
Over the last decade, machine learning (ML) has revolutionized many industries, with ML models finding success in a variety of settings such as recommendation systems, speech and image recognition. However, research has shown that these models may be vulnerable to a plethora of failures such as fairness, bias, robustness issues and vulnerability to privacy leaks. Figure 1 outlines several of these failures and where they may affect an ML model during its pipeline. For more information on some of these failures and ways to mitigate them, you can find our posts on fairness and bias in AI, privacy and adversarial robustness. As a consequence, countries and international organizations are looking at ways to ensure ML and AI, in general, are developed in a responsible manner.

Figure 1. ML model failures, sourced from finlayson et al., 2019, with modifications.
Machine learning certification is the process by which we ensure that an ML model is robust to one or more of these failures. While ML certification is currently at its infancy with many open questions, it has many potential benefits such as mitigating the harmful effects of the aforementioned failures, establishing trust in the model, improving explainability, and helping comply with any regulatory and legal requirements. This can be of paramount importance in numerous settings, especially in ones where the ML models have life-changing impact – such as autonomous vehicles, medical and financial domains. ML Certification is a holistic process that should be ingrained into the entire pipeline of an ML project, from the requirements gathering phase to monitoring the deployed model during production. At its core, ML Certification can be regarded as filling out the statement below:
Certification Statement
“The submitted machine learning model is known to abide by the property of …(a)… up to a threshold of …(b)… over the following input range: …(c)… .”
Here, property (a) in the template above refers to the absence of a failure. For instance adversarial attack is a well-studied failure in ML models, and the corresponding property of adversarial robustness refers to robustness of these attacks. While in the ideal world, we would wish to certify the model for each property against all possible thresholds and input ranges, certifying an ML model is computationally expensive. Therefore, we identify one or more thresholds (b) and one or more input ranges (c) in the template above, making this process more tractable. As a result, we end up with several filled templates, otherwise known as specifications, each with a unique combination of property, threshold and input range to certify an ML model against. Figure 2 outlines the steps in the ML certification process. Broadly, this process consists of two steps:

Figure 2. Flowchart outlining the ML certification process.
- Determine the specification, which consists of a unique combination of property, threshold and input range for which to certify the ML model against.
- Verify whether the ML model satisfies the given specification.
In step 1 of the ML certification process, we fill in the blanks (a, b, and c) in the template above, resulting in one or more specifications (filled statements) that we wish to certify an ML model against. Subsequently, in step 2 we verify whether the ML model satisfies the specifications.
Determine specification
The first step of certification consists of determining the property, threshold and input range (collectively known as the specification) for which to certify the ML model against. It is a holistic process integrated into the project life cycle, and should begin very early in the project life cycle. Ideally, this process starts during the requirements gathering phase of the project in order to ensure clarity of the security requirements of the desired ML model like all other requirements. In addition, more specifications may need to be added or current ones may need to be revised based on any changes in project development.
Determining specification requires significant subject matter expertise on the use case, the limitations of the ML model architecture, including the parameters and hyper-parameters used, and the limitations of the deployment environment, including the type of users this ML model is exposed to. As a consequence, identifying these specifications, including the careful selection of thresholds, should be done in collaboration with all stakeholders of the project. Currently, there is limited literature on how to identify specifications, including ways on explaining the significance of the chosen threshold and input range.
A simple specification example
As an example to motivate the next part of our post, consider a simple example where a ‘model’ is represented by the equation $y = x^2$, and a specification that defines the property of adversarial robustness, which states that a small change in the input should not drastically change the output. More specifically, given a model M, input value x and threshold ϵ, this simplistic definition of adversarial robustness states that $\forall x’ s.t. |x – x’| < \epsilon, |M(x) – M(x’)| < \epsilon$. In other words, all possible inputs $x′$ within the range of x should result in the model’s output to be within ϵ range of it’s output on $x$. We use a threshold of 0.3, and an input value of 1, which results in the input range of [0.7,1.3]. Figure 3 provides a visual of the ‘model’, as well as outlines the bounding box that represents the input and output values for which we wish to certify the property of adversarial robustness.
