
Explainability has always been an important topic of interest and controversy in the AI community. Especially with the rising success of complex black-box ML models such as deep neural networks, explainability is considered a fundamental and complementary ingredient of practical AI development to address issues such as safety, fairness, and trustworthiness. This can be especially important in critical applications such as healthcare, finance, and social studies.
Machine Learning explainability can be categorized into two main paradigms: model explanation (a.k.a global explanation) and outcome/prediction explanation (a.k.a local explanation). Global explanation aims to decode the model as a whole and explain the overall logic behind it. In contrast, local explanation aims to explain the predictions for individual instances. In both paradigms, explanations can be presented in a variety of forms, such as rules, additive terms, feature importance, prototypes, exemplars, counterfactuals, expected response plots and other types of visualizations [4].
The type of required explainability depends on the target audience.
For model developers and validators, it is mostly about ML diagnostics, safety, debugging, troubleshooting, and removing bias. In fact, they want to have a holistic picture of the model as a whole and ensure it will work properly in the actual deployment. In this respect, global explanation is insightful to understand how the model works overall. Local explanations can also help to debug some failure cases in the test data. On the other hand, for model users, explainability is mostly about trustworthiness and fairness in the predictions. The users want to understand the predictions for specific instances. Here, local explanations come in handy. Note that in many practical scenarios, there are two types of users: the operators and the customers. The operators require explanations to verify the accuracy, safety, and fairness of predictions before presenting them to the customers. The explanation may also help to slightly tweak the model’s logic to improve the predictions and make the final judgement. However, the customers may require an explanation to verify if they are treated fairly or understand what they should do to change the model prediction. In this regard, European Union’s General Data Protection Regulations (GDPR) give the end users the right to an explanation for any automated decision-making [13].
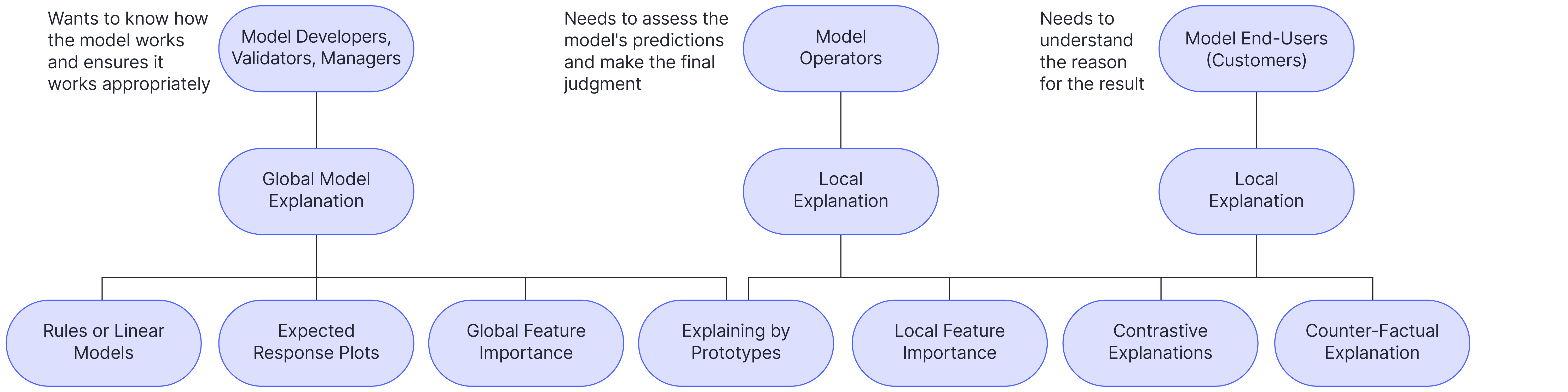
Figure 1: Taxonomy of ML explainers based on target audience.
In terms of explainability, machine learning models can be divided into two classes: glass-box and back-box models.
Glass-box models are inherently explainable by design and can provide both local and global explanations. Classical interpretable models such as decision trees, linear models, Generalized Linear Models (GLM), and Generalized Additive Models (GAM) [8] are examples of glass-box models. In recent years, there have been efforts to build inherently interpretable neural networks such as Neural Additive Model (NAM) [2], NODE-GAM [5], and GAMI-NET [14].

Figure 2: Glass-Box vs Black-Box Models.
