
What’s on your NeurIPS 2021 reading list? This year, we decided to share some of our favourite papers, organized by topic: time-series, asynchronous event sequence, OOD/distribution shift/domain adaptation, flows, causality, and transformers. Our researchers selected papers from each category and provided a summary and their thoughts on the impact of the work. Enjoy this #NeurIPS2021 reading list!
Topics

Time-Series Models
Adjusting for Autocorrelated Errors in Neural Networks for Time Series
Fan-King Sun, Christopher I. Lang, Duane S. Boning
by Jiawei He
Why do we recommend?
Time series research remains a cutting edge field in machine learning community. This is especially important in Finance applications as we face stock price data, credit card transaction data, etc. A common assumption in training neural networks via maximum likelihood estimation is that the errors across time steps are uncorrelated. This assumption is still heavily applied to almost all machine learning optimizations. However, in time series problems, intrinsically, errors can be autocorrelated in many cases due to the temporal nature of the data, which makes such maximum likelihood estimation inaccurate. Although adjusting for autocorrelated errors in linear or nonlinear time series data has been studied extensively, especially in econometrics, those methods are applicable only when the exact (and correct) form of the underlying system is known. On the other hand, NNs for time-series-related tasks have become a popular research direction due to NNs’ effectiveness in approximating unknown, nonlinear systems.
To adjust for autocorrelated errors, a method to jointly learn the autocorrelation coefficient with the model parameters via gradient descent is proposed in this paper. Extensive simulation verified the effectiveness of the proposed approach on time series forecasting. Results across a wide range of real-world datasets with various state-of-the-art models show that the proposed method enhances performance in almost all cases. Based on these results, the authors suggested empirical critical values to determine the severity of autocorrelated errors. Some of the limitations mentioned in the paper includes (1) the method is not applicable to probabilistic forecasting, and (2), if the underlying time-series can be modelled well by a known process, then the benefit of adopting this approach will be decreasing. For future research directions, the authors suggested exploring more complex, higher-order autocorrelated errors with quantile regression and probabilistic forecasting.
Deep Explicit Duration Switching Models for Time Series
Adbul Fatir Ansari, Konstantinos Benidis, Richard Kurle, Ali Caner Türkmen, Harold Soh, Alexander J. Smola, Yuyang Wang, Tim Januschowski
by Jiawei He
Why do we recommend?
Many complex time series can be effectively subdivided into distinct regimes that exhibit persistent dynamics. Discovering the switching behaviour and the statistical patterns in these regimes is important for understanding the underlying dynamical system. State Space Models (SSMs) are a powerful tool for such tasks—especially when combined with neural networks — since they provide a principled framework for time series modelling One of the most popular SSMs is the Linear Dynamical System, which models the dynamics of the data using a continuous latent variable, called state, that evolves with Markovian linear transitions. The assumptions of LDS allow for exact inference of the states; however, they are too restrictive for real-world systems that often exhibit piecewise linear or non-linear hidden dynamics with a finite number of operating modes or regimes.
In this paper, the Recurrent Explicit Duration Switching Dynamical System (RED-SDS) is proposed. RED-SDS is a non-linear state space model that is capable of identifying both state- and time-dependent switching dynamics. State-dependent switching is enabled by a recurrent state-to-switch connection and an explicit duration count variable is used to improve the time-dependent switching behaviour. The authors also proposed an efficient hybrid inference and learning algorithm that combines approximate inference for states with conditionally exact inference for switches and counts. The model is trained by maximizing a Monte Carlo lower bound of the marginal log-likelihood that can be computed efficiently as a byproduct of the inference routine. Thorough evaluation on a number of benchmark datasets for time series segmentation and forecasting demonstrated that RED-SDS can learn meaningful duration models, identify both state- and time-dependent switching patterns and extrapolate the learned patterns consistently into the future. Future research directions include semi-supervised time series segmentation. For timesteps where the correct regime label is known, it is straightforward to condition on this additional information rather than performing inference; this may improve segmentation accuracy while providing an inductive bias that corresponds to an interpretable segmentation.

