
The recent machine learning revolution has been fueled by data, and this data often comes from the end-users themselves. Consider a smartphone manufacturer trying to make typing faster and more accurate, a store trying to help its customers find the products they want, or a doctor trying to interpret a medical test. Machine learning can help, but only when fed with data about how people type, what they buy, and what kinds of medical tests and results patients receive. Consequently, organizations collect more and more data about their users to build these systems.
This raises concerns around the privacy of that data. Emails, text messages, and medical records contain sensitive information and the owners rightfully expect their privacy to be strongly guarded. At the same time, the potential benefits of (for instance) better medical diagnosis are undeniable. This leaves us with a challenge: how do we perform machine learning on data to enable technical advances without creating excessive risks to users’ privacy?
In this two part tutorial we explore the issue of privacy in machine learning. In part I we discuss definitions of privacy in data analysis and cover the basics of differential privacy. Part II considers the problem of how to perform machine learning with differential privacy.
Early approaches to privacy
We must first define what we actually mean by privacy in the context of data analysis. Early work struggled with how to find a formal definition of privacy that matches a user’s expectations while also being practical. To see why this is hard, let’s take a look at some earlier notions of privacy.
Anonmyzation and linkage attacks
The most straightforward approach is anonymization where identifying information is removed. For example, a name may be removed from a medical record. Unfortunately, anonymization is rarely sufficient to protect privacy as the remaining information can be uniquely identifying. For instance, given the gender, postal code, age, ethnicity and height, it may be possible to identify someone uniquely, even in a very large database.
Indeed, this famously happened to the Governor of Massachusetts, William Weld, in 1997. After an insurance group released health records which had been stripped of obvious personal information like patient name and address, an aspiring graduate student was able to “deanonymize” which records belonged to Governor Weld by cross referencing with public voter rolls. This is an example of a linkage attack, where connections to other sources of information work to deanonymize a dataset. Linkage attacks have been successful on a range of anonymized datasets including the Netflix challenge and genome data.
k-anonymity
One approach to prevent linkage attacks is k-anonymity. A dataset is said to be $k$ anonymous if, for any person’s record in a dataset, there are at least $k-1$ other records which are indistinguishable. So if a dataset is $k$-anonymous, then the best a linkage attack could ever do is identify a group of $k$ records which could belong to the person of interest. Even if a dataset isn’t inherently $k$-anonymous, it could be made so by removing entire fields of data (like names and addresses) and selectively censoring fields of individual people who are particularly unique.
Unfortunately, $k$-anonymity isn’t sufficient for anything but very large datasets with only small numbers of simple fields for each record. Intuitively, the more fields and the more possible entries there are in those fields, the more unique a record can be and the harder it is to ensure that there are $k$ equivalent records.
Centralized data and tracker attacks
Another solution is to not release the data. Instead, it is kept centralized by a trusted party which answers queries. But how do we ensure that those queries do not leak private information? One idea might be to allow only simple queries such as counting. Moreover, answers could only be returned when there is a minimal query set size (e.g., we are counting large numbers of records).
Unfortunately, this scheme is vulnerable to tracker attacks. Consider counting all records for patients who smoke, and then counting the number of patients that smoke whose name isn’t Marcus Brubaker. Both queries count large numbers of records but together identify whether Marcus smokes. Even if names aren’t available, a combination with a linkage attack could reveal the same information.
Fundamental law of information recovery
In the previous section we saw that simple approaches to data privacy are vulnerable to attacks. This raises the question of whether it is possible to guarantee individual privacy in a dataset. Indeed an early definition of privacy ensured that nothing could be learned about an individual when data was released. In essence this definition required that someone observing the released data would know nothing more about an individual’s record than before the observation. Unfortunately, this notion is flawed: if you cannot learn anything new from observing the released data then the released data must not have any information in it that wasn’t already available.
This raises a critical issue when it comes to understanding privacy with data analysis; it is impossible to allow for useful data analysis without at least some chance of learning about the underlying data. It has since been shown formally that for any query mechanism which doesn’t fully destroy information, an attacker given access to enough queries could eventually reconstruct the dataset. This result is referred to as the “Fundamental Law of Information Recovery” and makes explicit an inevitable trade-off. If you wish to extract useful information from a dataset, that brings with it a risk to the privacy of the data.
This may seem to doom the entire notion of private data analysis. But in fact it lays out clearly that the aim should be to quantify and limit how much privacy is actually lost. This is the goal of differential privacy.