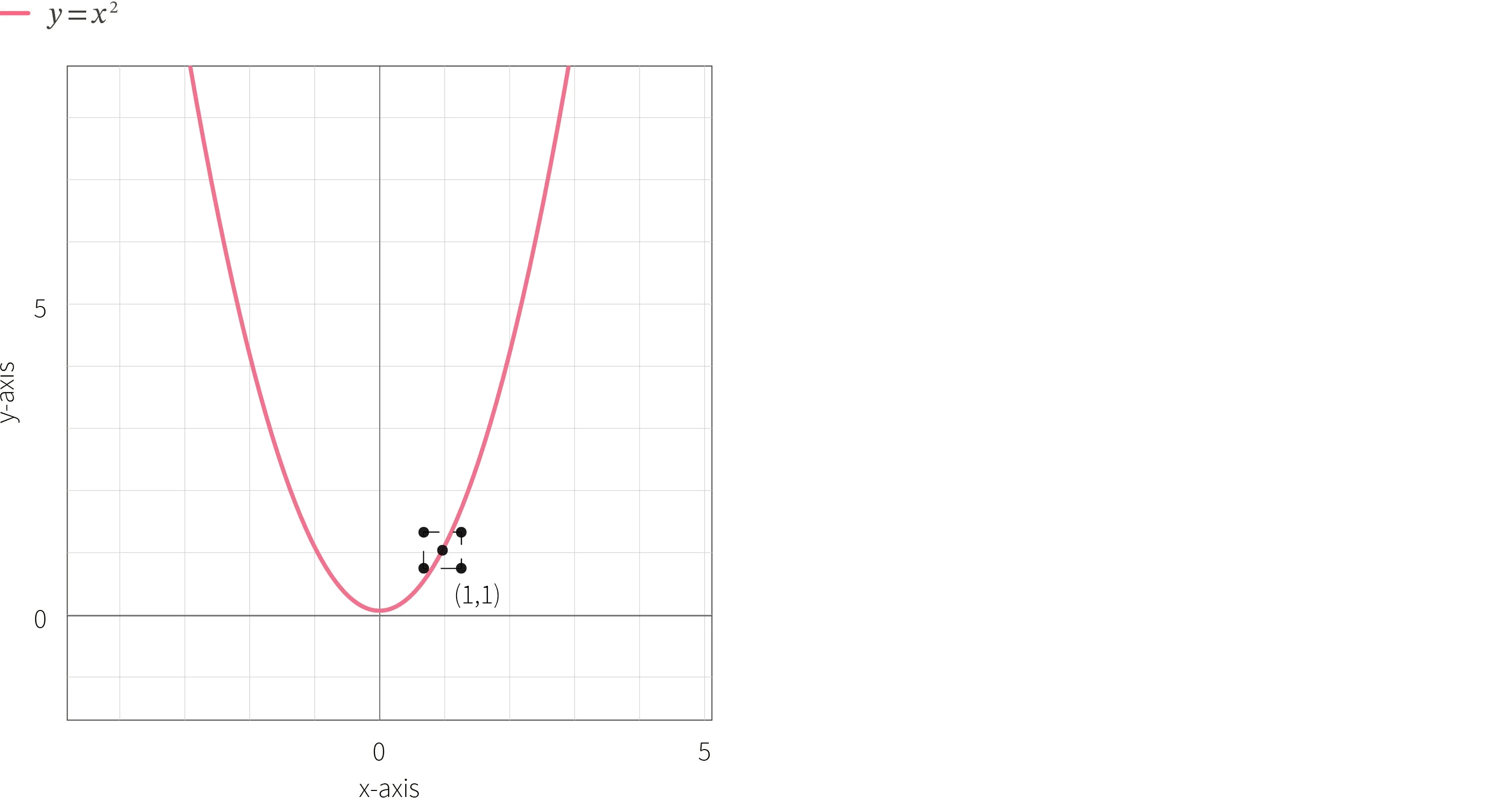
Figure 3. Target ‘model’ $y = x^2$ with bounding box that outlines the input and output range determined based on the threshold (0.3) and input value (1) provided. This bounding box is the region where we wish to certify the property (adversarial robustness).
Verify specification
The second step of certification consists of verifying whether the ML model satisfies the specifications that have been determined in the previous step. In other words, we check if the ML model is robust to the failures identified in the property for the given thresholds and input ranges in this step. This should usually be done after model training but before the final evaluation of the model on the test set to ensure that we are able to modify the model without introducing bias since typically the model should not be modified after the final evaluation. There are three main approaches identified in the literature that can verify whether a model satisfies a given specification:
- Constraint-based verification, where the model, as well as the specifications, are converted to a set of constraints and a solver is used to exhaustively search for violations of the specification.
