
In the near future, you’ll be able to buy a self-driving car. If you thought selecting custom car features was difficult now, imagine having to make the choice between relinquishing control to a machine or remaining in the driver’s seat? And how would you even decide which self-driving car company had the best algorithmic safety features for your family? Puts rear defoggers into serious perspective.
The answer boils down to trust.
Trust in a machine, or an algorithm, is difficult to quantify. It’s more than just performance — most people will not be convinced by being told research cars have driven X miles with Y crashes. You may care about when negative events happen. Were they all in snowy conditions? Did they occur at night? How robust is the system, overall?
In machine learning, we typically have a metric to optimize. This could mean we minimize the time to travel between points, maximize the accuracy of a classifier, or maximize the return on an investment. However, trust is much more subjective, domain dependent, and user dependent. We don’t know how to write down a formula for trust, much less how to optimize it.
This post argues that intelligibility is a key component to trust.1 The deep learning explosion has brought us many high-performing algorithms that can tackle complex tasks at superhuman levels (e.g., playing the games of Go and Dota 2, or optimizing data centers). However, a common complaint is that such methods are inscrutable “black boxes.”
If we cannot understand exactly how a trained algorithm works, it is difficult to judge its robustness. For example, one group of researchers trained a deep neural network to detect pneumonia from X-rays. The data was collected from both inpatient wards and an emergency department, which had very different rates of the disease. Upon analysis, the researchers realized that the X-ray machines added different information to the X-rays — the network was focusing on the word “portable,” which was present only in the emergency department X-rays, rather than medical characteristics of the picture itself. This example highlights how understanding a model can identify problems that would potentially be hidden if one only focuses on the accuracy of the model.
Another reason to focus on intelligibility is in cases where we have properties we want to verify but cannot easily add to the loss function, i.e., the objective we wish to optimize. One may want to respect user preferences, avoid biases, and preserve privacy. An inscrutable algorithm may be difficult to verify, whereas an intelligible algorithm’s output would not be so. For example, the black box algorithm COMPAS is being used for assessing the risk of recidivism and has been accused of being racially biased by an influential ProPublica article. In Cynthia Rudin’s article “Please Stop Explaining Black Box Models for High-Stakes Decisions“, she argues that her model (CORELS) achieves the same accuracy as COMPAS, but is fully understandable, as it consists of only 3 if/then rules, and it does not take race (or variables correlated with race) into account.
| if (age = 18 − 20) and (sex = male) then predict yes else if (age = 21 − 23) and (priors = 2 − 3) then predict yes else if (priors > 3) then predict yes else predict no |
Rule list to predict 2-year recidivism rate found by CORELS.
What does it mean to be intelligible?
As mentioned above, intelligibility is context-dependent. But in general, we want to have some construct that can be understood when considering a user’s limited memory (i.e., people have the ability to hold 7 +/- 2 concepts in mind at once). There are three different ways we can think about intelligibility, which I enumerate next.
Local vs. Global
A local explanation of a model focuses on a particular region of operation. Continuing our autonomous car example, we could consider a local explanation to be one that explains how a car made a decision in one particular instance. The reasoning for a local explanation may or may not hold in other circumstances. A global explanation, in contrast, has to consider the entire model at once and thus is likely more complicated.
Algorithmic Understanding
A more technically inclined user or model builder may have different requirements. First, they may think about the properties of the algorithm used. Is it guaranteed to converge? Will it find a near-optimal solution? Do the hyperparameters of the algorithm make sense? Second, they may think about whether all the inputs (features) to the algorithm seem to be useful and are understandable. Third, is the algorithm “simulatable” (where a person can calculate the outputs from inputs) in a reasonable amount of time?
User Explainable
If a solution is intelligibile, a user should be able to generate explanations about how the algorithm works. For instance, there should be a story about how the algorithm gets to a given output or behavior from its inputs. If the algorithm makes a mistake, we should be able to understand what went wrong. Given a particular output, how would the input have to change in order to get a different output?
How do we achieve intelligible algorithms?
There are four high-level ways of achieving intelligibility. First, the user can passively observe input/output sequences and formulate their own understanding of the algorithm. Second, a set of post-hoc explanations can be provided to the user that aim to summarize how the system works. Third, the algorithm could be designed with fewer black-box components so that explanations are easier to generate and/or are more accurate. Fourth, the model could be inherently understandable.
