

Skynet team (left to right): Matt Taylor, Chao Gao, Pablo Hernandez-Leal and Bilal Kartal.
The Pommerman environment [1] is based off of the classic Nintendo console game, Bomberman. It was set up by a group of machine learning researchers to explore multi-agent learning and push state-of-the-art through competitive play in reinforcement learning.
The team competition was held on December 8, 2018 during the NeurIPS conference in Montreal. It involved 25 participants from all over the world. The RBC Borealis team, consisting of Edmonton researchers Chao Gao, Pablo Hernandez-Leal, Bilal Kartal and research director, Matt Taylor, won 2nd place in the learning agents category, and 5th place in the global ranking including (non-learning) heuristic agents. As a reward, we got to haul a sweet NVIDIA Titan V GPU CEO Edition home. Here’s how we pulled it off.
1. The rules of engagement
The Pommerman team competition consists of four bomber agents placed at the corners of an 11 x 11 symmetrical board. There are two teams, each consisting of two agents.
Competition rules work like this:
- At every timestep, each agent has the ability to execute one of six actions: they can move in any one of four cardinal directions, remain in place, or plant a bomb.
- Each cell on the board can serve as a passage (the agent can walk over it), a rigid wall (the cell cannot be destroyed), or a plank of wood (the cell can be destroyed with a bomb).
- The game maps, which function as individual levels, are randomly generated; however, there is always a guaranteed path between any agents so that the procedurally generated maps are guaranteed to be playable.
- Whenever an agent plants a bomb it explodes after 10 timesteps, producing flames that have a lifetime of two timesteps. Flames destroy wood and kill any agents within their blast radius. When wood is destroyed, the fallout reveals either a passage or a power-up (see below).
- Power-ups, which are items that impact a player’s abilities during the game, can be of three types: i) they increase the blast radius of bombs; ii) they increase the number of bombs the agent can place; or iii) they give the ability to kick bombs.
- Each game episode lasts up to 800 timesteps. There are two ways to end a game: if a team wins before reaching this upper bound, the game is over. If not, a tie is called at 800 timesteps and the game ends that way.
An example of a Pommerman team game.
2. Challenges
The Pommerman team competition is a very challenging benchmark for reinforcement learning methods. Here’s why:
- Sparse, delayed reward: The agents receive no reward until the game ends, which can take up to 800 timesteps. This singular reward is either +1 or -1. When both agents die at the same timestep, they will each get assigned a -1, which makes the temporal credit-assignment problem [2] challenging. The credit assignment problem tries to address the issue of rewarding atomic actions from a sparse delayed reward.
- Noisy rewards: In the Pommerman game, the observed rewards can be noisy due to potential suicides. For example, consider the simpler scenario of playing with only two agents – in this case, our learning agent and an opponent. We consider episodes a false positive when our agent gets a reward of +1 because the opponent commits suicide (not due to our agent’s combat skill), and a false negative episode would occur when our agent gets a reward of -1 due to its own suicide. False negative episodes are a major bottleneck for learning reasonable behaviours with pure exploration within model-free RL. In addition, false positive episodes can also reward agents for arbitrary (passive) policies such as camping, rather than actively engaging with the opponent.

An example of a full board with four agents.

An example of the partial observable views for each agent.
- Partial observability: The agents can only observe a region immediately around them. This creates several problems. For instance, an agent can die without even seeing a bomb if its blast radius is larger than the agent’s observation area. Another problem arises when bombs move after they are kicked by an agent. Bombs turn into projectiles which, together with the chain of explosions, make the environment very stochastic.
- Vast search space: Given six available actions for each of the four agents and provided with simultaneous game-play, the number of possible actions in the joint search space clocks in at 1296. Since one entire Pommerman game can last up to 800 timesteps, we can estimate the search space complexity as (1296)^800 ≈ 10^2400; i.e., much larger than that of Go.
- Lack of a fast-forward simulator: The competition requires near real-time decision-making, i.e., within 100ms per move. However, the built-in game forward model is rather slow. This renders vanilla search algorithms ineffective. For this reason, adaptations should be made to the standard algorithms, such as the Hybrid search agent [3] winner of the first competition. A second example is a customized Monte Carlo tree search agent (not submitted to the competition), that is used for our concurrent research to be presented at the AAAI-19 Workshop on RL in Games in January [4].