Differential Privacy
Consider an individual who is deciding whether to allow their data to be included in a database. For example, it may be a patient deciding whether their medical records can be used in a study, or someone deciding whether to answer a survey. A useful notion of privacy would be an assurance that allowing their data to be included should have negligible impact on them in the future. As we’ve already seen, absolute privacy is inherently impossible but what is being guaranteed here is that that the chance of a privacy violation is small. This is precisely what differential privacy (DP) provides.
Randomized response
Differential privacy builds conceptually on a prior method known as randomized response. Here, the key idea is to introduce a randomization mechanism that provides plausible deniability. Consider a survey asking people whether they cheated on their taxes. As we have seen, queries about the results of that survey could potentially convey information about a single individual. However, imagine if the responses recorded in the survey were randomized; a coin is flipped and if the result is ‘heads’ a random answer is recorded instead of the true answer. With a little care it is still possible to use the survey results to estimate the fraction of people who cheated on their taxes. However, every individual has plausible deniability: the recorded response may or may not be the true value and hence individual privacy is protected.
In this example, there is a parameter which is the probability that the true response is recorded. If it’s very likely that the true response is recorded, then there is less privacy protection. Conversely, if it’s unlikely that the true response is recorded, then there is more. It’s also clear that, regardless of the probability, if an individual is surveyed multiple times, then there will be less protection, even if their answer is potentially randomized every time. Differential privacy formalizes how we define, measure and track the privacy protection afforded to an individual as functions of factors like randomization probabilities and number of times surveyed.
Classical definition of differential privacy
Consider two databases $\mathcal{D}$ and $\mathcal{D}’$. which differ by only a single record. In addition, we consider a randomized mechanism $\mbox{M}[\bullet]$ that operates on the databases to produce a result. This mechanism is differentially private if the results of $\mbox{M}[\mathcal{D}]$ and $\mbox{M}[\mathcal{D}’]$ are almost indistinguishable for every choice of $\mathcal{D}$ and $\mathcal{D}’$.
More formally, a mechanism $\mbox{M}[\bullet]$ is $\epsilon$-differentially private if for all subsets of output $\mathcal{S} \subset \mbox{Range}[\mbox{M}]$ and databases $\mathcal{D}$ and $\mathcal{D}’$
\[\Pr(\mbox{M}[\mathcal{D}]\in \mathcal{S}) \le \exp[\epsilon]\Pr(\mbox{M}[\mathcal{D}’] \in \mathcal{S}).\tag{1}
\]
The term $\epsilon$ controls how much the output of the mechanism can differ between the two adjacent databases and captures how much privacy is lost when the mechanism is run on the database. Large values of $\epsilon$ correspond to only weak assurances of privacy while values close to zero ensure that less privacy is lost.
This definition is rather opaque and if it doesn’t seem obvious then don’t worry. Later in this tutorial we will provide a number of easy-to-understand examples that will make these ideas clear. First though, we will re-frame the definition of differential privacy in terms of divergences.
Relation to divergences
There is a close connection between $\epsilon$-DP and divergences between probability distributions. A divergence is a measure of the difference between probability distributions. It is zero if the distributions are identical and becomes larger the more that they differ.
Since the mechanism $\mbox{M}[\bullet]$ is randomized, there is a probability distribution over its output. The mechanism is $\epsilon$-differentially private if and only if
\[\mbox{div}[\mbox{M}[\mathcal{D}] \Vert \mbox{M}[\mathcal{D}’]] \leq \epsilon\tag{2}
\]
for databases $\mathcal{D}$ and $\mathcal{D}’$ differing by at most a single record. Here $\mbox{div}[\cdot \Vert \cdot]$ is the Renyi divergence of order $\alpha=\infty$. In other words, $\epsilon$ quantifies how large the divergence can be between the distributions of results when the mechanism is applied to two neighbouring datasets (figure 1).

Figure 1. Differential privacy. Consider a dataset $\mathcal{D}$ (green box) and a second dataset $\mathcal{D}’$ (blue box) which differ by a single record. A randomized mechanism $\mbox{M}[\mathcal{D}]$ produces a distribution of possible random outputs on a given dataset $\mathcal{D}$. That mechanism is $\epsilon$-differentially private if and only if the Renyi divergence $\mbox{div}[\mbox{M}[\mathcal{D}] \Vert \mbox{M}[\mathcal{D}’]]$ of order $\alpha=\infty$ between the output of the mechanism on two neighbouring datasets is always bounded by $\epsilon$.