Direct Observation
Observing the algorithm act may seem to be too simplistic. Where this becomes interesting is when you consider what input/output sequences should be shown to a user. The HIGHLIGHTS algorithm focuses on reinforcement learning settings and works to find interesting examples. For instance, the authors argue that in order to trust an autonomous car, one wouldn’t want to see lots of examples of driving on a highway in light traffic. Instead, it would be better to see a variety of informative examples, such as driving through an intersection, driving at night, driving in heavy traffic, etc. At the core of the HIGHLIGHTS method is the idea of state importance, or the difference between the value of the best and worst actions in the world at a given moment in time:
\begin{equation}I(s) = \max_{a} Q^\pi_{(s,a)} – \min_a Q^\pi_{(s,a)}\end{equation}
In particular, HIGHLIGHTS generates a summary of trajectories that capture important states an agent encountered. To test the quality of the generated examples, a user study was performed where people watched summaries of two agents playing Ms. Pacman and were asked to identify the better agent.
This animation shows the output of the HIGHLIGHTS algorithm in the Ms. Pacman domain merged5.gif – Google Drive
Bolt-On Explanations
Once the model learns to perform a task, a second model could be trained to then explain the task. The motivation is that maybe a simpler model can represent most of the true model, while being much more understandable. Explanations could be natural language, visualizations (e.g., saliency maps or t-SNE), rules, or other human-understandable systems. The underlying assumption is that there’s a fidelity/complexity tradeoff: these explanations can help the user understand the model at some level, even if it is not completely faithful to the model.
For example, the LIME algorithm works on supervised learning methods, where it generates a more interpretable model that is locally faithful to a classifier. The optimization problem is set up so that it minimizes the difference between the interpretable model g from the actual function f in some locality πx, while also minimizing the measure of the complexity of the model g:
\begin{equation}\xi(x) = \mbox{argmin}_{g \in G} ~~\mathcal{L} (f, g, \pi_x) + \Omega(g)\end{equation}
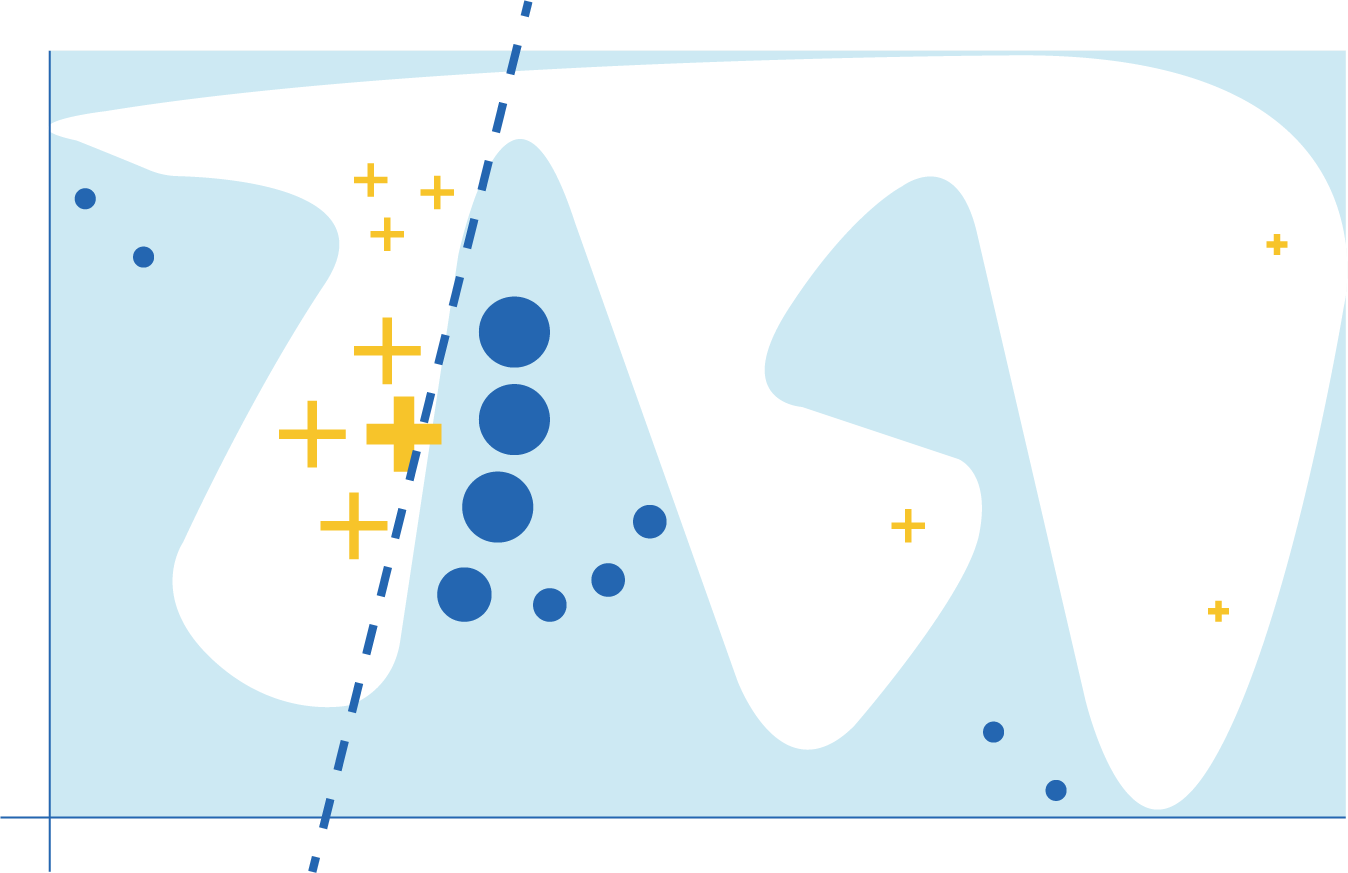
In this example from the paper, the blue/white separation defines the classification boundary of f. The dashed line shows a locally valid explanation for the classifier for the instance marked by the bold yellow cross.