- Abstraction-based verification, where abstraction of the input region that encapsulates the specification in propagated through the ML model and the output region is checked for violations of the specification.
- Duality-based verification, where verification is viewed as an optimization problem and a corresponding dual is computed to determine the worst case violation, which is compared against the specification.
We next provide an overview of each of these approaches.
Constraint-based verification
Main idea: Figure 4 shows the main idea of the constraint-based verification approach. In this approach, the ML model, as well as the specification, is converted to a set of constraints – often using boolean or some other formal logic such as mixed integer linear programming. The resulting set of constraints is designed such that finding a solution results in finding an input to the ML model that is within the identified input range but violates the specification (or in other words, a counter-example proving that the model does not satisfy the specification).

Figure 4. Flowchart outlining the constraint-based verification process.
These constraints are provided to a formal logic solver, which exhaustively searches over the input range provided in the specification in order to find whether violations exist. If a violation is found, then that is proof that the model does not satisfy the specification. However, if the solver is unable to find a violation, then that is proof that one does not exist since the solver exhaustively searches over the input region. While exhaustively searching over the input range requires exponential time w.r.t the size of the input region in the worst case, solvers use many optimization techniques in order to more efficiently search over the input region in practice. In order to get a better understanding of this approach, you can find our excellent tutorials that cover SAT solvers.
Verifying the example specification: In order to verify the example specification using the constraints-based approach, the model $y = x^2$, as well as the specification of adversarial robustness, are first converted to a set of constraints. Let us denote the constraints encoding the model as F and constraints encoding the specification as G. We provide as input to the formal solver the formula F ∧¬G where the variables are defined over the input range identified in the specification. The solver exhaustively searches over this range for a satisfiable assignment. If it finds one, that assignment refers to an input that is a successful adversarial attack on the model – proving that the model does not satisfy the property. In case the solver does not find a satisfying input to this formula, this is a guarantee that one does not exist.
Advantages: There are several advantages to this approach. Firstly, formal language solvers are used in many settings, and there is a lot of literature and tools available which can be leveraged to verify ML models. Secondly, this approach can provide guarantees since it exhaustively searches over the entire input space. Finally, since formal logic is a rich language, we can encode a broad range of specifications in order to verify an ML model.
Challenges: There are, however, some key limitations to this approach currently. The resulting formula of the ML model and specification can be very large and pose significant scalability and storage issues. Further, in the worst case, this approach requires exponential time with respect to the input range and can therefore take an exceptionally long time to solve (in the order of many years). Finally, while theoretically, many types of ML models can be converted to constraints, there is a considerable gap in the available tools to convert many types of ML models (e.g. no tools exist to convert various neural network architectures such as sigmoid activation functions).
Further reading: An introduction to constraints-based verification of machine learning (specifically neural networks) can be found on Neural network verification book.
Abstraction-based Verification

Figure 5. Flowchart outlining the abstraction-based verification process.
Main idea: Figure 5 shows the main idea of the abstraction-based verification approach. First, an abstraction of the input region identified in the specification is defined using a geometric object. Then, functions (known as abstract transformers) are used to propagate this geometric region through the ML model, which results in a corresponding output region. This (potentially infinite) output region is searched to find any violations of the specification. Because this approach uses an abstraction of the input region and the model, it usually over-approximates the search area. What this means is that if a violation is found in the output region, it does not guarantee that this violation is caused by a value in the true input region (identified by the specification), since it may have been from an input in the over-approximated region. In such a case, a refinement of the abstraction is necessary, which results in an increase in computational overhead. However, if no violation is found in the output region, then we can guarantee that the ML model satisfies the specification. There are several types of geometric regions that are used in this approach, which balance degree of over-approximation with computational resources required.
Verifying the example specification: To verify the example specification using an abstraction-based approach, we construct an approximation of the identified input region using a geometric object. This region is propagated through the model in order to obtain the corresponding abstract output region, which is then checked for violation of the specification. Figure 5 shows the result of three types of geometric regions that can be used to create this abstraction: interval, zonotope, and polyhedron domains. These regions are ordered in terms of increasing computational resources needed, which allow for an increase in the precision of the abstraction region, as can be seen in the figure. Given the definition of adversarial robustness used in the specification, we can check for violations in the output region by identifying whether there are any values in the output region that differ from the expected output region by ϵ. In other words, we check if the corresponding output region obtained via these geometric regions is a strict super-set of the expected output region (which is a square).