Asynchronous event sequence
Self-Adaptable Point Processes with Nonparametric Time Decay
Zhimeng Pan, Zheng Wang, Jeff Phillips, Shandian Zhe
by Nazanin Mehrasa
Why do we recommend?
Event sequences as a special form of time-series data, are discrete events in continuous time, meaning that events happen asynchronously in time. This type of data is prevalent in a wide variety of applications, such as social-networks, stock market, health-care, seismology and etc. To analyze event sequences and perform tasks such as future prediction, it is crucial to understand the complex influences of events on each other, including excitation, inhibition, and how the strength of these influences varies with time.
In this work, the authors propose a temporal point process framework for modeling event sequences. A temporal point process (TPP) is a mathematical framework for characterizing and modeling event sequences. A TPP is usually defined by specifying an intensity function which encodes the expected rate of events. To define the intensity, most previous neural-based point processes use recurrent neural networks and often couple all the temporal dependency in a black-box, which lacks interpretability on how events influence each other. In addition, existing work often assume simple functional forms for modeling the influence strength which limits the model’s expressiveness e.g. exponential time decay of the influence strength. In this paper, the authors propose SPRITE, short for Self-adaptable Point pRocess wIth nonparametric Time dEcays which defines the intensity by decoupling the influences between every pair of the events in the history and model the influence via a non-parametric function of events types and timing. They introduce a general construction that covers all possible time decaying functions of the influence strength, resulting into a more flexible and expressive model while providing more interpretability. The proposed model outperforms baseline models on synthetic and real-word datasets, demonstrating the effusiveness of the proposed approach.
Odd/distribution shift/domain adaptation
Detecting Anomalous Event Sequences with Temporal Point Processes
Oleksandr Shchur, Ali Caner Turkmen, Tim Januschowski, Jan Gasthaus, Stephan Günnemann
by Siqi Liu
Why do we recommend?
Out-of-Distribution (OOD) detection aims to detect examples in the test data that are not from the same distribution as the training data. Detecting these anomalous instances can not only have great value on its own for applications like alerting systems, where the purpose is to discover these instances, but also help to avoid or reduce risks of applying machine learning models, especially in risk-averse situations, such as healthcare and finance. In this work, the authors study the problem of OOD detection for data generated by temporal point processes (TPPs), i.e., event sequences. They connect OOD with goodness-of-fit (GOF) tests in TPPs and propose a new statistic, Sum-of-Squared-Spacings (3S), for GOF tests addressing some limitations of existing widely-used methods, such as being insensitive to the total number of events. In the experiments, their method shows strong and stable performance across different types of generative processes and real-world datasets.
Adaptive Risk Minimization: Learning to Adapt to Domain Shift
Marvin Mengxin Zhang, Henrik Marklund, Nikita Dhawan, Abhishek Gupta, Sergey Levine, Chelsea Finn
by Siqi Liu and Yik Chau Liu
Why do we recommend?
mpirical Risk Minimization (ERM) is commonly used to train models in machine learning, but in practice, distribution shifts (or domain shifts) can cause problems for these models and result in suboptimal performance. Previously researchers have studied similar problems in several related areas such as domain adaptation, domain generalization, and meta-learning. In this work, the authors combine ideas from meta-learning and domain adaptation and propose a generic framework termed Adaptive Risk Minimization (ARM). In this framework, the model tries to meta-learn on the training data such that it can adapt to distribution shifts at test time with only unlabeled data. The model consists of an adaptation model and a prediction model and is optimized for post-adaptation performance. They develop several methods within this framework, using either the contextual approach or the gradient-based approach, which show better performance in the experiments than previous methods that focus on either test domain adaptation or training domain generalization alone, demonstrating the benefits of combining adaptation with meta-learning.

Flows
Continuous Latent Process Flows
Ruizhi Deng, Marcus A Brubaker, Greg Mori, Andreas Lehrmann
by Ruizhi Deng
Why do we recommend?
