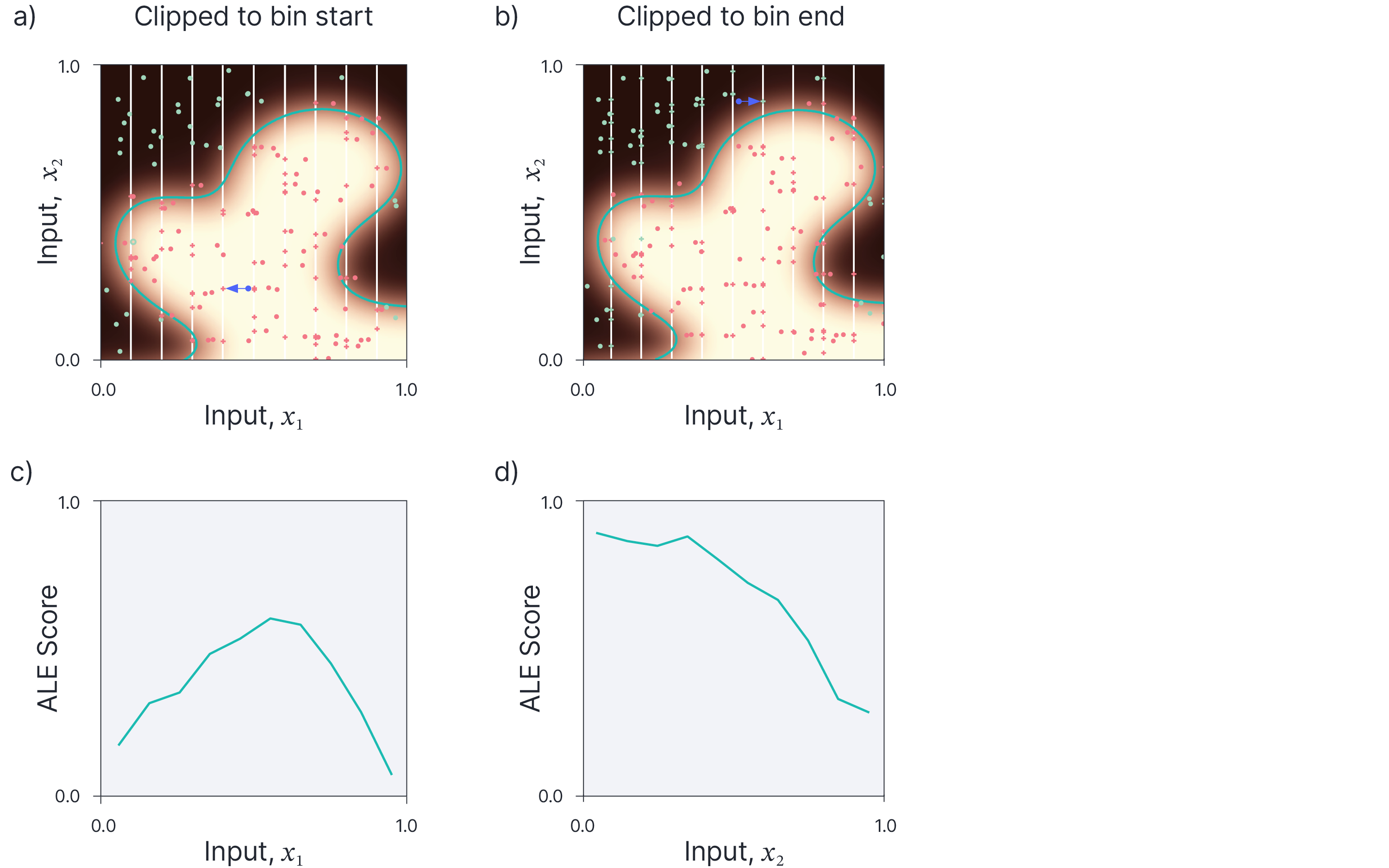
Figure 7. Accumulated local effects (ALE). a) The variable of interest is divided into $K$ bins (white lines show boundaries). Each data point (circles) is modified so that it is clipped to the start of the bin (crosses). Blue arrow shows movement of one point. b) Each data point is also moved to the end of the bin (crosses). Blue arrow shows movement on one point. c). The ALE plot for $x_{1}$ is computed by taking the average difference between the two modified points within each bin. This shows how the data changes as we move from bin-to-bin and the cumulative sum of these differences is plotted to give an overview of the effect of the variable. d) The ALE plot for variable $x_{2}$.