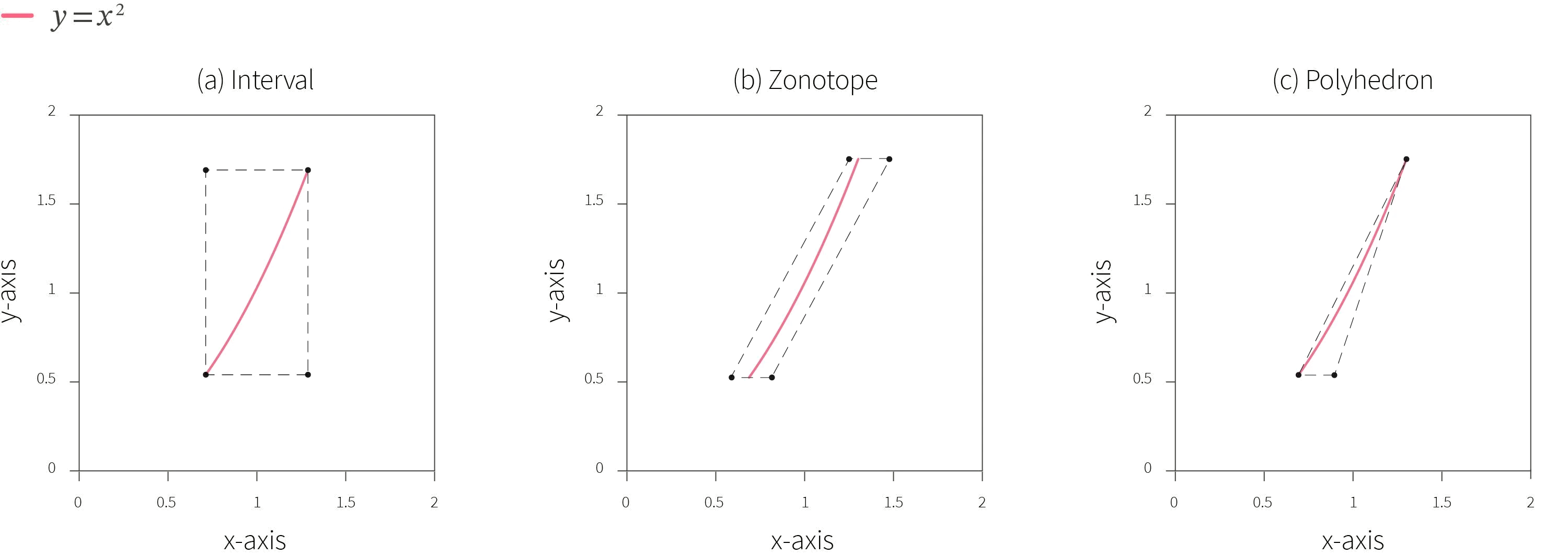
Figure 6. Result of abstraction-based verification on the example specification using interval (left), zonotope (center) and polyhedron (right) domains.
Advantages: Since the propagation is done in one forward pass of the model, abstraction-based verification is much faster than the constrained-based approach. In addition, this approach allows to effectively balance the trade-off between computation and precision by first using simpler geometric objects in order to check whether violations exist and refining that region using more complex objects as needed.
Challenges: This approach does pose certain challenges. Due to the possible over-approximation, the identified output region can extensively deviate from the true output region, resulting in situations where this approach may not find a solution. Further, the types of specifications it allows is restricted to ones where the input regions are contiguous, and so not all specifications may be verified using this approach.
Further reading: An introduction to abstraction-based verification of machine learning models (particularly neural networks) can be found on Neural network verification book.
Duality-based Verification
Main idea: Figure 7 provides an outline of duality-based verification. In this approach, verification is viewed as an optimization problem and a dual function is first constructed. The dual – or more specifically – the Lagrangian dual function relates to the original ‘primal’ function in such a way that the decision variables in the primal problem correspond to the constraints in the dual problem, and every constraint in the primal problem corresponds to a decision variable in the dual problem. An (upper-bound) optimal solution to the dual serves as a lower bound for the primal function. Because this dual function is constructed to be simpler to solve, we find its optimal solution and compare that with the threshold provided in the specification.

Figure 7. Flowchart outlining the duality-based verification process.
