
Flora dramatically decreases the GPU memory needed to pre-train and fine-tune networks, without compromising speed or performance (figure 1). Depending on the context it can (i) significantly increase the size of the largest model that can be trained on a single GPU, (ii) reduce the number of GPUs needed to train models that exceed this limit, or (iii) incorporate updates from more data examples in a single pass (speeding up training). Using Flora is straightforward; in PyTorch, it simply replaces the existing optimizer. With Flora, it is possible to pre-train a 3B billion parameter LLM with a token batch size of 4096 on a single consumer grade GPU with 12 GB memory RTX-3060.
The modern era of deep learning was kickstarted by Krizhevsky et al. (2012) who trained AlexNet (a 62.3 million parameter model) on two GTX-580 GPUs with 6GB of combined GPU memory. In the immediately following years, rapid increases in GPU speed and memory meant that cutting-edge research required only modest resources. However, newer models contain billions of parameters and can require hundreds or thousands of GPUs to train in a practical time frame. Consequently, the ability to pre-train these models rests in the hands of the few; most practitioners can only fine-tune models in a tiny low-rank subspace of the full solution using methods like LoRA.
Flora partially restores the balance of power by dramatically reducing the GPU memory requirements of both pre-training and fine-tuning:
Pre-training: Flora permits the training of much larger models on a single GPU without sacrificing performance or speed; for example, it becomes possible to train a 3B or 7B parameter LLM with a token batch size of 4096 with less than 12 and 24 GB GPU memory respectively, available even with consumer grade GPUs. This is 50–100 times larger than AlexNet but requires only two to four times the memory.
Fine-tuning: A common approach to fine-tuning is low-rank adaptation (LoRA), which improves efficiency by updating a low-rank subspace of the full solution. Flora uses less GPU memory than LoRA and can fine-tune the full solution, yielding better performance. Moreover, benchmarks show that training speed is up to 25% faster than LoRA.
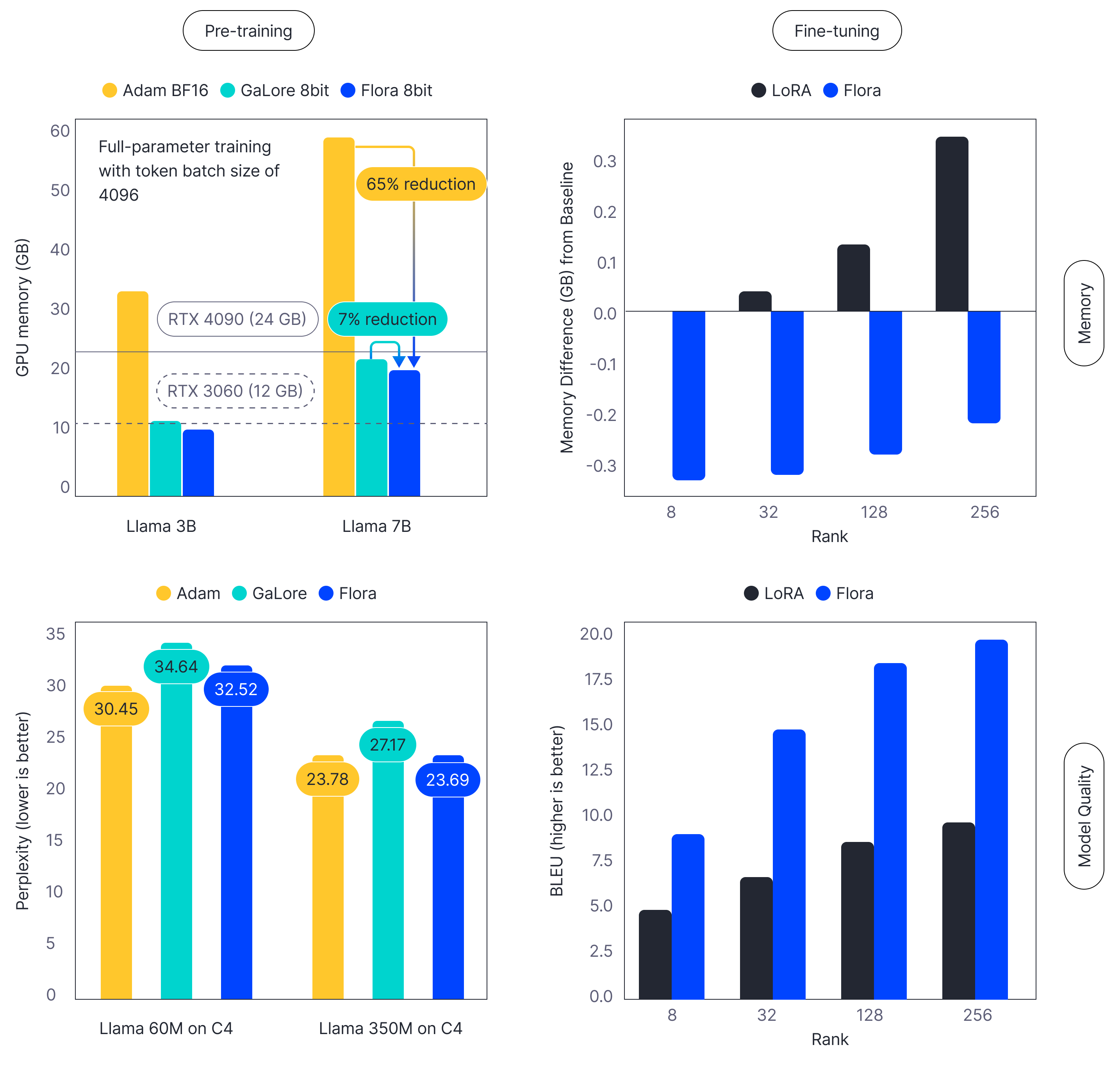
Figure 1: Flora performance. Flora uses less memory (first row) and yields better performance (second row) than contemporary methods in both pre-training (first column) and fine-tuning (second column).