This method has the advantage that every point is only moved locally, and so it is not possible to venture into parts of a space that are far from the true data distribution.
Aggregate SHAP values
In part I of this blog, we introduced SHAP values. For a given data example, SHAP values ascribe a numerical value to every input feature that collectively sum (together with an overall mean) to the recreate the model output. One way of understanding the overall effect of model is to visualize them for every data example as in figure 8.
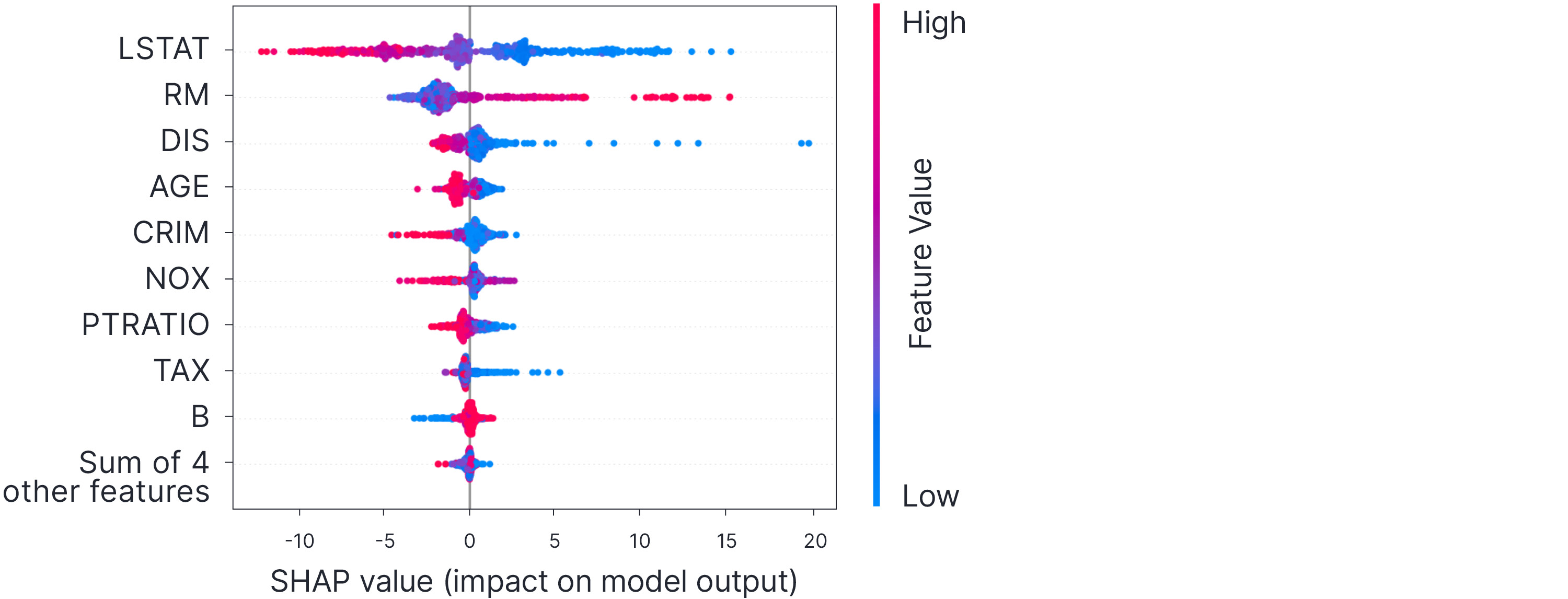
Figure 8. Shapley additive explanations (SHAP). We can plot the SHAP values for all of the data points to get an overall idea of the magnitude and direction of effect of each feature. See main text for interpretation. Via Lundberg and Lee (2017).