On the other hand, black-box models require post-hoc explanation methods. Most of these explainers are model-agnostic since they can be used to explain any model. A class of these methods are mimic-based explainers, a.k.a global surrogate models. In this approach, an inherently explainable model is trained on the predictions of the actual model. For example, to explain a highly complex neural network, a decision tree or a generalized additive model is trained on the inputs and outputs of the neural network. Note that these models can provide both local and global explanations but for their own predictions, which may be different from the actual model predictions.
Another form of global explanation is presented based on marginalized response functions.
Partial Dependence Plots (PDP) and Accumulated Local Effects (ALE) [3] are post-hoc methods which try to demonstrate the expected target response as a function of features. There is also another class of post-hoc explainers based on prototypes. For example, ProtoDash [7] can explain an instance by finding the most similar prototypes from the training data. It can also provide some sort of global explanation by summarizing the training data distribution with the prototypes.
Finally, a fundamental and popular form of model explanation is based on feature importance.
Here, there are a variety of model-specific gradient-based methods (e.g., DeepLift [12] and GradCAM [11]) as well as various model-agnostic methods (e.g., LIME [10], SHAP [9], and permutation importance [6]). For example, LIME tries to learn a local surrogate linear model to provide local feature importance. SHAP is also mainly used for local explanation, but it can be modified to calculate global feature importance. Permutation importance is the most well-known method to calculate global feature importance for black-box models. It works by shuffling the values of a feature and measuring the changes in the model score, where the model score is defined based on the evaluation metric (e.g., R2 score for regression or accuracy for classification). Permutation importance, as well as LIME and SHAP, assume feature independence for calculating feature importance [1]. This is a fundamental problem with these methods, which is commonly overlooked and can provide misleading explanations when correlated features are present. For example, in the permutation importance algorithm, each feature is independently permuted, and the score change is calculated based on the individual feature changes. However, in practice, when a feature value changes, the correlated features are also changing.
To alleviate this problem, we will introduce a simple extension of the permutation importance algorithm for the scenarios where correlated features exist. The new extension works by grouping the correlated features and then calculating the group-level imputation feature importance. The group-level imputation importance is similar to the original imputation importance, except that all the features in the group are permuted together.
You can check out our release of this method on GitHub!
Test your Explainable AI knowledge by taking our quiz below.
References
[1] Kjersti Aas, Martin Jullum, and Anders Løland. Explaining individual predictions when features are dependent: More accurate approximations to shapley values. Artificial Intelligence, 298:103502, 2021.
[2] Rishabh Agarwal, Levi Melnick, Nicholas Frosst, Xuezhou Zhang, Ben Lengerich, Rich Caruana, and Geoffrey E Hinton. Neural additive mod- els: Interpretable machine learning with neural nets. Advances in Neural Information Processing Systems, 34, 2021.
[3] Daniel W Apley and Jingyu Zhu. Visualizing the effects of predictor vari- ables in black box supervised learning models. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 82(4):1059–1086, 2020.
[4] Francesco Bodria, Fosca Giannotti, Riccardo Guidotti, Francesca Naretto, Dino Pedreschi, and Salvatore Rinzivillo. Benchmarking and survey of explanation methods for black box models. arXiv preprint arXiv:2102.13076, 2021.
[5] Chun-Hao Chang, Rich Caruana, and Anna Goldenberg. Node-gam: Neural generalized additive model for interpretable deep learning. arXiv preprint arXiv:2106.01613, 2021.
[6] Leo Breiman. Random forests. Machine learning, 45(1):5–32, 2001.
[7] Karthik S Gurumoorthy, Amit Dhurandhar, Guillermo Cecchi, and Charu Aggarwal. Efficient data representation by selecting prototypes with importance weights. In 2019 IEEE International Conference on Data Mining (ICDM), pages 260–269. IEEE, 2019.
[8] Trevor J Hastie and Robert J Tibshirani. Generalized additive models. Routledge, 2017.
[9] Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions. Advances in neural information processing systems, 30, 2017.
[10] Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. ”why should i trust you?” explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pages 1135–1144, 2016.
[11] Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE international conference on computer vision, pages 618–626, 2017.
[12] Avanti Shrikumar, Peyton Greenside, and Anshul Kundaje. Learning important features through propagating activation differences. In International conference on machine learning, pages 3145–3153. PMLR, 2017.
[13] Paul Voigt and Axel Von dem Bussche. The eu general data protection regulation (gdpr). A Practical Guide, 1st Ed., Cham: Springer International Publishing, 10(3152676):10–5555, 2017.
[14] Zebin Yang, Aijun Zhang, and Agus Sudjianto. Gami-net: An explainable neural network based on generalized additive models with structured interactions. Pattern Recognition, 120:108192, 2021.