How should we fit partial observations of continuous time-series dynamics on discrete time grids? Using a probabilistic model with continuous dynamics would be an intuitively promising idea. Defining continuous dynamics could permit us to sample trajectories in a continuous time range and perform inference on arbitrary time points. Deep learning models equipped with continuous dynamics are not actively studied until recently. Continuous Latent Process Flows (CLPF) can be viewed as an extension of two recent models: latent SDE and Continuous Time Flow Process (CTFP). CLPF combines the expressive power of latent SDE with the time-dependent decoding to CTFP as a better inductive bias to generate trajectories continuous in time. In addition, CLPF also proposes a flexible approach to the posterior process for variational approximation in a principled piece-wise manner. CLPF demonstrates competitive performance on both synthetic and real-world data.
Universal Approximation Using Well-Conditioned Normalizing Flows
Holden Lee, Chirag Pabbaraju, Anish Sevekari, Andrej Risteski
by Ruizhi Deng
Why do we recommend?
Normalizing flows are generative models that transform a simple base distribution to a complex target distribution using invertible mapping. Affine coupling layer is a popular choice of basic building blocks in normalizing flows as the determinant of the transformation’s triangular Jacobian can be computed in linear time. Normalizing flows using affine coupling layers also demonstrate promising success when scaled up to high-dimensional data like images. However, understanding of affine coupling flows’ theoretical properties, especially its representation power, remains ambiguous until recently. Previous works studying the universal approximation property of affine coupling flows rely on constructions leading to ill-behaved Jacobian that are nearly singular and causing difficulties in practice. With mild assumptions, the recommended work employs a different construction to show the standard Gaussian can be transformed by affine coupling flows to approximate a target distribution arbitrarily well in Wasserstein distance sense. The construction pads the target distribution with standard Gaussian noise and the determinant of the transformation’s Jacobian is bounded above and below by constants. The proposed construction is supported by practice in previous works which improves the training of normalizing flows and has broader implications on the universal approximation power and training of other types of normalizing flows.
Maximum Likelihood Training of Score-Based Diffusion Models
Yang Song, Conor Durkan, Iain Murray, Stefano Ermon
by Alex Radovic
Why do we recommend?
This NeurIPS a number of papers have drawn exciting connections between diffusion, normalizing flow, and variational auto-encoder based generative models. These connections, motivated by theory, are allowing for improved optimization of diffusion models, an extremely exciting and performant family of generative models. This paper specifically uses these connections to help motivate a new optimization strategy to improve likelihood estimation with score base diffusion models. Diffusion models learn a process to transform data samples to pure noise, and a reversion of that same process which allows them to act as powerful generative models, creating convincing data samples from noise . Score-based diffusion models are trained to minimize a weighted combination of score matching losses, and are defined by a SDE. These score-based models can be interpreted as continuous normalizing flows, allowing for exact likelihood calculations, while still being trained with a score matching loss. Training with score matching is much more efficient than training a continuous normalizing flow, which requires expensive calls to an ODE solver at every step of training. However this objective provides no guarantee that likelihood scores are improved. This paper provides a new weighted score loss which is shown to upper bound the negative log-likelihood, analogous to the lower bound used when training variational auto-encoders. This novel, theory motivated loss, is then shown to empirically improve likelihood estimation across a variety of score based diffusion models and datasets. Broadly, this work and others at NeurIPS suggest score based diffusion models, with appropriate optimization choices, can provide performance in likelihood estimation competitive with continuous normalizing flows but with far more efficient training.
Neural Flows: Efficient Alternative to Neural ODEs
Marin Biloš, Johanna Sommer, Syama Sundar Rangapuram, Tim Januschowski, Stephan Günnemann
by Andreas Lehrmann
Why do we recommend?