Each row considers one of the features in the model, and each dot is a data point. The horizontal position shows the SHAP value for the feature for that data point (jittered vertically where there are many points in the same place). So, the first row shows us that feature LSTAT often has a large contribution to the model (the absolute values of the SHAP values are large, and so the row is horizontally stretched out). When the feature value is high (red points), it tends to decrease the model output (red points have SHAP values below zero towards the left). When the feature value is low (blue points), it tends to increase the model output (blue points have SHAP values above zero, towards the right).
The feature NOX has an interesting interpretation; when the feature value is high (red points), it can increase or decrease the output (has both positive and negative SHAP values) depending on the data point. However, when it is low it does not contribute much to the model. By considering the features in this way, it’s possible to perform a reality check on models; we usually have an intuition about how a feature might affect the output and if the SHAP values plot does not agree with this intuition, it is a sign that the model (or perhaps the intuition) is wrong and further investigation is needed.
Prototypes and criticisms
One possible way to interpret a model is to summarize the input examples with a few prototypes and then return the model response for these prototypes. In this way, we can get an overview of the distribution of the input data and how it is treated by the model. Moreover, performance for individual samples can be explained by referring to the closest prototypes.
One way to fit a set of prototypes to the input data is to consider the maximum mean discrepancy between a kernel density estimate based on the original data points and another based on the prototypes. Kim et al. (2016) take this a step further by incorporating criticisms. These are a second set of prototypes that describe the parts of the input space that are not well described by the prototype model (either because they are attributed with too much or too little probability).
The effect of this is to provide a proxy dataset that represents both the data and discrepancies in modeling that data. By looking at the model output for these points, it is possible to identify areas where the model does not work well and use these to help improve the subsequent iterations (e.g., by selectively adding training data).
Global explanations with access to model internals
All of the above methods work with black-box models. They require access to the training dataset or a test dataset, but do not need to know how the model works. There are also a selection of methods that assume that we have access to the model internals. We briefly review some of these in this section.
Concept activation vectors: Kim et al. (2018) note that most approaches to explainability concentrate on explaining the model output with reference to the inputs. However, if the model input is very large (like an image), then it is not useful to summarize how the model changes when we manipulate a given pixel. Rather, we would like an explanation in terms of human-understandable concepts. For example, if an image is classified as a ‘zebra’, we might wish to know if the model is making use of the fact that zebras are striped.
To do this we first collect a new dataset of images that are tagged as containing the attribute (stripes) or not. Then we learn a linear classifier for stripes/non-stripes based on an intermediate layer of the model under investigation and find the direction that is orthogonal to the decision boundary. Finally, we find the derivative of the model output for the class under investigation (zebra)with respect to the same layer. The degree to which these two directions are aligned is a measure of how much the model uses stripes to classify zebras.
Influence of individual data points: A completely different way to gain insight into a model is to understand which training points affect the model outcome most. This may help the user understand what information that is being extracted by the model or may help identify outliers in the training data. The simplest way to do this is simply retrain the model repeatedly with a different data point missing each time. However, this is extremely time-consuming.
To remedy this problem, Koh and Liang (2017) introduced influence functions, which measure how the model parameters change when a data point is up-weighted slightly in the cost function. The basic method is to take a single Newton optimization step from the original parameter settings to get a new set of parameters that approximate the minimum of the new cost function. The difference in the parameters provides information about the influence of this point on the parameter values, and the new parameter can be used to compute a new loss to provide information about the influence of the point on the model output.