From the perspective of someone choosing to participate in a dataset where access was $\epsilon$-differentially private, the additional costs on average will be a factor of $\exp[\epsilon]$ higher than if they did not participate. Setting an appropriate value of $\epsilon$ for a given scenario is a challenging problem but these connections and guarantees can be used to help calibrate it depending on both the sensitivity of the data and the needs of the analysis.
Properties of Differential Privacy
The preceding discussion considers only a single fixed mechanism being run once. However, we’ve already seen that running multiple queries or using outside information could lead to privacy violations. How can we be sure this won’t happen here? Differentially private mechanisms have two valuable properties that allow us to make some guarantees.
Post-Processing: Differentially private mechanisms are immune to post-processing. The composition of any function with a differentially private mechanism will remain differentially private. More formally, if a mechanism $\mbox{M}[\bullet]$ is $\epsilon$-differentially private and $\mbox{g}[\bullet]$ is any function then $\mbox{g}[\mbox{M}[\bullet]]$ is also at least $\epsilon$-differentially private. This means that privacy will be preserved even in the presence of linkage attacks.
Composition: Differentially private mechanisms are closed under composition. Applying multiple mechanisms (or the same mechanism multiple times) still results in the overall mechanism being differentially private, but with a different $\epsilon$. Specifically, a composition of $k$ mechanisms, each of which are $\epsilon$-differentially private is at least $k\epsilon$-differentially private. This provides some guarantees about robustness to tracker attacks.
The post-processing property allows us to treat differentially private mechanisms as generic pieces. Any of the large library of differentially private mechanisms can be combined together while still preserving differential privacy. However, the composition theorem also makes plain that there is a limit; while composition preserves privacy, the value of $\epsilon$ increases and so the amount of privacy lost increases with every mechanism that is applied. Eventually, the value of $\epsilon$ will become so large that the assurances of differential privacy become practically useless.
The Laplace Mechanism
We’ll now examine one of the classical techniques for differential privacy. The Laplace Mechanism takes a deterministic function of a database and adds noise to the result. Much like randomizing the response to a binary question, adding noise to continuous valued functions provides “plausible deniability” of the true result and hence, privacy for any inputs into that computation.