Neural ordinary differential equations (Neural ODEs) are a popular class of statistical models that are based on a continuous-depth parametrization of a hidden state’s derivative. Extensions of this idea form the basis for a variety of latent variable models for asynchronous time-series data, including models based on latent ODEs, continuously-indexed normalizing flows, and neural stochastic differential equations. The optimization of Neural ODEs (i.e., computing gradients of network parameters w.r.t. a loss) is based on the adjoint sensitivity method, which includes expensive calls to a black-box ODE solver. Neural flows circumvent this problem by directly modeling the solution curves (the flow) instead of the original ODE and, as a result, do not have to rely on ODE solvers. One technical challenge is that the architecture representing the flow must be a valid solution to an ODE (e.g., the solution curves corresponding to different initial values cannot intersect). The paper formalizes these constraints and demonstrates how popular neural network layers, such as residual layers, GRU cells, or coupling layers, can be adapted accordingly. Applications of this approach include flow versions of encoder-decoder architectures like ODE-RNNs for filtering/smoothing as well as flow versions of normalizing flows for time-dependent density estimation (1). Comprehensive experiments show that neural flows do not only outperform their ODE-counterparts in terms of raw performance but, depending on the task and architecture, can also be up to an order of magnitude faster.
1 Note that the use of flow in this sentence is overloaded, with “normalizing flows” and “neural flows” referring to two completely different concepts.

Causality
Counterfactual Explanations in Sequential Decision Making Under Uncertainty
Stratis Tsirtsis, Abir De, Manuel Gomez Rodriguez
by Matthew Schlegel
Why do we recommend?
As more machine learning models are applied to high-stakes applications, explaining a model’s predictions is a necessary part of responsible use of these models. Reasoning about how changes in the input change a model’s prediction is known as a counterfactual explanation. This paper extends the framework of counterfactual explanations to sequences of decisions to find optimal counterfactual policies that maximize an outcome constrained to remaining close to the observed action sequence. The policies returned from their polynomial-time algorithm improve outcomes on a series of synthetic and real datasets. The authors posit that the counterfactual policies can be used to further elucidate complex decision-making processes and, specifically, give insight when counterfactual actions are concentrated on a few critical decision points. Looking beyond one-step decisions to multi-step action sequences is critical for explaining complex decision-making algorithms. This paper excellently provides the groundwork for building counterfactual explanations along trajectories.
The Causal-Neural Connection: Expressiveness, Learnability, and Inference
Kevin Muyuan Xia, Kai-Zhan Lee, Yoshua Bengio, Elias Bareinboim
by Yanshuai Cao
Why do we recommend?
Many have hypothesized that deep learning and causal inference could complement each other well. On the one hand, understanding cause and effect could help fix some known issues with deep learning, such as the poor ability to generalize out of distribution and lack of robustness to adversarial attacks. On the other hand, the power of representation learning could scale causal inference to high-dimensional problems. However, most existing works that employ causal inference with deep neural networks use them as separate stages. For example, following Pearl’s DO-Calculus, a symbolic computation step is first executed for causal identification, turning a causal question into a statistical estimation problem, which can then be solved by fitting deep neural nets.
In this work, the authors combine causal inference and neural networks on a more fundamental level with the proposed neural causal models (NCMs) and perform the causal identification via gradient descent in the same process as neural net parameter learning. No more symbolic computation is needed, just the structural knowledge expressed through the design of the neural net, which deep learning researchers already spend lots of time engineering. The paper also has theoretical results about expressivity and identifiability of NCMs, which follow from the universal approximation theorem of feedforward neural nets and the “Causal No Free Lunch” principle entailed by Pearl’s Causal Hierarchy.

Transformers
Sparse is Enough in Scaling Transformers
Sebastian Jaszczur, Aakanksha Chowdhery, Afroz Mohiuddin, Łukasz Kaiser, Wojciech Gajewski, Henryk Michalewski, Jonni Kanerva
by Peng Xu
Why do we recommend?
What problem does it solve? – Leverage sparsity to make large Tranformer models scale efficiently. To be specific, the goal is to perform inference faster than the standard Transformer as the model size scales up, while retaining the empirical performances on real tasks.
Why is this important? – The Transformer architecture have achieved huge successes in the field of natural language processing in recent years. Lately, it also gains great popularity among other fields. At the same time, the model size of Transformer models grows larger and larger, as well as the huge costs such models incur. As a result, it is increasingly important to make them scale efficiently.