Probing deep network representations: In some cases, examining what particular layers or neurons in a deep network respond to can provide some insight into what the network is doing. At the level of layers, we gain some insight into what they represent by using them for transfer learning. For example Razavian et al. (2014) showed that the internal layers of an image classification network trained with ImageNet could be adapted to other difficult vision problems by merely adding an SVM to the final representation. Mahendran and Vedaldi (2014) attempted to visualize what an entire layer of a network. Their network inversion technique aimed to find an image that resulted in the activations at that layer, but also applied a generic natural image prior to encouraging this image to have sensible properties.
At the level of units, several methods have been proposed to visualize the input patterns that maximize the response. These include optimizing an input image using gradient descent (Simonyan et al., 2013), sampling images to maximize activation (Zhou et al., 2014), or training a generative network to create such images ( Nyugen et al., 2016). Network dissection ( Bau et al., 2017) measures a neuron’s response to a set of known concepts and then quantify how much they align with a given concept. Qin et al. (2018) provide an overview of methods to visualize the responses of convolutional networks.
Surrogate / proxy models
Another approach to understanding black-box models it to approximate their performance with a simpler and more interpretable model, which we refer to as surrogate or proxy model. In practice, this is often a linear model or a decision tree. This is usually done by running the original data through the black-box model to retrieve the corresponding model outputs and then training the proxy model using the resulting input/output pairs. This method ensures that the two models have similar performance for the original input distribution. However, it is also possible to extend this method by either modelling the input data distribution and stochastically generating new inputs or simply by randomly sampling the space.
The fidelity of the approximation can be measured by the $R^{2}$ statistic which gives a measure of the proportion of the variance in the predictions $\hat{y}$ of the original model that is described by prediction $\hat{y}^*$ of the proxy model. This is calculated as
\begin{equation} R^{2} = 1 – \frac{\sum_{i=1}^{I}(\hat{y}^*_i – \hat{y}_i)^2}{\sum_{i=1}^{I}(\hat{y}_i – \overline{\hat{y}}_i)^2} \tag{1} \end{equation}
where $i$ indexes the $I$ training examples. The numerator describes the variance of the surrogate model predictions around the original predictions, and the denominator measures the variance of the original predictions around their mean $\overline{\hat{y}}_i$.