Why are GPU memory savings important?
In principle being able to train a model on a single GPU facilitates data parallelism; different batches can be processed independently on different GPUs. For very large models that still don’t fit onto a single GPU, less memory consumption allows us to divide the model across fewer GPUs. For smaller models, Flora allows us to train with larger batch sizes, or to accumulate gradients from larger subsets of the batch in a single pass, speeding up training.
Given that Flora reduces the GPU memory requirements for training large models, is it now possible to pre-train one’s own state-of-the-art LLM on consumer GPUs? Unfortunately, scaling laws for LLMs imply that we must train with a vast corpus, which is still impractically time-consuming without parallelizing across many GPUs, even if the memory aspect is solved. One potential path forward is domain-adapted pre-training Gurangan et al. (2020), in which we continue to pre-train an open source with data from a specialized domain (e.g., as in NVIDIA’s ChipNeMo). Combined with Flora, this drastically lowers the barrier to building one’s own pre-trained LLMs on large private-domain corpora.
The structure of this blog is as follows. First, we show how to incorporate Flora into code. Second, we give a high-level overview of how Flora works. Third, we provide benchmark training results. Finally, we compare Flora to the subsequent and closely related GaLore method.
Incorporating FLORA into your code
There are implementations of Flora for both PyTorch and JAX. Further information about both can be found via the Flora repo.
PyTorch
To install Flora for PyTorch, use:
pip install 'flora-opt[torch]'To incorporate Flora into your code, simply import the package and replace the PyTorch optimizer with the Flora optimizer and the Hugging Face accelerator class with the Flora accelerator:
from flora_opt import FloraAccelerator, Flora
accelerator = FloraAccelerator(gradient_accumulation_steps)
optimizer = Flora(model.parameters(), lr=lr)JAX
To install Flora for JAX, use:
pip install 'flora-opt[jax]'To incorporate Flora into your code, simply import from the package:
from flora_opt import optax_florawhich works as an in-place replacement of Optax’s optimizers.
How Flora works
Flora linearly projects the gradients into a random low-dimensional subspace. The optimizer states (e.g., the momentum) are stored in this subspace and hence do not occupy much memory. When performing weight updates, the optimizer states are projected back up to the original space.
Many optimizer update rules (including momentum and AdaFactor) are compatible with this scheme because they rely on linear operations like averages and exponential moving averages. Likewise, gradient accumulation (in which gradients from multiple passes with different data examples are combined) can occur in the compressed space with no need to store the full gradients.
Importantly, the random projection changes frequently during training so that the optimization can sweep the entire parameter space rather than a fixed subspace like in LoRA. Whenever the random subspace changes, Flora carefully maps the compressed optimizer states into the new subspace before incorporating new information. The random projection matrices do not need to be stored but can be regenerated on the fly from a random seed. The full scheme is illustrated in figure 2.