The apporach taken – This paper address this problem by proposing Scaling Transformers with a separate sparse mechanism for the query, key, value and output layers (Sparse QKV for short) and combine it with sparse feedforward blocks (Sparse FF for short) to get a fully sparse Transformer architecture.
Results:
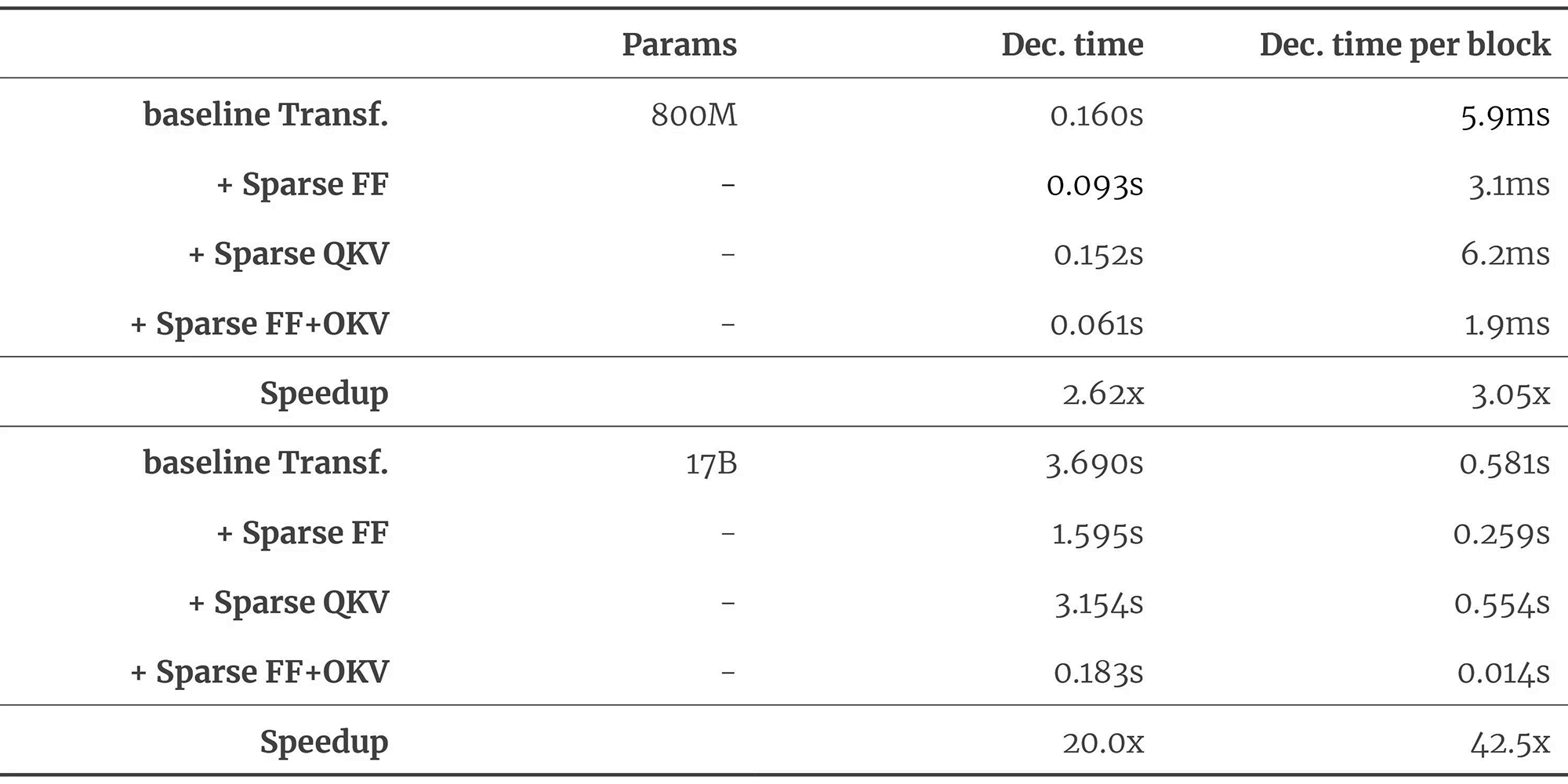
Table 1. Decoding speed (in seconds) of a single token. For Transformer model (equivalent to T5 large with approximately 800M parameters), Scaling Transformers with proposed sparsity mechanisms (FF+QKV) achieve up to 2x speed up in decoding compared to baseline dense model and 20x speedup for 17B param model (2). Image derived from original source.