The idea of training surrogate models dates back to at least Craven and Shavlik (1995) who
developed an algorithm to use decision trees as proxies for neural networks. DeepRED (Zilke et al., 2016) converts neural networks into to rule sets expressed as disjunctive normal forms (figure 9). It does this by first converting each layer of the net into a rule set and then integrating and simplifying these representations. Unfortunately, for large networks, the resulting rule sets are still too complex to be really interpretable. González et al. (2017) improve the efficiency of this process by sparsifying the weights in the network and encouraging the activations to be driven to extreme values. They show that the resulting rules extracting a more compact.
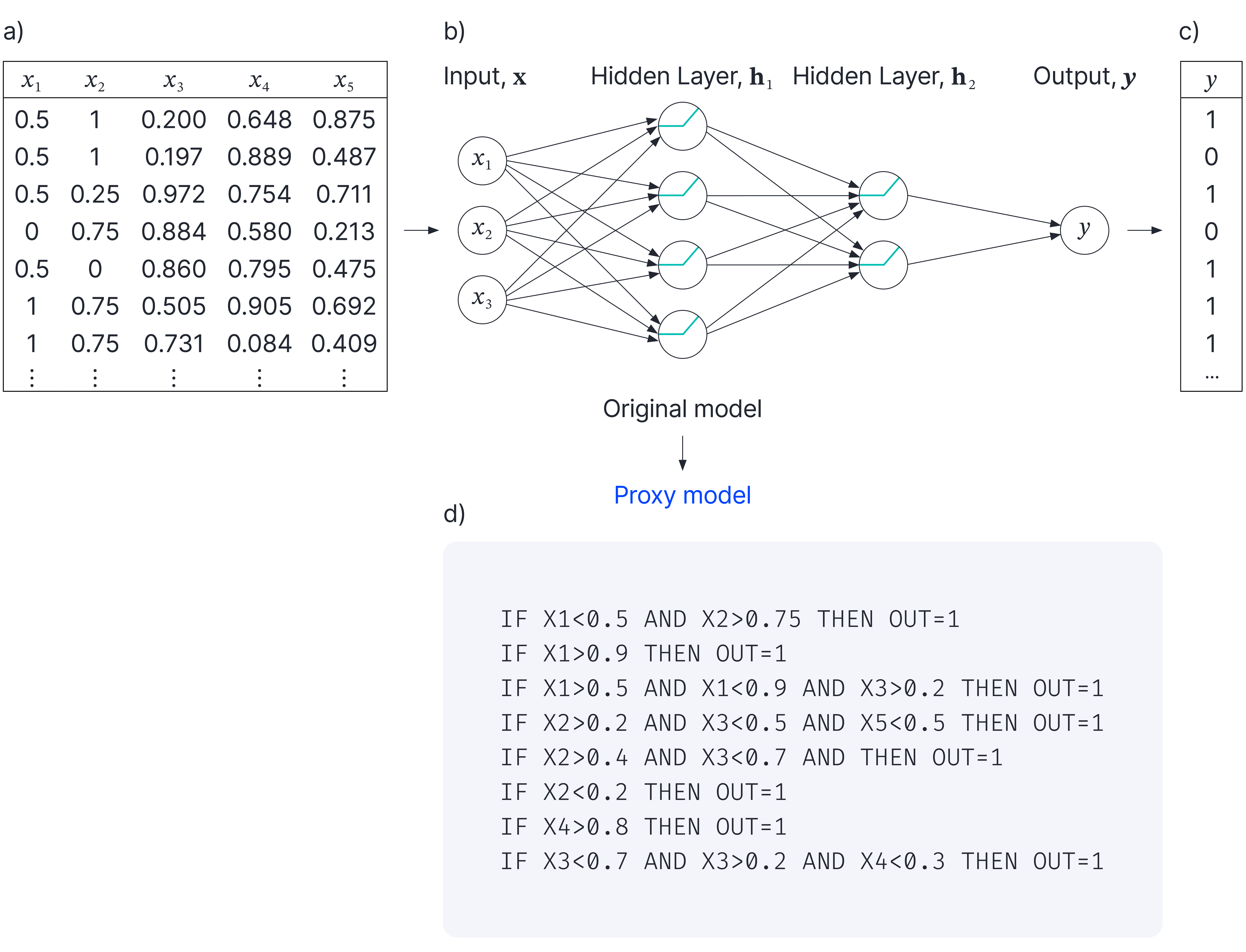
Figure 9. Surrogate / proxy models. a) Original tabular dataset is mapped by b) neural network model to c) outputs. Surrogate or proxy models attempt to replace hard-to-understand neural network model with a model that is more interpretable. d) The DeepRed algorithm is specialized to neural nets and replaces the net with a surrogate model consisting of rule sets. Adapted from Zilke et al. (2016).
Another example is Zhou and Hooker (2016) who build a single tree approximation to a random forest. They construct a statistical test that compares two possible splits based on a number of random samples that are run through the tree, with the goal of minimizing the Gini index (a proxy for label entropy). In this way they greedily choose the best approximation. They draw the samples from a Gaussian kernel smoother applied to the original samples, and so they focus more on guaranteeing behaviour where the model was originally trained.
Surrogate models are attractive because they can potentially be applied to help explain any type of model. However, they also have downsides. For very complicated models the surrogate may be unable to approximate the function at the original data points and the $R^{2}$ value will be low. Even if the approximation is good for the training data, the two models may make quite different predictions to the original model for other points due to the different inductive biases associated with different architectures. Furthermore, the $R^2$ score is an aggregate measure over the whole training data, and doesn’t guarantee the accuracy of the approximation for an individual data point. In short, these methods are subject to the criticism of Rudin (2019); if more interpretable models will do the job well, we should probably just train these in the first place.