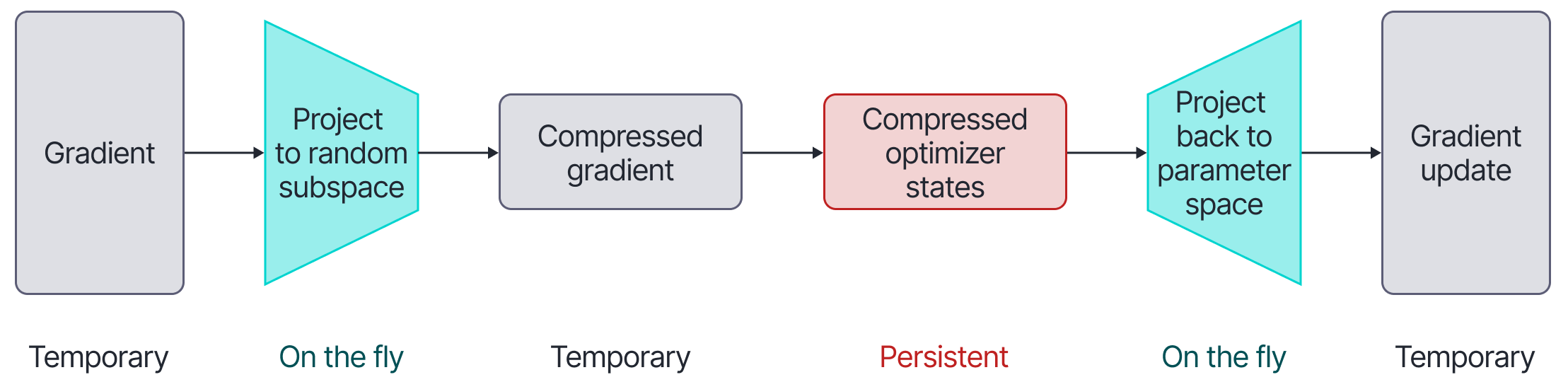
Figure 2: Flora. The gradient is projected to a random low-dimensional subspace and then used to update the optimizer states (e.g., the momentum term). This is then projected back to parameter space to make the update. Only the compressed optimizer states and the seed used to generate the random subspaces need be stored between the forward/backward passes.
Furthermore, Flora is orthogonal to many memory-efficient automatic differentiation techniques. Specifically, activation checkpointing (AC) recomputes the activations during back-propagation instead of storing them in the forward pass. LOMO, on the other hand, promptly updates the layer weight upon obtaining its gradient without waiting until all layers are finished. Both techniques are unaffected when using Flora. As a result, the peak memory allocated is only 21.2GiB for the 7B model.
To further illustrate how Flora works with and without AC and LOMO, we contrast it with the standard Adam optimizer. Typically, there are three components in deep learning training: the model parameters, the optimizer, and the activations. The overall procedure Adam is animated as follows:
Figure 3: Adam optimizer and memory usage: Adam needs to store the first and second-order moments for each parameter, which requires two times additional memory needed for the model parameters.
In Flora, we use low-rank random projections to compress the gradients. The overall procedure is as follows:
Figure 4: Flora without activation checkpointing (AC) and layer-by-layer update (LOMO).
The low-rank random projections reduces the memory usage by a factor of rank / d, where rank is the rank of the low-rank random projections and d is the dimension of the model parameters. In addition, the low-rank random projections can be generated on-the-fly using the random seed, which further reduces the memory usage.
When combined with AC and LOMO, each layer’s weight is updated immediately once its update tensor is computed. This allows the gradient, compressed gradient, activation, and updates at a layer to be freed immediately after the layer parameters are updated and the error signal for back propagation is computed:
Figure 5: Flora with activation checkpointing (AC) and layer-by-layer update (LOMO): only the parameters, compressed optimizer states, and at most one layer’s gradient occupy GPU memory at the same time; furthermore AC keeps a sublinear (in model depth) number of activations at each time.
Results (pre-training)
Figure 6 shows the minimum GPU memory required to pre-train models of various sizes using Adam, GaLore, and Flora.
| Peak Memory Required | |||
|---|---|---|---|
| Adam | GaLore 8-bit | Flora 8-Bit | |
| LLama-2 3B | 34.3 | 12.5 | 11.3 |
| LLama-2 7B | 59.9 | 22.9 | 21.2 |
For Adam, we assume that the model parameters/gradients are in BF16 and that the optimizer states are in FP32. Furthermore, we push the memory/speed trade-off to the limit to get the minimum memory requirement. This is achieved with gradient accumulation using the smallest batch size of one and gradient checkpointing. Note that our current PyTorch version is not currently as memory efficient as the JAX version. We hope to improve this in the future.
Comparison to GaLore
GaLore Zhao et al. (2024) was developed concurrently to Flora and achieves comparable memory savings for full parameter training. The intuition behind GaLore is the same as Flora (i.e., gradients of full parameter training can be compressed). However, Flora has three key advantages:
1. Projection matrix storage: GaLore projects onto the left singular vectors from the singular value decomposition. This projection matrix must be stored for subsequent use (for compressing more gradients or decompression). In contrast, Flora randomly generates the projection matrix and only needs to store the random seed to re-generate it for decompression. Consequently, Flora requires less memory.