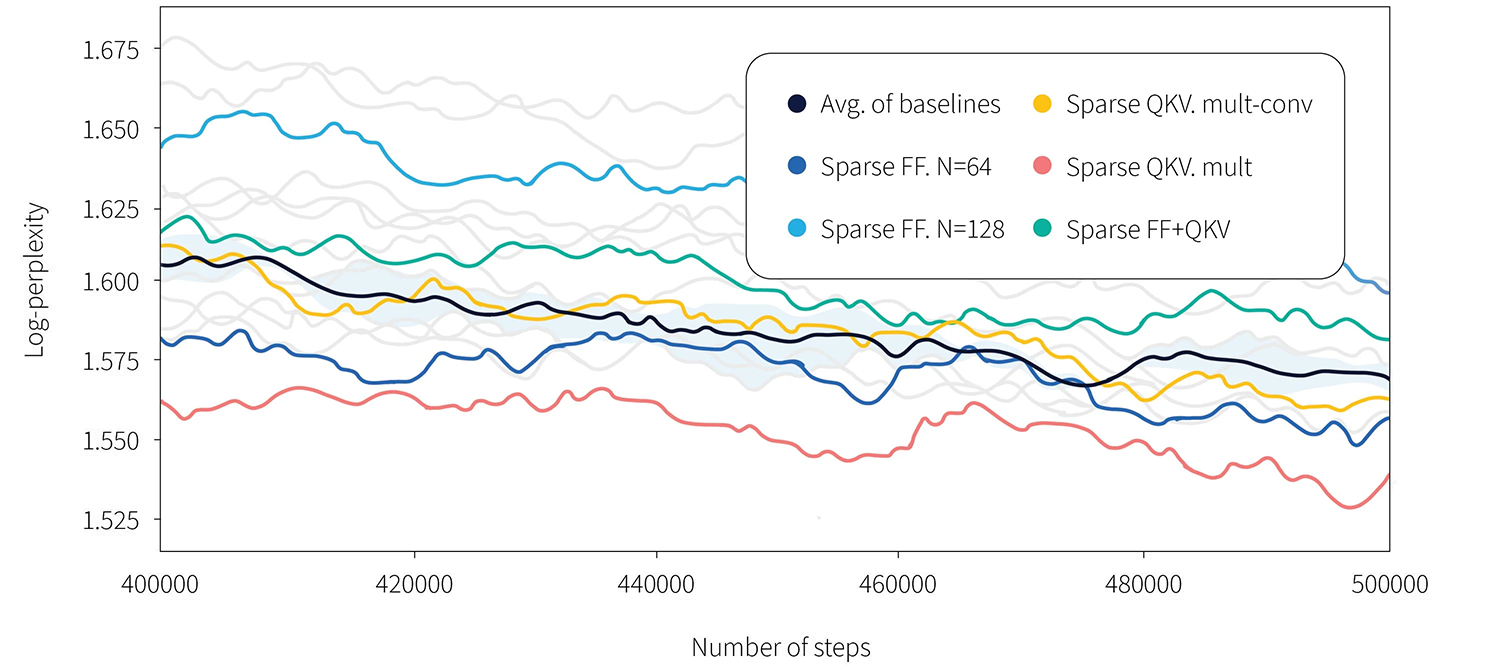
Figure 1. Log-perplexity of Scaling Transformers (equivalent to T5 large with approximately 800M parameters) on C4 dataset with proposed sparsity mechanisms (FF, QKV, FF+QKV) is similar to baseline dense model. Other models used in this paper are shown in grey lines; raw data is available in the appendix. Image derived from original source.