- Difficulty of learning to place a bomb: Since agents must learn to place a bomb in order to eliminate the enemy, it becomes an essential skill to have. However, a learning agent often ends up committing suicide while performing exploration, and thus it can learn to not place a bomb, a choice that encourages trained agents to behave in a cowardly fashion [1]. The agents need to learn a variety of skills that are applicable across randomized boards and opponents.
When an agent is in the early stage of training, it commits suicide many times.
After some training, the agent learns to place bombs near the opponent and move away from the blast.
- Multi-agent challenges [5]: A submission for the team competition consists of two agents. One problem that surfaces in this environment is the coordination aspect for the two agents since they are not allowed to share a centralized controller. A second challenge is the competitive nature of the environment since the team does not have prior knowledge of the opponents they are about to face. A third challenge involves multiagent credit assignment: in the team environment, the same episodic reward is given to two members of the same team. There is no information about the clear contribution of each individual agent.
- Opponent generalization challenge: The Pommerman simulator comes with a scripted (rule-based) agent, called SimpleAgent, that can be trained against. SimpleAgent collects power-ups and places bombs when it is near an opponent. It is relatively skilled in avoiding blasts from bombs and uses Dijkstra’s algorithm on each time-step. The behaviour of SimpleAgent is stochastic, and based on the power-ups it collects, its behaviour changes further. For example, if the agent collected several ammo power-ups, it can place too many bombs, thus triggering chain explosions, or it can commit suicide more frequently. In a preliminary experiment, we trained RL agents against a SimpleAgent. Our trained agents learned how to win the games by exploiting an opponent vulnerability.
Our learning agent (white) is highly skilled against a SimpleAgent. It avoids the blasts and also learns how to trick SimpleAgent to commit suicide in order to win without having to place any bombs.
When we examined the behavior of our learning agent against SimpleAgent we discovered that our agent had learned how to force SimpleAgent to commit suicide. It started when SimpleAgent first placed a bomb, then took a movement action to go toward a neighbor cell X. Our agent, after learning this opponent behaviour, then took a movement action to simultaneously go to the cell X, and thus, by game-engine forward model both were sent back to their original location in the next time step. In other words, our agent had learned a flaw in SimpleAgent and exploited this flaw to win the games by forcing it to commit suicide. This pattern was repeated until the bomb went off, successfully blasting SimpleAgent. This policy is optimal against SimpleAgent; however, it lacks generalization against other opponents since these learning agents learned to stop placing bombs and make themselves easy targets for exploitation.
Notes: This generalization over opponent policies is of utmost importance when dealing with dynamic multiagent environments and similar problems have also been encountered in Laser Tag [6].
In single-agent tasks, faulty (and strange) behaviors have also been observed [7]. A trained RL agent for CoastRunners discovered a spot in the game where, due to the unexpected mismatch between maximum possible reward and intended behaviour, RL agent can obtain higher scores in this spot rather than finishing the game.
3. Our Skynet team
A Skynet team is composed of a single neural network and is based on five building blocks:
- parameter sharing [10]
- reward shaping [12]
- an Action Filter module
- opponent curriculum learning [14]
- an efficient RL algorithm [13].
We make use of the parameter sharing mechanism; that is, we allow the agents to share the parameters of a single network. This allows the network to be trained with the experiences of the two agents. However, it still allows for diverse behavior between agents because each agent receives different observations.
Additionally, we added dense rewards to help the agent improve learning performance. We took inspiration from the difference reward mechanism to provide agents with a more meaningful contribution of their behavior, this in contrast to simply using the single global reward.
Our third block, ActionFilter module, built on the philosophy of installing prior knowledge to the agent by telling the agent what it should not do, then allowed the agent to discover what to do by trial-and-error, i.e., learning. The benefit is twofold: 1.) the learning problem gets simplified; and 2.) superficial skills, such as avoiding flames or evading bombs in simple cases, are perfectly acquired by the agent.
It is worth mentioning that the above ActionFilter does not significantly slow down RL training as it is extremely fast. Together with neural net evaluation, each action still takes several milliseconds – a speed almost equivalent to pure neural net-forward inferring. For context, the time limit in the competition is 100 ms per move.