2. Gradient accumulation: GaLore does not explore efficient gradient accumulation (in which gradients for different data examples are computed in separate passes and then summed to update the model). Naive gradient accumulation requires a space that is linear in the number of parameters, obviating the rationale for the technique. Flora handles this by storing the partial sum of the gradients in the compressed space.
3. Better momentum updates: Both methods periodically change the projection subspace. When that happens, GaLore adds the current step’s gradient projected in the new subspace to the momentum from the old subspace. The GaLore paper states this is not problematic because the relevant subspace along the optimization path changes slowly. However, for small batch sizes, noise could affect the stability of the SVD subspace. Conversely, Flora projects the momentum into the new subspace in a principled manner.
We empirically benchmarked against GaLore, using the hyper parameters and dataset from the GaLore paper, and found that Flora requires less memory (figure 1). Furthermore, Flora outperforms GaLore in terms of the perplexity scores.
| 60M (bs512) | 350M (bs512) | 7B (bs16) | ||
| Adam | Perplexity | 30.45 | 23.78 | – |
| Memory | 27.40 GB | 43.68 GB | >48GB | |
| GaLore (PyTorch) | Perplexity | 34.64 | 27.17 | – |
| Memory | 27.7GB | 36.5GB | 22.9GB | |
| Flora (PyTorch) | Perplexity | 32.52 | 23.69 | – |
| Memory | 27.5GB | 36.48GB | 21.2GB |
Furthermore, as an optimizer, Flora can be applied beyond models for the
text-domain. Table 2 shows Flora working with a vision transformer (ViT) architecture.
| Model | Optimizer | Accuracy | Memory |
|---|---|---|---|
| Base | Adam | 91.93 | 4.12 GiB |
| Base | Flora (r = 256) | 92.15 | 3.14 GiB (-23.8%) |
| Large | Adam | 92.97 | 8.57 GiB |
| Large | Flora (r = 256) | 92.98 | 5.79 GiB (-32.4%) |
It is worth noting that GaLore and Flora have complementary aspects that could benefit each other. Flora’s gradient accumulation could be ported to GaLore. Conversely, GaLore can work with any optimizer, while Flora currently has a specific form of compressed momentum and Adafactor style adaptive normalization. It would be useful to extend Flora to other forms as well.
Results (fine-tuning)
For fine-tuning, Flora outperforms LoRA in Rouge scores and memory efficiency. For more results, please see our paper. The results in Figure 7 use the JAX implementation for both Flora and LoRA, without gradient checkpointing, quantization, or momentum.
| Model Size | Method(rank) | Mem ↓ | R1 ↑/R2 ↑/RL ↑ |
|---|---|---|---|
| 60M | LoRA(8) LoRA(32) LoRA(128) LoRA(256) Flora(8) Flora(32) Flora(128) Flora(256) | 0.82 0.86 0.94 1.07 0.75 0.75 0.77 0.79 | 30.4/8.60/23.6 30.7/8.90/23.9 31.0/9.10/24.1 31.4/9.34/24.5 31.5/9.67/24.6 32.2/10.3/25.2 33.2/10.9/26.0 33.6/11.3/26.5 |
| 3B | LoRA(16) LoRA(64) LoRA(256) LoRA(512) Flora(16) Flora (64) Flora (256) Flora (512) | 27.8 29.5 33.4 OOM 17.0 18.2 19.5 22.1 | 42.2/18.4/34.0 42.3/18.6/34.1 42.6/18.9/34.4 – 43.5/20.0/35.5 43.9/20.3/35.8 44.3/20.7/36.2 44.5/20.9/36.4 |
Conclusion
Flora significantly decreases the memory required for training neural network models without decreasing performance. It is extremely easy to integrate with existing code and reduces the number of required GPUs or increases the speed of training. We hope that Flora will allow more researchers to explore full training, and increase the pace of algorithmic innovation.
Acknowledgement of Academic Partnership
This impactful use case of Flora is the outcome of RBC Borealis’s partnership with the Department of Computing Science at the University of Alberta, the Alberta Machine Intelligence Institute (AMII), and Mitacs.
Resources
If you use Flora, please cite our paper:
Bibtex
@inproceedings{
hao2024flora,
title={Flora: Low-Rank Adapters Are Secretly Gradient Compressors},
author={Yongchang Hao and Yanshuai Cao and Lili Mou},
booktitle={Forty-first International Conference on Machine Learning},
year={2024},
url={https://openreview.net/forum?id=uubBZKM99Y}
}