Scaling Transformers also yield competitive results on challenging real-world tasks like summarizing arxiv articles, as compared to state-of-the-art approaches.
Probabilistic Transformer for Time Series Analysis
Binh Tang, David S. Matteson
by Thibaut Durand
Why do we recommend?
Predicting the future is a fundamental research problem with a large range of applications like demand forecasting, autonomous driving, robotics, and health care. However this research problem is very challenging because future is uncertain. Probabilistic generative models have shown promising results for this problem. This paper introduces the Probabilistic Transformer (ProTran) model, which is a state space model (SSM) based on transformer architectures for multivariate time series. Unlike existing models, this model does not rely on recurrent neural networks but relies on the attention mechanism because the attention mechanism shows promising results to model long-range dependencies. Compared to transformer-based models, the Probabilistic Transformer model is able to capable of generating diverse long-term forecasts with uncertainty estimates. The Probabilistic Transformer model shows very good performances on several tasks like time series forecasting and human motion prediction. Probabilistic time series forecasting is an active research problem at RBC Borealis. I really like the Probabilistic Transformer model because it combines strengths of state space models and transformer architectures. I think that capturing the uncertainty inherent to the future can lead to strong time series forecasting models that will help to make better financial decisions.
Searching for Efficient Transform
David R. So, Wojciech Mańke, Hanxiao Liu, Zihang Dai, Noam Shazeer, Quoc V. Le
by Peng Xu
Why do we recommend?
In the past years, Transformers have shown great successes in multiple domains. However, the training cost of a Transformer can be expensive, in particular for the large models designed recently. This paper proposes to reduce the costs of Transformers by searching for a more efficient variant. To find Transformer alternatives, the authors designed a new search space. Then, they used the Regularized Evolution with hurdles search algorithm to find the most training efficient architecture in the search space. They discovered a new model called Primer (PRIMitives searched transformER). The main finding is that the compute savings of Primer over Transformers increase as training cost grows, when controlling for model size and quality. The authors also found that the improvements of Primer over Transformer can be mostly attributed to two main modifications: squaring ReLU activations and adding a depth-wise convolution layer after each Q, K, and V projection in self-attention. It is interesting to see these modifications are easy to implement and can be easily added into existing Transformer architecture codebase. The authors observed that these changes can significantly speed up training of existing Transformer models without additional tuning. Improving the training of Transformers is an active research area at RBC Borealis. Making training efficient can be critical for models working on non-stationary data like time series forecasting models. I like this paper because it shows that some small architectural changes can improve a lot the training of Transformers.

Variational inference
Local Disentanglement in Variational Auto-Encoders Using Jacobian L1 Regularization
Travers Rhodes, Daniel D. Lee
by Amir Abdi
Why do we recommend?
One of the challenges of Representation Learning with Variational Auto-Encoders (VAEs) is the model identification issue related to the rotational symmetries of the latent space caused by the rotational invariance of the standard Gaussian prior. The mentioned rotational symmetries in the latent space can cause strong correlations between latent variables, which, in turn, hinders disentanglement. Moreover, because of the lack of rotational constraints, high variations are observed in-between experiments on different seeds with respect to the disentanglement metrics.
In this work, and inspired by Independent Component Analysis (ICA) the authors propose the Jacobian L1 regularized VAE as an extension of BetaVAE with an added L1 norm on the Jacobian of the generator function to address the rotational identifiability issue. The L1 loss encourages local alignment of the axes of the latent representation with individual factors of variation. They demonstrate improvements on extended versions of disentanglement metrics, i.e., MIG and Modularity, which focus on local disentanglement across factors of variations, compared to BetaVAE, FactorVAE, DIP-VAE-I, DIP-VAE-II, BetaTcVae, and annealed-VAE. This solution helps with local alignment of the factors of variation, yet, does not address global alignment. Because the full Jacobian of the generator is calculated during training, the compute time is scaled linearly with the number of latent dimensions.
Work With Us!
RBC Borealis is looking to hire for various roles across different teams. Visit our career page now and discover opportunities to join similar impactful projects!
Careers at RBC Borealis