The paper also introduces SP-LIME, an algorithm to select a set of representative instances by exploiting the sub-modularity principle to greedily add non-overlapping examples that cover the input space while giving examples of different, relevant, outputs.
A novel approach to automated rationale generation for reinforcement learning agents is presented by Ehsan et al. Many people are asked to play the game of Frogger. Then, while they’re playing the game, they provide explanations as to why they executed an action in a given state. This large corpus of states/actions/explanations is then fed into a model. The explanation model can then provide so-called rationales for actions from different states, even if the actual agent controlling the game’s avatar uses something like a neural network. The explanations may be plausible, but there’s no guarantee that they match the actual reasons the agent acted the way it did.
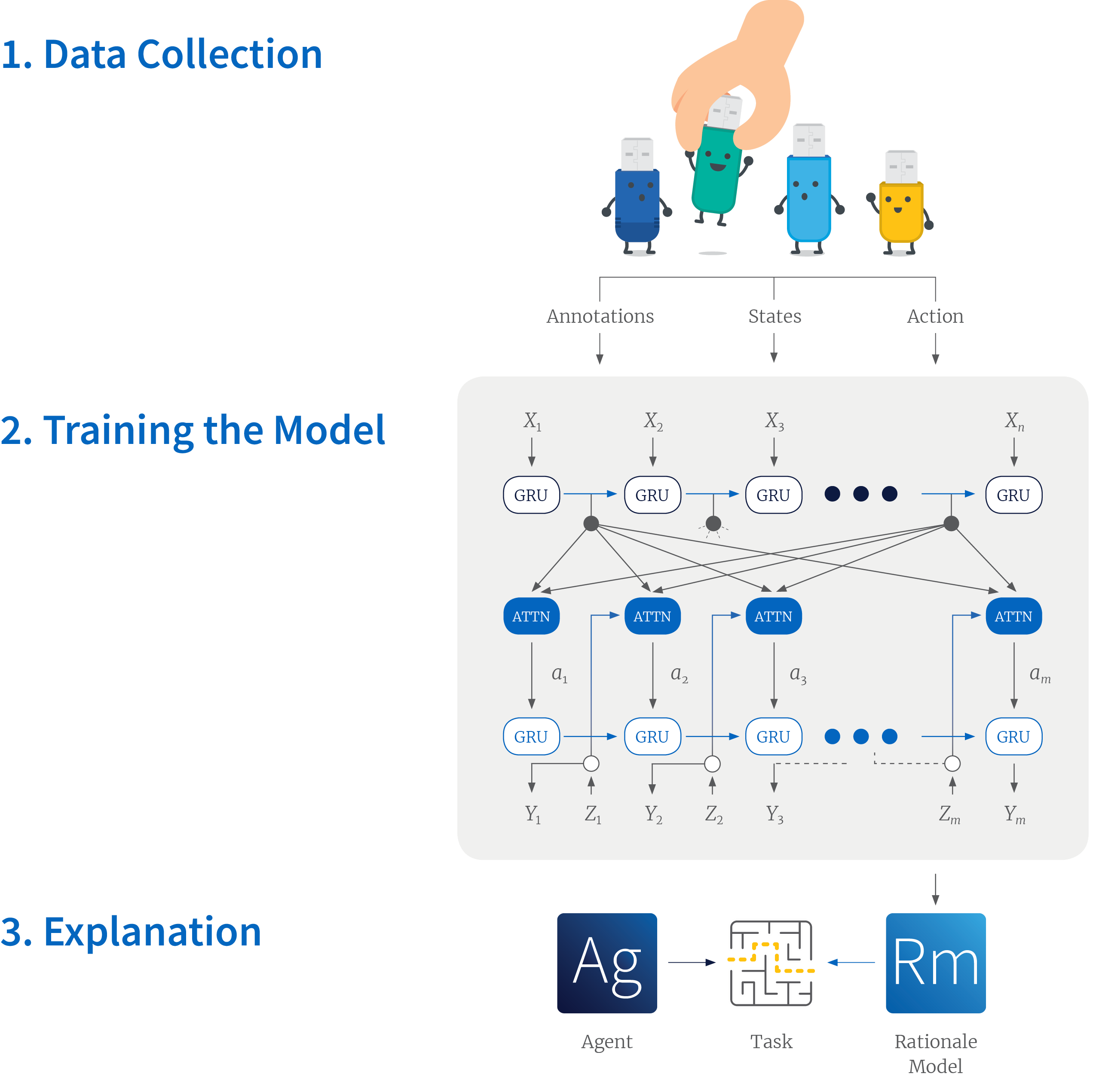
Ehsan et al. first create a natural language corpus via think-aloud protocols. Second, a rationale model is trained to produce explanations for an agent’s actions. Third, this model can be used to provide rationales for any agent, whether it is controlled by a human or an algorithm.
The Deep neural network Rule Extraction via Decision tree induction (DeepRED) algorithm is able to extract human-readable rules that approximate the behavior of multi-level neural networks that perform multi-class classification. The algorithm takes a decompositional approach: starting with the output layer, each layer is explained by the previous layer, and then the rules (produced by the C4.5 algorithm) are merged to produce a rule set for the entire network. One potential drawback of the method is that it is not clear if the resulting rule sets are indeed interpretable, or if the number of terms needed in the rule to reach appropriate fidelity would overwhelm a user.
Encouraging Interpretability:
In order to make a better explanation, or summary of a model’s predictions, the learning algorithm could be modified. That is, rather than having bolt-on explainability, the underlying training algorithm could be enhanced so that it is easier to generate the post-hoc explanation. For example, González et al. build upon the DeepRED algorithm by sparsifying the network and driving hidden units to either maximal or minimal activations. The first goal of the algorithm is to prune connections from the network, without reducing accuracy by much, with the expectation that “rules extracted from minimally connected neurons will be simpler and more accurate.” The second goal of the algorithm is to use a modified loss function that drives activations to maximal or minimal values, attempting to binarize the activation values, again without reducing accuracy by much. Experiments show that models generated in this manner are more compact, both in terms of the number of terms and the number of expressions.
