
In the fast-paced field of machine learning, a recent research paper poses an intriguing question: “Were RNNs All We Needed?” The title of this paper has generated discussion within the AI community, suggesting that some recent advancements in artificial intelligence might be traceable back to decades-old methods. The authors explored combining decades-old Recurrent Neural Networks (RNNs) with traditional parallel processing methods, revealing insights that contribute to our understanding of the computational efficiency and capabilities of modern models. In this interview, we discuss their motivation, research process, and the interesting findings they discovered.
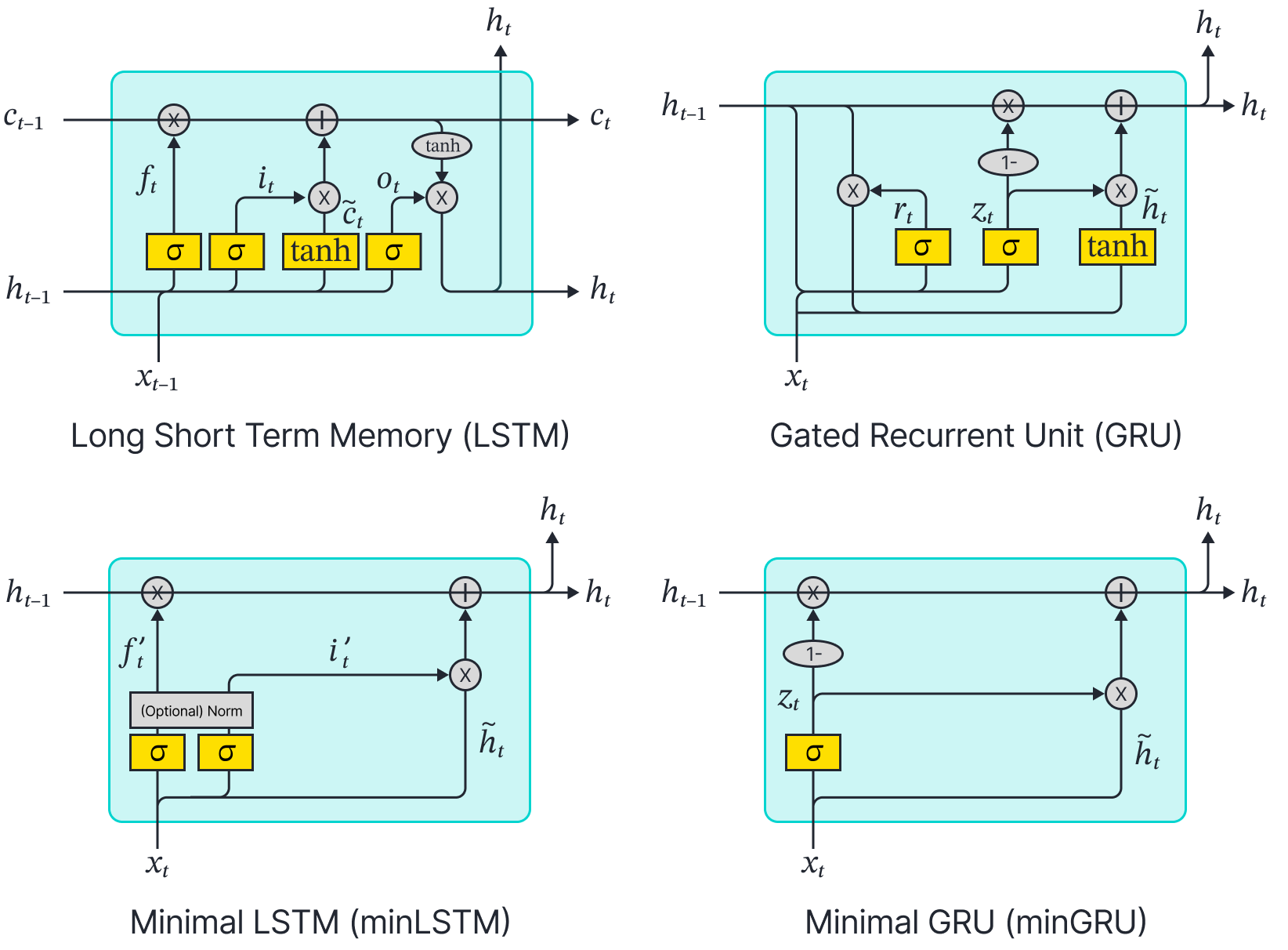
Simplification of Traditional RNNs to Minimal RNNs (minRNNs) The top row illustrates popular decades-old RNN models that were strictly sequential during training. This reliance made them less efficient and contributed to their eventual deprecation in favor of more advanced parallelizable architectures such as Transformers. The bottom row introduces the proposed minimal versions of these RNNs—minRNNs—which require fewer parameters and can be trained in parallel using traditional parallel processing techniques. Despite their simplicity, minRNNs achieve strong performance comparable to that of modern models.