Let $\mbox{f}[\bullet]$ be a deterministic function of a database $\mathcal{D}$ which returns a scalar value. For instance, it might count the number of entries that satisfy a condition. The Laplace mechanism works by adding noise to $\mbox{f}[\bullet]$:
\[\mbox{M}[\mathcal{D}] = \mbox{f}[\mathcal{D}] + \xi, \tag{3}
\]
where $\xi\sim \mbox{Lap}_{\xi}[b]$ is a sample from a Laplace distribution (figure 2) with scale $b$. The Laplace mechanism is $\epsilon$-differentially private with $\epsilon = \Delta\mbox{f}/b$. The term $\Delta \mbox{f}$ is a constant called the sensitivity which depends on the function $\mbox{f}[\bullet]$.
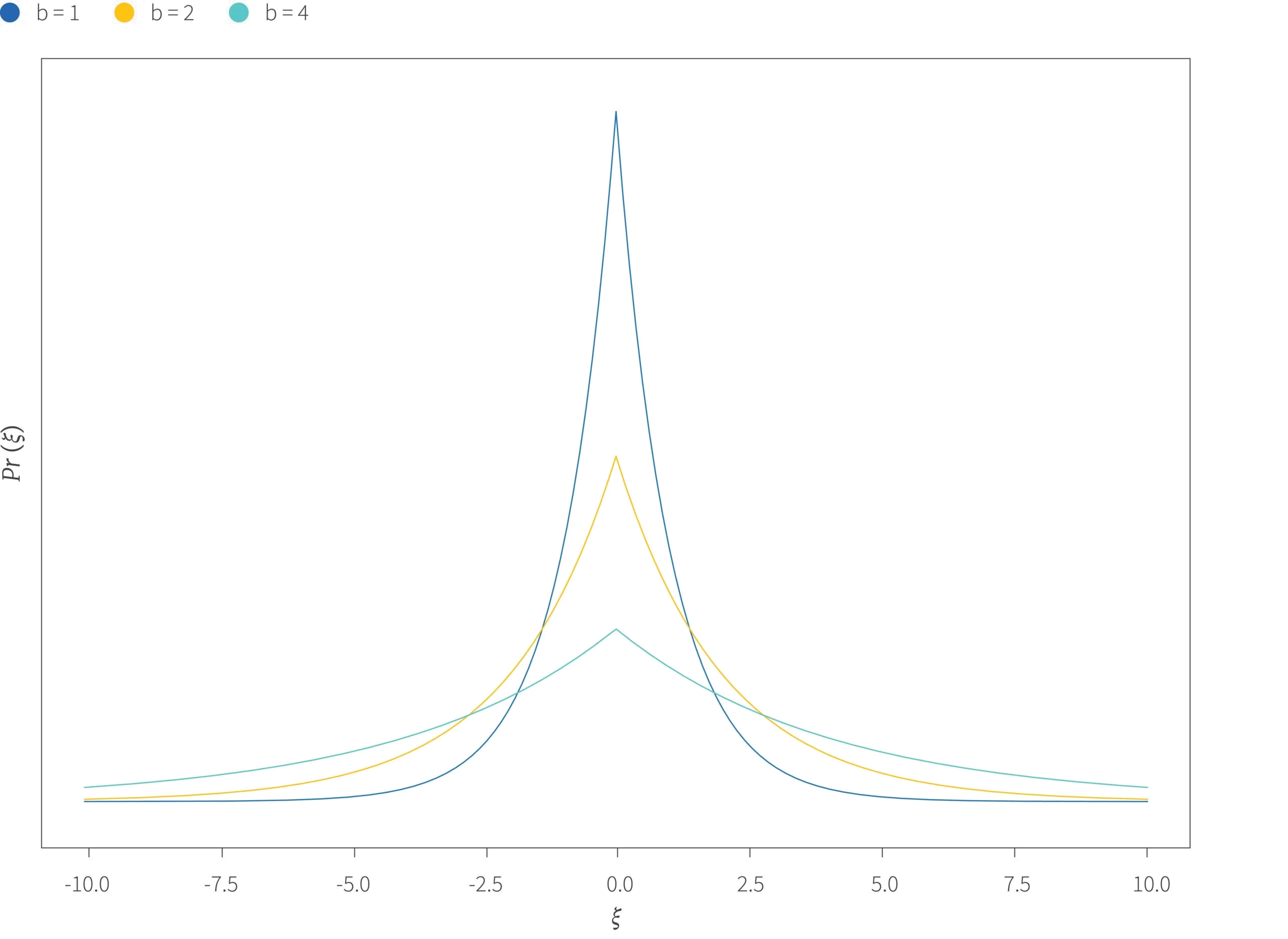
Figure 2. Laplace distribution. The probability density of the Laplace distribution for different values of scale parameter $b$. Like a normal distribution, the Laplace distribution is concentrated around zero and is symmetric. Unlike a normal distribution, the Laplace is sharply peaked at zero and has heavier “tails”, meaning that it’s more likely to produce large values. The scale parameter $b$ controls the spread of the distribution.
Let’s break down the components of this relationship. Larger amounts of noise better preserve privacy but at the expense of a less accurate response. This is controlled by the scale parameter $b$ of the Laplace distribution which makes the response given by $\mbox{M}[\bullet]$ less accurate for larger values of $b$. Here we see the trade-off between accuracy and privacy made explicit.
However, the amount of differential privacy afforded for a fixed value of $b$ depends on the function $f[\bullet]$ itself. To see why, consider adding Laplacian noise with $b=1$ to (i) a function which averages people’s income in dollars and (ii) a function which averages people’s height in meters. Figure 2 shows that most of the probability mass of this Laplacian noise will be between $\pm 3$. Since the expected range of the income function is much larger than that of the height function, the fixed added noise will have relatively less effect for the income function.
It follows that the amount of noise must be calibrated to the properties of the function. These properties are captured by the constant $\Delta \mbox{f}$ which determines how much the output of $\mbox{f}[\bullet]$ can change with the addition or removal of a single element. Formally, $\Delta \mbox{f}$ is the $\ell_1$ sensitivity of $\mbox{f}$ and is defined as
\[\Delta \mbox{f} = \max_{\substack{\mathcal{D}, \mathcal{D}’}} \Vert \mbox{f}[\mathcal{D}] – \mbox{f}[\mathcal{D}’] \Vert_{1}\tag{4}
\]
where $\Vert \cdot \Vert_1$ is the $\ell_1$ norm and $\mathcal{D}$ and $\mathcal{D}’$ differ in only one element.