Fundamentally Interpretable
A more radical solution is to focus on models that are easier to understand (e.g., “white box” models like rule lists). Here, the assumption is that there is not a strong performance/complexity tradeoff. Instead the goal is to do (nearly) as well as black box methods while maintaining interpretability. One example of this is the recent work by Okajima and Sadamasa on “Deep Neural Networks Constrained by Decision Rules,” which trains a deep neural network to select human-readable decision rules. These rule-constrained networks make decisions by selecting “a decision rule from a given decision rule set so that the observation satisfies the antecedent of the rule and the consequent gives a high probability to the correct class.” Therefore, every decision made is supported by a decision rule, by definition.
The Certifiably Optimal RulE ListS (CORELS) method, as mentioned above, is a way of producing an optimal rule list. In practice, the branch and bound method solves a difficult discrete optimization problem in reasonable amounts of time. One of the take-home arguments of the article is that simple rule lists can perform as well as complex black-box models — if this is true, shouldn’t white-box models be preferred?
What’s Next?
One current research project we’re working on at RBC Borealis focuses on making deep reinforcement learning more intelligible. However, the current methods are opaque: it is difficult to explain to clients how the agent works, and it is difficult to be able to explain individual decisions. While we are still early in our research, we are investigating methods in all categories outlined above. The long-term goal of this research is to bring explainability into customer-facing models to ultimately help customers understand, and trust, our algorithms.
1Note that we choose the word “intelligibility” with purpose. The questions discussed in this blog are related to explainability, interpretability, and “XAI,” and more broadly to safety and trust in artificial intelligence. However, we wish to emphasize that it is important for the system to be understood and that this may take some effort on the part of the subject understanding the system. Providing an explanation may or may not lead to this outcome — the example may be unhelpful, inaccurate, or even misleading with respect to the system’s true operation.