The neural net is trained by $\mathit{PPO}$, minimizing the following objective: \begin{equation}
\begin{split}
o(\theta;\mathcal{D}) & = \sum_{(s_t, a_t, R_t) \in \mathcal{D}} \Bigg[ -\mathit{clip}(\frac{\pi_\theta(a_t|s_t)}{\pi_\theta^{old}(a_t|s_t)}, 1-\epsilon, 1+\epsilon) A(s_t, a_t) + \\
& \frac{\alpha}{2} \max\Big[ (v_\theta(s_t) -R_t)^2, (v_\theta^{old}(s_t) + \mathit{clip}(v_\theta(s_t) – v_\theta^{old}(s_t), -\epsilon, \epsilon)-R_t)^2 \Big] \Bigg],
\end{split}
\end{equation}
where $\theta$ is the neural net, $\mathcal{D}$ is sampled by $\pi_\theta^{old}$, $\epsilon$ is a tuning parameter. Refer to PPO paper for details.
We let our team compete against a set of curriculum opponents:
- Static opponent teams: opponents do not move, nor place bomb.
- SmartRandomNoBomb: players that do not place bombs; however, they are “smart random”, i.e., they have the action filter as described above.
The reason we allowed the opponent to not place a bomb is that we realized the neural net can focus on learning true “blasting” skills, and not a skill that solely relies the opponent’s mistakenly suicidal actions. Also, this strategy avoids training on “false positive” reward signal caused by an opponent’s involuntary suicide.
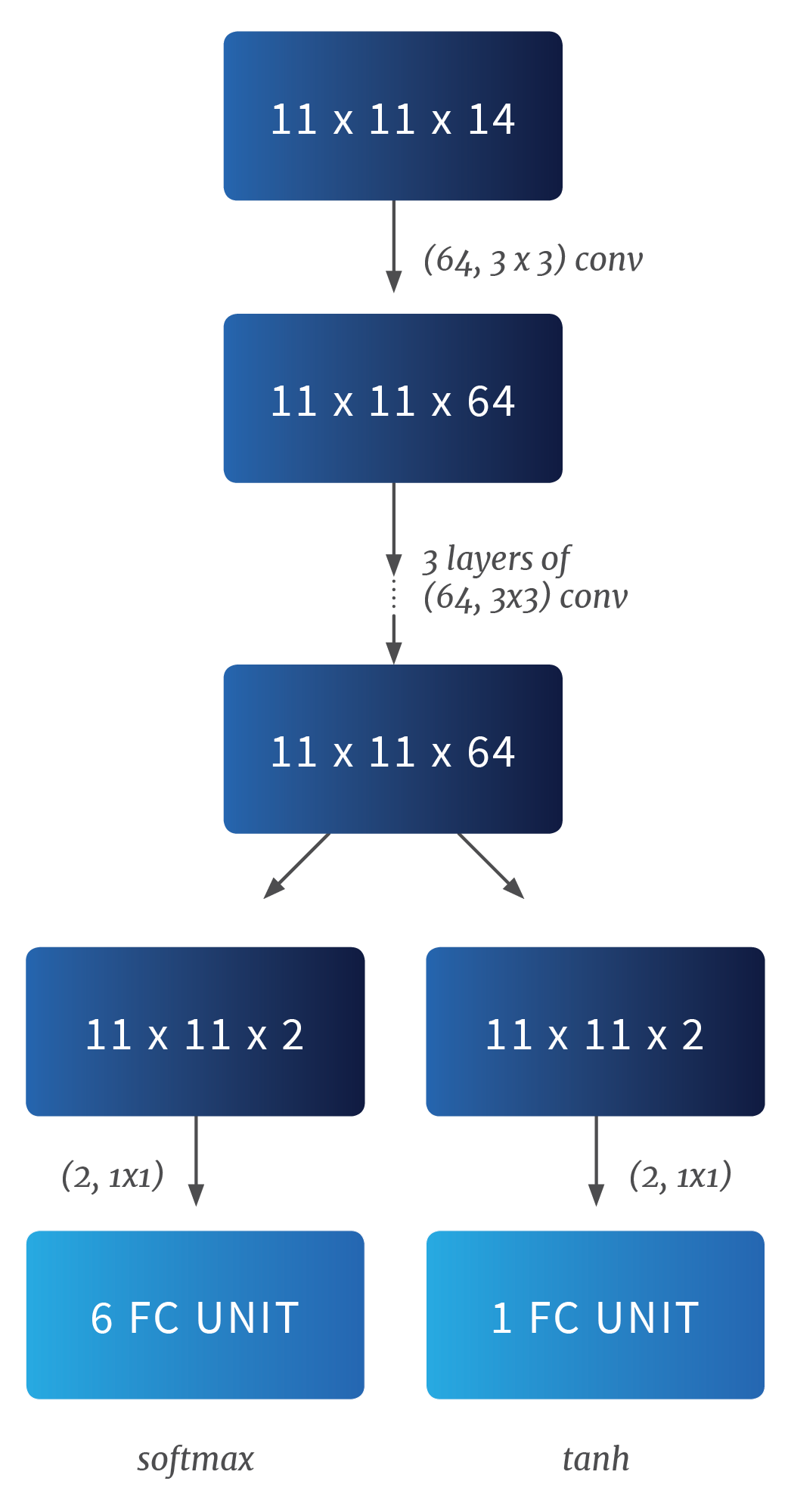
As shown in the figure below, the architecture first repeats four convolution layers, followed by two policy and value heads, respectively.
Instead of using an LSTM to track the observational history, we used a “retrospective board” to keep track of the most recent value of each cell on the board. For cells outside an agent’s purview, the “retrospective board” filled the unobserved elements of the board with the elements that were observed most recently. The input feature counts 14 planes in total, where the first 10 planes are extracted from the agent’s current observation, while the remaining four come from the “retrospective board”.
An example of a game between Skynet Team (Red) vs a team composed of two SimpleAgents (Blue).
4. The competition

The Pommerman team competition used a double-elimination style. The top three agents used tree search methods, i.e., they actively employed the game-forward model to look ahead for each decision by using heuristics. During the competition, these agents seemed to perform more bomb-kicking, which increased their chances of survival.