Examples
To get a feel for this, we’ll present a few worked examples of functions that are made differentially private using the Laplace mechanism.
Example 1: Counting
We start with a function that counts the number of entries in the database $\mathcal{D}$ which satisfy a given property $\mathbb{I}(x)$:
\begin{equation}\mbox{f}_{count}[\mathcal{D}] = \sum_{x\in\mathcal{D}}\mathbb{I}(x). \tag{5}\end{equation}
Since adding or removing any element of this database can only change the count by a maximum of 1, we conclude that $\Delta \mbox{f}_{count} = 1$. Using the relation $\epsilon = \Delta \mbox{f}/b$. We can deduce that an $\epsilon$-differentially private mechanism for counting entries in a database is given by
\[\mbox{M}_{count}[\mathcal{D}] = \mbox{f}_{count}[\mathcal{D}] + \xi,\tag{6}
\]
where $\xi\sim\mbox{Lap}_{\xi}[\epsilon^{-1}]$ is a random draw from a Laplace distribution with parameter $b=\epsilon^{-1}$ (figure 3).
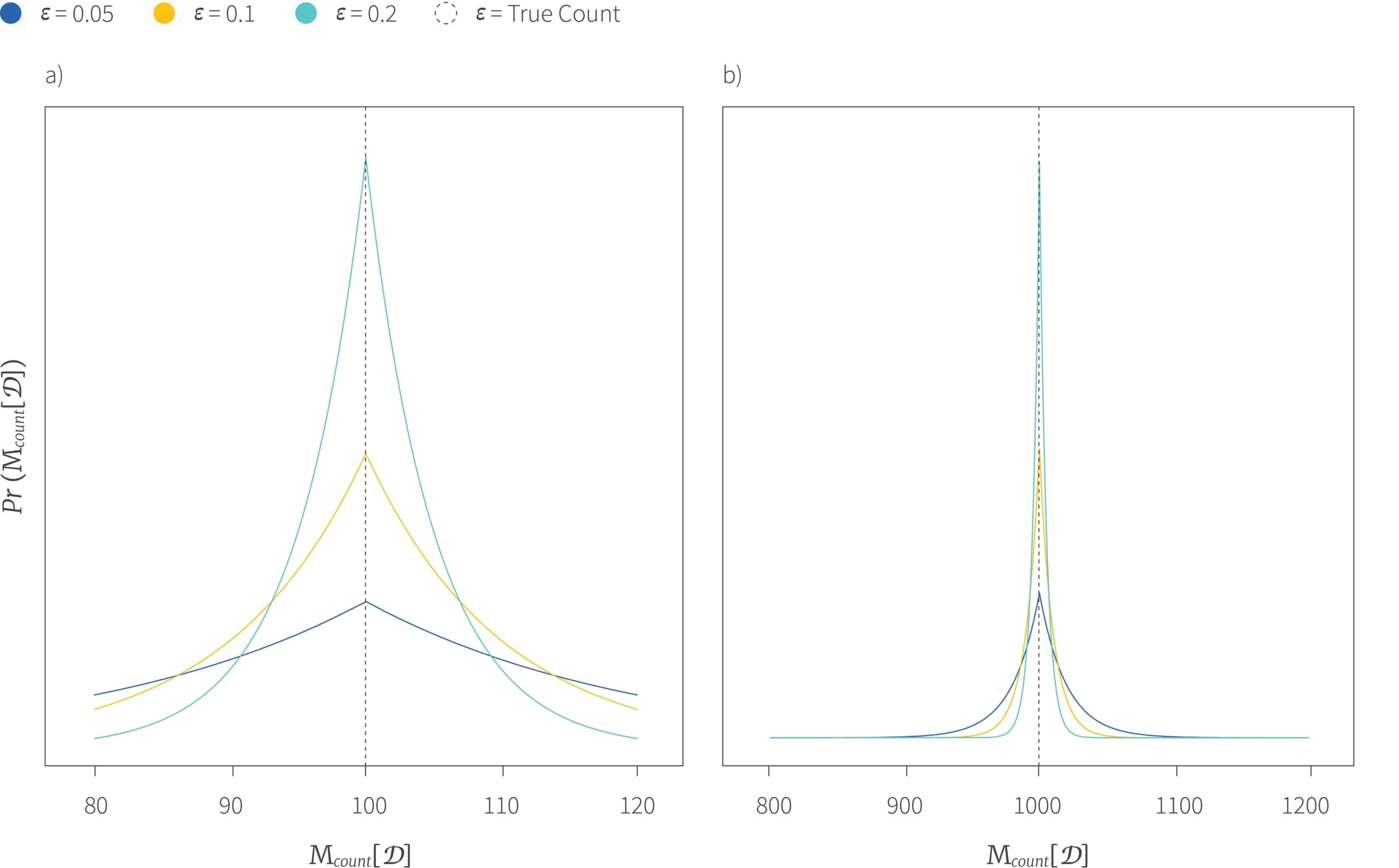
Figure 3. Laplace Mechanism for differentially private counting. a) The distribution of the expected output of $\mbox{M}_{count}[\mathcal{D}]$ for three different values of $\epsilon$ where the true count $\mbox{f}_{count}[\mathcal{D}] = 1000$. Here, all values of $\epsilon$ give reasonable distributions which almost always produce values within 10% of the true value (i.e., between 900 and 1100). Larger values of $\epsilon$ (which leak more privacy) provide distributions which are tighter around the true value and hence are more accurate. b) The distribution of the expected output of $\mbox{M}_{count}$ for a true count $\mbox{f}_{count}[\mathcal{D}] = 100$ for the same three different values of $\epsilon$. Here, for all three settings we will regularly deviate from the true answer by more than 10% from the true value (i.e., outside of the range 90 to 110). When a counting query depends on only a small number of elements, the amount of noise added for a given level of privacy ($\epsilon$) will be larger relative to the true value.
Example 2: Summing
A second simple function would be to sum the entries in the database $\mathcal{D}$ which satisfy a given property $\mathbb{I}(x)$:
\begin{equation}\mbox{f}_{sum}[\mathcal{D}] = \sum_{x\in\mathcal{D}} x\cdot\mathbb{I}(x). \tag{7}\end{equation}