Where did this idea originate from?
This project began while exploring more efficient attention mechanisms. In one of our previous works, we showed that softmax attention could be viewed as a recurrent neural network (RNN) (Feng et al., 2024) and showed that it can be computed efficiently through parallel scans (Blelloch, 1990). While doing so, we came across recent influential papers such as RWKV (Peng et al., 2023) and Mamba (Gu & Dao, 2023), which also leveraged the parallel scan algorithm. This led us to hypothesize that the parallel scan algorithm might be a key factor behind the recent success of these methods.
What were you setting out to learn?
Given that recent success of state-of-the-art models that leverage parallel scan for efficient training, we were interested in two main questions:
- Could traditional RNNs from over two decades ago – specifically LSTMs (Hochreiter & Schmidhuber, 1997) and GRUs (Cho et al., 2014), which dominated before the rise of Transformers (Vaswani et al., 2017) – also leverage from parallel scan techniques to accelerate their training?
- If so, how would these traditional RNNs, adapted with parallel scan, compare to popular modern recurrent models, such as Mamba?
What are the limitations of minimal RNNs?
To enable parallelism, previous state dependencies were dropped from LSTMs and GRUs, resulting in modules similar to Mamba’s state-space model (S6). However, recent research has highlighted theoretical limitations arising from the absence of previous state dependencies.
Merrill et al. (2024) demonstrated that popular state-space models, such as S6, share similarities with Transformers in that they are constrained by the complexity class TC0. These models cannot solve state-tracking problems when the model depth is finite. In contrast, traditional RNNs, with their previous state dependencies, are capable of solving state-tracking problems even with a finite model depth.
As a result, the minimal versions of RNNs (minLSTM and minGRU) trade-off expressiveness with efficiency, compared to their traditional counterparts (LSTM and GRU). Furthermore, LSTMs and GRUs also have their own theoretical limitations. Notably, Delétang et al. (2023) demonstrated that RNNs and Transformers fail to generalize on non-regular tasks when evaluated across a series of tasks grouped according to the Chomsky hierarchy.
Despite these theoretical concerns, substantial empirical evidence, such as the success of Transformers and Mamba, suggests that these parallelizable models are still highly effective in practice.
What practical use does this project have?
The minimal versions of GRUs (minGRU) and LSTMs (minLSTM) are simple to implement. In the Appendix of our work, we included implementations in plain PyTorch, requiring only a few lines of code.
These simple and lightweight models are easy to adapt to a variety of applications, making them ideal for beginners, practitioners, and researchers alike. Furthermore, since they require fewer resources than more complex, modern methods, they can be deployed in resource-constrained environments while still delivering surprisingly strong performance.
What is your favorite aspect of the work?
What we found most exciting of our work was the surprising effectiveness of such simple models that are both (1) easy to implement and (2) has its foundations lie in well-established, decades-old models and algorithm. Notably, the parallel scan algorithm used for training efficiency is even older than the traditional RNNs: LSTMs and GRUs.
In 2018, Martin and Cundy (2018) proposed GILR, the first RNN module that leverages the parallel scan algorithm. However, it is only more recently that the field has experienced a widespread resurgence, with several notable models demonstrating strong empirical performance comparable to that of Transformers while being significantly more efficient. These include Mamba (Gu & Dao, 2023), RWKV (Peng et al., 2023), HGRN (Qin et al., 2023), LRU (Oriveto et al., 2023), xLSTM (Beck et al., 2024), and MatMul-free (Zhu et al., 2024)
Reflecting on the influential “Attention Is All You Need” Transformers paper from 2017, which revolutionized the field of deep learning, the recent success of modern RNNs raises an intriguing question: What if these parallelizable RNNs had become the dominant approach earlier? How might the course of deep learning research have been different?
Want to learn more about our ML Research Internship?
At RBC Borealis, we are committed to helping advance the next generation of AI experts. Apply your curiosity and expertise to a wide variety of theoretical and applied machine learning projects, with the support from our team and RBC.
Explore the program