Verifying the example specification: In order to verify the example specification using duality-based approach,
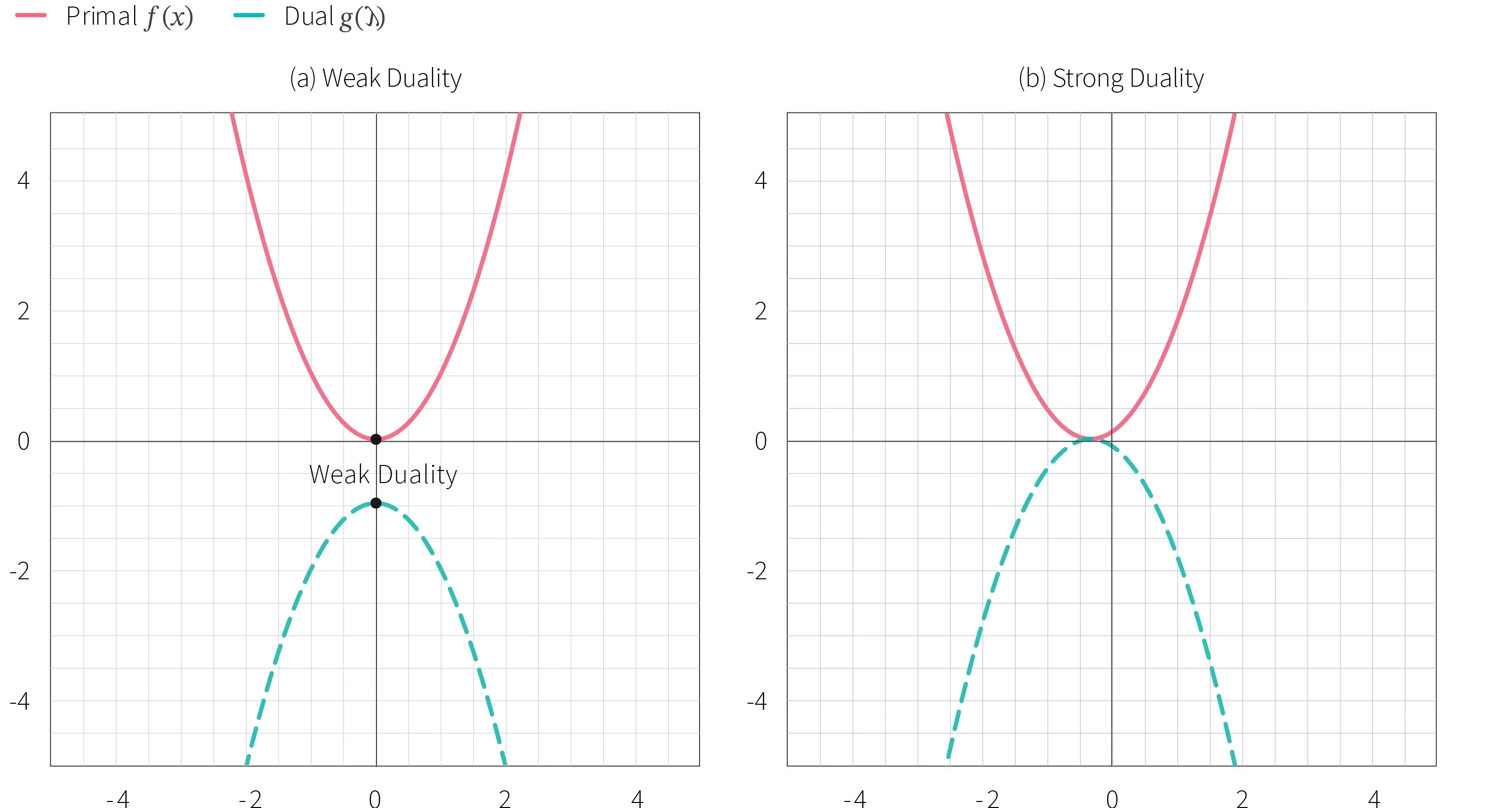
Figure 8. Visualizing the primal and corresponding dual functions. Note that the axis in the primal (x) and dual ($\lambda$) are different, but the graphs of the two functions are given together for sake of clarity. Left: weak duality where there is a gap between the optimal solution of the primal and dual functions. Right: strong duality where the optimal solutions of primal and dual functions are equal, providing tighter bounds.