As mentioned in the introduction, our Skynet team won 2nd place on the category of learning agents, and 5th place on the global ranking, including (non-learning) heuristic agents. It is worth noting that scripted agents were not among the top players in this competition, which shows the high quality level amongst the tree search and learning methods.
Another one of our submissions, CautiousTeam, was based on SimpleAgent and – interestingly enough – wound up ranking 7th overall in the competition. CautiousTeam was submitted primarily for verifying the suspicion that a SimpleAgent without placing a bomb could be strong (or perhaps even stronger) than the winner [3] of the first competition held in June, i.e., a fully observable free-for-all scenario. It seems the competition results supported this suspicion.
5. Lessons learned and future work
Aside from being an interesting and (most importantly) fun environment, the Pommerman simulator was also designed as a benchmark for multiagent learning. We are currently exploring multi-agent deep reinforcement learning methods [5] by using Pommerman as a testbed.
- One direction we have been investigating is to combine search and learning agents in an imitation-learning framework. For example, planning algorithms can continuously provide expert trajectories that RL agents could mimic to speed up learning [4]. We mentioned earlier that vanilla search methods are too slow to be deployed for real-time game playing, but we can still use them during training, especially in distributed RL methods.
- Another direction we are considering, which we presented at the LatinX in AI Workshop at NeurIPS this year, is the use of Bayesian inference for opponent detection [8]. The idea is to intelligently reuse policies (skills) by quickly identifying the opponent we are facing.
- Lastly, we observed from the competition that effective cooperation in Pommerman is still an open problem. We are working in multi-agent deep learning methods that can cooperate better in order to achieve a task.
Acknowledgments
We would like to thank the creators of the Pommerman testbed, the competition organizers and the growing Pommerman community on Discord. We look forward to future competitions.
References
[1] Cinjon Resnick, Wes Eldridge, David Ha, Denny Britz, Jakob Foerster, Julian Togelius, Kyunghyun Cho, and Joan Bruna. Pommerman: A multiagent playground. arXiv preprint arXiv:1809.07124, 2018.
[2] Richard S. Sutton and Andrew G. Barto. Reinforcement learning: An introduction. MIT press, 2018.
[3] Hongwei, Zhou et al. “A hybrid search agent in pommerman.” Proceedings of the 13th International Conference on the Foundations of Digital Games. ACM, 2018.