Unfortunately, the $\ell_1$ sensitivity of this function, without any more information about the values of the field, is infinite; if the values can be arbitrarily large, then the amount that their sum could change with the addition or subtraction of a new entry is also arbitrarily large.
To work around this let’s assume that $C$ is an upper bound of absolute values in a given field so that $|x| \leq C$ for all possible values of $x$. Then the $\Delta \mbox{f}_{sum} = C$ and hence, an $\epsilon$-differentially private mechanism for summing entries in a database is given by adding Laplacian noise $\xi \sim \mbox{Lap}_{\xi}[\epsilon^{-1}C]$ with parameter $b=\epsilon^{-1}C$. If we don’t know the value of $C$, then we can truncate the fields to a chosen value $C$ and report the sum of the truncated values, giving the same mechanism as before but with the additional parameter $C$, where smaller values of $C$ reduce the amount of noise added for privacy budget $\epsilon$.
Example 3: Averaging
Finally, let’s consider a function that averages the entries in a database $\mathcal{D}$ which satisfy a given property $\mathbb{I}(x)$. Following from the discussion of summing, we assume that we clip the values by $\pm C$ before the computation. There are many different ways we can go about implementing such an operation but we’ll begin by again directly applying the Laplace mechanism. Consider the function
\[\mbox{f}_{avg} = \begin{cases}
\frac{\sum_{x\in\mathcal{D}} x\cdot \mathbb{I}(x)}{\sum_{x\in\mathcal{D}} \mathbb{I}(x)} & \hspace{0.5cm}\sum_{x\in\mathcal{D}} \mathbb{I}(x) > 0 \\
0 & \hspace{0.5cm}\sum_{x\in\mathcal{D}} \mathbb{I}(x) = 0,
\end{cases}\tag{8}
\]
where the second case is present to prevent division by zero when none of the elements satsify the property $\mathbb{I}(x)$.
The $\ell_1$ sensitivity of $\mbox{f}_{avg}$ is $C$.To see this consider the worst case scenario where $\mathcal{D}$ is the empty database (or there are no entries which satisfy the condition) and $\mathcal{D}’$ consists of exactly one new element with value $C$ then the result of $\mbox{f}_{avg}$ will change by exactly $C$. Hence, to achieve $\epsilon$ differential privacy, we must add noise $\xi\sim \mbox{Lap}_{\xi}[\epsilon^{-1}C]$. Notice that this is the same amount of noise that we added to the sum function, but the average is typically much less than the sum. Hence, this mechanism has very poor accuracy. It adds a lot of noise to account for the worst case scenario of the influence of a single record when the database is empty.