Inherently interpretable models
The methods discussed so far all assume that we already have a model that we want to explain. If we have the original training data, then a better approach is arguably to develop a model that is inherently interpretable. Such models are sometimes referred to as glass-box models or transparent models.
Many basic machine learning models have this property. For example, linear regression, logistic regression, small decision trees and classifiers based on naive Bayes are all readily interpretable by inspection. However, these models do not generally reach the performance levels of less-interpretable systems based on neural networks. Consequently, a number of methods have been developed that are designed to be interpretable and which still give good performance. We describe several such methods below:
Scoring systems: Rudin and Ustin (2018) developed two algorithms to learn a scoring systems from data. Each consists of a set of rules, each of which yields a number of points if it is true. In the SLIM algorithm, the sum of points directly determines a binary classification. In the RiskSLIM algorithm, the number of points determines the probability over two classes (figure 10). The underlying optimization problem is a mixed-integer non-linear program but can be solved efficiently for moderate dataset sizes. They applied this method to medical diagnosis and criminal recidivism.

Figure 10. The RiskSlim method produces a simple sparse scoring systems that is interpretable and also achieves good performance.
Rules: Other work has focused on learning human-interpretable rules for classification. For example, the Certifiably Optimal Rule Lists (CORELS) system of Rudin (2019) produced the following rule set to predict recidivism:
IF age between 18 and 20 and sex is male THEN predict arrest
ELSE IF age between 21 and 23 and 2 or 3 prior offences THEN predict arrest
ELSE IF more than three priors THEN predict arrest
ELSE predict no arrestThe SIRUS algorithm (Bénard et al., 2021) generates a set of rules, each of which makes a prediction for the output variable and has an associated weight. The final prediction is the weighted sum of the individual rule predictions (figure 11). The system starts by training a random forest of shallow trees on the original dataset. They then find the most frequent rules used in the constituent trees, disregarding redundancies where some rules are subsets of others. Each rule makes a prediction, and finally they fit the weights of these rules using a regularized regression model.

Figure 11. SIRUS. A shallow forest is fitted to the data. Each node in the forest represents a rule and SIRUS retains the rules that are found most frequently across all the trees. Each rule makes a different prediction depending on whether it is obeyed or not. The final model consists of a weighted sum of the rule predictions.
Neural generalized additive models: A generalized linear additive model describes the output as a sum of simpler functions, each of which is defined on a single input feature or a pair of input features. It follows that these constituent functions can easily be visualized and hence the it’s easy to interpret both the main effect of each feature and their pairwise interactions. One way of thinking about this is that the model is entirely captured by the partial dependence plots.
Recent work by Chang et al. (2022), Agarwal et al. (2021) and Yang et al., (2021) has investigated using neural models to describe the constituent functions. These have the advantage that they are fully differentiable and so all of these functions can be learned simultaneously. The simplest of these approaches is the neural additive models of Agarwal et al. (2021) which simply processes each feature separately using a neural network before adding together the outputs of these networks to produce the prediction (figure 12).

Figure 12. Neural additive models Agarwal et al., (2021). Each input feature $x_{1}\ldots x_{D}$ is passed through a separate deep neural network, and their outputs are added together to make the final prediction $y$. This model has the advantage that it is fully differentiable, but the output of each neural network is easily interpretable.
These interpretable models can work well for tabular datasets, where there are a limited number of inputs, and each is easy to understand. However, they are not likely to be helpful for complex tasks in vision and NLP, where the input features are numerous and have a very indirect relationship with the model output.
Conclusion
In this two-part blog, we have discussed methods for explaining large complex machine learning models. In Part I, we considered methods that explain a single decision by the model. In Part II, we considered methods to elucidate the global behaviour of the model, methods that distill the model into a more understandable form and models which are interpretable by design. For a more comprehensive overview of explainable AI, consult the online book by Molnar 2022.