we first construct the corresponding dual to the primal problem of verifying the specification. Consider Figure 8, which showcases two possible duality functions. Note that the axis for the primal and dual function differ (x versus λ); however, we provide both functions on the same dimensions for better clarity. While the model in the specification is the equation y = x2, the primal and dual functions may not necessarily be the same equation. Nevertheless, for the sake of simplicity, we assume that both the primal and dual problems here are quadratic equations. The optimal solution to the dual function computed on the left figure is lower than the optimal solution to the primal problem. This type of dual function is known as weak duality, and the gap between the optimal functions is known as the dual gap. On the other hand, the optimal solution for the primal and dual functions are equal in the figure to the right, and this is known as strong duality. Ideally, we wish to construct a strong duality in order to get a tighter bound, but depending on the use case, we may wish to allow for a duality gap for the sake of finding a simpler dual function.
Once we compute the optimal solution for the dual function, we compare that against the specification. If the optimal solution is below the threshold, that means the model satisfies the given specification since the specification is better than even the worst-case bounds. On the other hand, if the worst case is greater than the specification, then we are not sure if the model violates the specification since there may be a significant duality gap.
Advantages: There are several advantages to the Duality-based verification approach. Firstly, this approach is computationally efficient, especially in the case of strong convexity in the dual function where gradient-based optimization techniques can be used. In addition, this approach allows to trade computation with precision by controlling the complexity of the dual function as well as the duality gap. Finally, since this approach uses optimization to find a solution, we can leverage algorithms that can speed up optimization, such as branch-and-bound techniques.
Challenges: As with other approaches, duality-based verification is not without its challenges. Similar to the abstraction-based verification, this approach can over approximate the solution due to the duality gap, and as a result, it can falsely state that there is a violation of the specification when that is not the case. In addition, depending on the choice of the solver, this approach may not provide complete guarantees. Finally, we may not be able to construct dual functions for all types of constraints and may only be able to apply it to a limited number of specifications.
Further reading: An introduction to duality-based verification of machine learning (emphasizing neural networks) can be found A Dual Approach to Scalable Verification of Deep Networks.
Conclusion
This concludes our post on machine learning certification, a process that ensures that an ML model is robust to one or more failures. This process consists of first determining the specification consisting of the property, threshold and input range for which to certify the model against and then verifying the specification to check whether the model satisfies the identified specifications using one of the identified verification approaches.
ML certification is an active area of research with a rich array of new works that aim to improve the number of properties, as well as the size and types of models that can be certified. A notable initiative here is the verification of neural networks competition (VNNCOMP) that aims to bring together the ML verification community, where researchers can submit tools to compete against others on verifying against a benchmark of ML models and specifications. In addition, a recent line of research (such as Adel et al., 2019) aims to either correct or replace the ML model with another of similar performance but known to abide by the desired specifications.
However, there are several open problems that need to be addressed in ML certification. Firstly, there are limited systematic ways of determining the specification to certify the ML model against. Conversely, there is a gap between mathematical definitions of specifications that are required to certify a model and explaining their real-world significance. For instance, effectively explaining to stakeholders the significance of the threshold and definition used for a given property to certify an ML model is an area that needs significant improvement. Further, due to the dangers of domain shift and drift, where the distribution of input data or relationship between data and labels alter over time – the ML model may need to be recertified for some or all specifications periodically, and we currently do not know how to determine the frequency of re-certification, as well as what that process should entail. Finally, if the verification process fails (i.e. the model is found not to abide by the specification), it is not clear what is the best remediation process. Perhaps the model architecture does not allow it to satisfy both the business and security objectives, in which case a new architecture should be selected instead of modifying the current model. Or perhaps the specification is too stringent and may need to be adjusted. Identifying the root cause in case of a failure is non-trivial and requires more investigation.
With governments and regulatory boards providing new guidelines on developing ML models, the landscape of ML certification is constantly shifting. ML certification is important because it helps improve the explainability of the model’s properties, establishes trust in the model, and helps comply with any internal or external regulations. More importantly, as firm believers in responsible AI, ML certification is the right thing to do.
In this blog post, we outline various approaches that provide some form of guarantee that a model satisfies the identified specifications. There are other approaches that do not offer any sort of guarantees – known as testing approaches. These approaches search for counter-examples, which are violations that show that the model does not satisfy a specification. The search can range from simple (random-based fuzzing) to complicated (natural evolutionary strategies). A survey of machine learning testing approaches can be found Machine Learning Testing: Survey, Landscapes and Horizons | IEEE Xplore.
Blog