[4] Bilal Kartal, Pablo Hernandez-Leal, and Matthew E. Taylor. “Using Monte Carlo Tree Search as a Demonstrator within Asynchronous Deep RL.” arXiv preprint arXiv:1812.00045(2018).
[5] Pablo Hernandez-Leal, Bilal Kartal, and Matthew E Taylor. Is multiagent deep reinforcement learning the answer or the question? A brief survey. arXiv preprint arXiv:1810.05587, 2018.
[6] Lanctot, Marc, et al. “A unified game-theoretic approach to multiagent reinforcement learning.” Advances in Neural Information Processing Systems. 2017.
[7] Open AI. Faulty Reward Functions in the Wild. Faulty Reward Functions in the Wild
[8] Pablo Hernandez-Leal, Bilal Kartal, and Matthew E Taylor. Skill Reuse in Partially Observable Multiagent Environments. LatinX in AI Workshop @ NeurIPS 2018
[9] LeCun, Yann, Yoshua Bengio, and Geoffrey Hinton. “Deep learning.” nature 521.7553 (2015): 436.
[10] J. N. Foerster, Y. M. Assael, N. De Freitas, S. Whiteson, Learning to communicate with deep multi-agent reinforcement learning, in: Advances in Neural Information Processing Systems, 2016,
[11] J. N. Foerster, N. Nardelli, G. Farquhar, T. Afouras, P. H. S. Torr, P. Kohli, S. Whiteson, Stabilising Experience Replay for Deep Multi-Agent Reinforcement Learning., in: International Conference on Machine Learning, 2017.
[12] Devlin, Sam, et al. “Potential-based difference rewards for multiagent reinforcement learning.” Proceedings of the 2014 international conference on Autonomous agents and multi-agent systems.
[13] Schulman, John, et al. “Proximal policy optimization algorithms.” arXiv preprint arXiv:1707.06347 (2017).
[14] Bansal, Trapit, et al. “Emergent complexity via multi-agent competition.” arXiv preprint arXiv:1710.03748 (2017).
Appendix
In this section, we provide more details on some of the aforementioned concepts as follows:
Difference rewards: This is a method to better address the credit assignment challenge for multi-agent teams. Relying only on the external reward, both agents receive the same team (global) reward independently of what they did in the episode. However, this renders multi-agent learning more difficult, as spurious actions can occasionally be rewarded, or some of the agents can learn to do the most of the jobs while the rest learn to be lazy. However, difference rewards [14] propose to compute the individual contribution without hurting the coordination performance. The main idea is very tidy: you compute individual rewards by subtracting the counterfactual reward computed without corresponding agents’ actions to the external global reward signal. Thus, team members are encouraged to optimize the overall team performance but also optimize their own contribution, so that no lazy agents can arise.
Centralized training and decentralized execution: Even though the team game scenario comes with partially observable execution, you can only hack the game simulator to access the full state during training. With full state access, you can train a centralized value function, which is used during training for actor-critic setting, but deployed agents will only utilize the policy network, i.e. that are trained with partial observations.
Dense rewards: There can be cases where an agent commits suicide and the remaining team member terminates the opposing team by itself. In the simplest case, both team members would get a +1 reward – i.e., suicidal agent is reinforced! We altered the single stark external reward for the first dying team member in order to address this issue where the first dying agent gets a smaller reward than last surviving one. This helped our agent improve game-play performance, although this modification comes with some expected and some unforeseen consequences. For instance, under this setting we can never have a team where one agent sacrifices itself (in such a configuration that it dies with the enemy simultaneously) for the team to win or that allows it to allot less credit to a hard-working agent that terminated an enemy but died when battling the second enemy.
Action filter description: We implement a filter with two categories:
For avoiding suicide
- Not going to positions that are filled flames next step.
- Not going to positions that are “doomed” by certain bombs. For bomb $b$, positions doomed by this bomb can be computed by referring a bomb’s “blast strength”, “blast range” and “life”, together with the local terrain via a dynamic programming procedure in $O(l^2)$ where $l$ is the “blast range”.
For placing bombs
- Not to place bomb when teammate is close.
- Not to place bomb when the agent’s position is covered by a certain bomb.