Example 4: Averaging using composition
A better approach to averaging can be found through the use of the composition and post-processing properties. We can combine the mechanisms for summing and counting to give the mechanism
\[\mbox{M}_{comp\ avg}[\mathcal{D}] = \mbox{M}_{sum}[\mathcal{D}]/ \mbox{M}_{count}[\mathcal{D}],\tag{9}
\]
which is $\epsilon_{comp\ avg} = \epsilon_{sum} + \epsilon_{count}$ differentially private. If we set $\epsilon_{sum} = \epsilon_{count} = \frac{1}{2}\epsilon_{avg}$ we get the same overall privacy cost for the two approaches to averaging. However, the accuracy of the compositional approach will be significantly better, particularly for larger databases (figure 4). The downside of this approach is that there is no longer simple additive noise on top of the true answer. This makes the relationship between $\mbox{f}_{avg}$ and $\mbox{M}_{comp\ avg}$ more complex and potentially complicates the interpretation of the output. See Section 2.5 of this book for other mechanisms for averaging.

Figure 4. Differentially private averaging. Histograms of the output of $\mbox{M}_{avg}$ (left) and $\mbox{M}_{comp\ avg}$ (right) for the same set of numbers and the same value of $\epsilon=0.01$. Because of the very high $\ell_1$ sensitivity of $\mbox{f}_{avg}$, $\mbox{M}_{avg}$ produces outputs which are practically meaningless. In contrast $\mbox{M}_{comp\ avg}$ results in a tight distribution around the true value with the same privacy budget. We can compute the average absolute deviation from the true value of both mechanisms and compare them to find that $\mbox{M}_{comp\ avg}$ is around 400 times more accurate in this case.
Other mechanisms and definitions of differential privacy
The above examples were based on the Laplace mechanism. However, this is not the only mechanism that induces differential privacy. The exponential mechanism can be used to provide differentially private answers to queries whose responses aren’t numeric. For instance “what colour of eyes is most common?” or “which town has the highest prevalence of cancer?”. It is also useful for constructing better mechanisms for numeric computations like medians, modes, and averages.
The Gaussian mechanism works by adding Gaussian noise instead of Laplacian noise and the level of noise is based on the $\ell_2$ sensitivity instead of $\ell_1$. The Gaussian mechanism is convenient as additive Gaussian noise is less likely to take on extreme values than Laplacian noise and generally better tolerated by downstream analysis. Unfortunately, the Gaussian mechanism only satisfies a weaker form of differential privacy known as $(\epsilon,\delta)$-differential privacy. Formally, a mechanism $\mbox{M}[\bullet]$ is $(\epsilon,\delta)$-differentially private if
\[\Pr[\mbox{M}[\mathcal{D}] \in \mathcal{S}] \le \exp[\epsilon]\Pr[\mbox{M}[\mathcal{D}’] \in \mathcal{S}] + \delta,\tag{10}
\]
for all subsets of output $\mathcal{S} \subset \textrm{Range}[M]$ and databases $\mathcal{D}$ and $\mathcal{D}’$ that differ by at most one element. $\epsilon$-differential privacy is stronger in the sense that it limits privacy loss even in worst case scenarios which can lead to large amounts of noise being required. In contrast, $(\epsilon,\delta)$-differential privacy allows for potentially large privacy breaches but only with probability $\delta$. Informally, you can think of an $(\epsilon,\delta)$-DP method being $\epsilon$-DP with probability $1-\delta$.
There are other definitions of differential privacy which aim to weaken $\epsilon$-differential privacy in different ways to make designing better mechanisms possible. The most notable of these is Renyi differential privacy which we’ll see in part II of our tutorial.
Conclusion
In this first part of this tutorial we have discussed the history of differential privacy, presented its formal definition, and showed how it can be used to construct differentially private approximations to some common database queries. For more details of these basics, the best source is this monograph .
In part II we’ll cover some examples of recently developed mechanisms including ones that allow us to perform differentially private machine learning while still building on standard ML tools. Finally, we’ll discuss differential privacy in the context of generative models and synthetic data generation.
Work with Us!
Impressed by the work of the team? RBC Borealis is looking to hire for various roles across different teams. Visit our career page now and discover opportunities to join similar impactful projects!
Careers at RBC Borealis