
Neural natural language generation (NNLG) refers to the problem of generating coherent and intelligible text using neural networks. Example applications include response generation in dialogue, summarization, image captioning, and question answering. In this tutorial, we assume that the generated text is conditioned on an input. For example, the system might take a structured input like a chart or table and generate a concise description. Alternatively, it might take an unstructured input like a question in text form and generate an output which is the answer to this question.
We will not focus on the input type; we assume that the input has been processed by a suitable encoder to create an embedding in a latent space. Instead, we concentrate on the decoder which takes this embedding and generates sequences of natural language tokens.
We will use the running example of neural machine translation: given a sentence in language A, we aim to generate a translation in language B. The input sentence is processed by the encoder to create a fixed-length embedding. The decoder then uses this embedding to output the translation word-by-word.
Encoder-decoder architecture
We’ll now describe the encoder-decoder architecture for this translation model in more detail (figure 1). The encoder takes the sequence $\mathbf{x}$ which consists of $K$ words $\{x_t\}_{t=1}^{K}$ and outputs the latent space embedding $\mathbf{h}$. The decoder takes this latent representation $\mathbf{h}$ and outputs a sequence of $L$ word tokens $\{\hat{y}_t\}_{t=1}^{L}$ one by one.
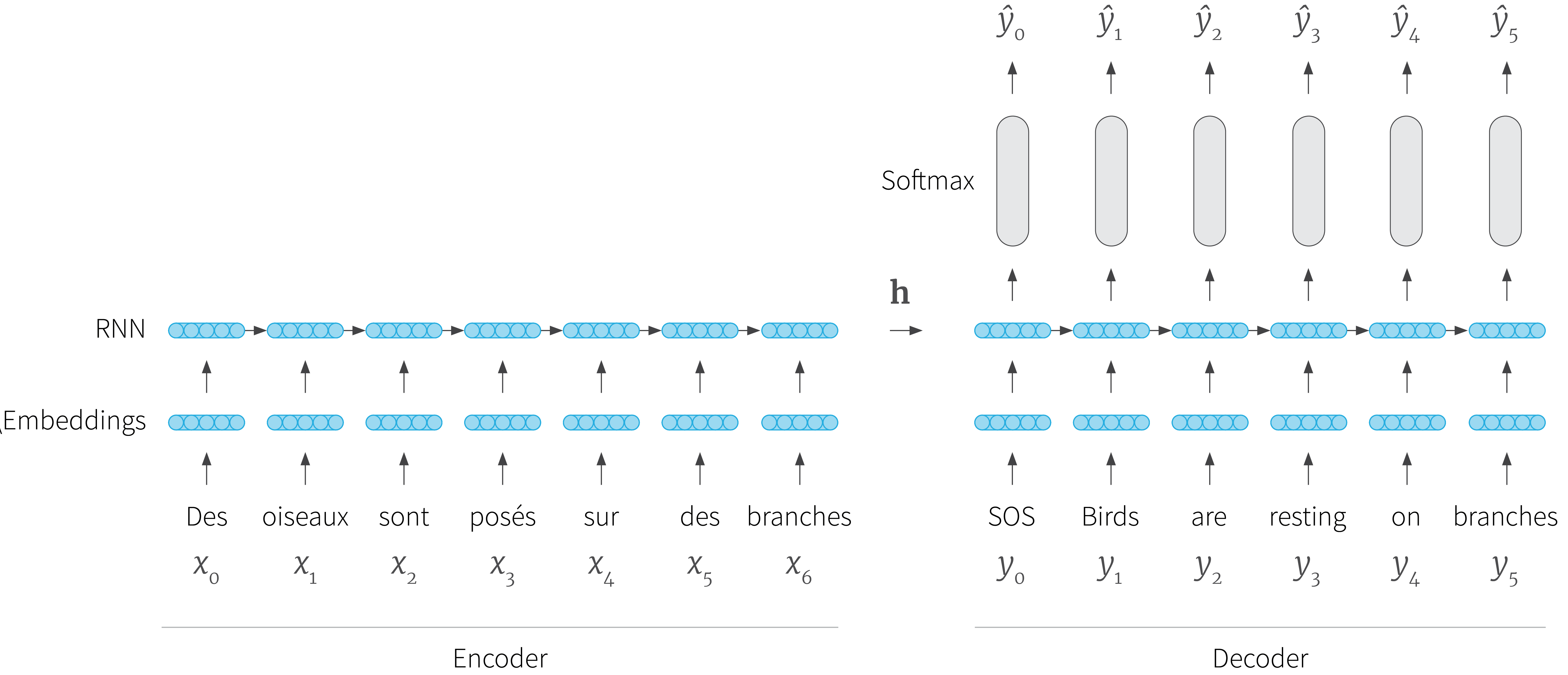
Figure 1. Natural language generation encoder-decoder architecture. The RNN-based encoder takes the input sentence in the form of a sequence of tokens $\{x_{t}\}_{t=1}^{k}$ and computes a latent state $\mathbf{h}$ which is fed to the decoder. At each step, the decoder takes the latent state and an input token $y_{t}$. It updates the state and returns a probability distribution over the vocabulary, from which it selects one word $\hat{y}_{t}$. The first input token $y_{0}$ is a special start of sentence (SOS) token. Subsequent input tokens consist of either the generated word from the previous time-step (during inference) or the ground truth word from the previous time-step (during training). Generation continues until an end of sequence (EOS) token is produced.
We consider an encoder which converts each word token to a fixed length word embedding using a method such as the SkipGram algorithm (Mikolov et al. 2013). Then these word embeddings are combined by a neural architecture such as a recurrent neural network (Sundermeyer et al. 2012), self-attention network (Vaswani et al. 2017), or convolutional neural network (Dauphin et al. 2017) to create a fixed-length hidden state $\mathbf{h}$ that describes the whole input sequence.
At each step $t$, the decoder takes this hidden state and an input token, and outputs a probability distribution over the vocabulary $\mathcal{V}$ from which the output word $\hat{y}_{t}$ can be chosen. The hidden state itself is also updated, so that it knows about the history of the generated words. The first input token is always a special start of sentence (SOS) token. Subsequent tokens correspond to the predicted output word from the previous time-step during inference, or the ground truth word during training. There is a special end of sentence (EOS) token. When this is generated, it signifies that no more tokens will be produced.
Tutorial Overview
This tutorial is divided into two parts. In this first part, we assume that the system has been trained with a maximum likelihood criterion and discuss algorithms for the decoder. We will see that maximum likelihood training has some inherent problems related to the fact that the cost function does not consider the whole output sequence at once and we’ll consider some possible solutions.
In the second part of the tutorial we change our focus to consider alternative training methods. We consider fine-tuning the system using reinforcement learning or minimum risk training which use sequence-level cost functions. Finally, we review a series of methods that frame the problem as structured prediction. A summary of these methods is given in table 1.
| Type of method | Training | Inference |
|---|---|---|
| Decoding algorithms | Maximum likelihood Maximum likelihood Maximum likelihood Maximum likelihood Maximum likelihood Maximum likelihood | greedy search beam search diverse beam search iterative beam search top-k sampling nucleus sampling |
| Sequence-level fine-tuning | Fine-tune with reinforcement learning Fine-tune with minimum risk training Scheduled sampling | greedy search/beam search beam search |
| Sequence-level training | Beam search optimization SeaRNN Reward augmented max likelihood | greedy search / beam search beam search greedy search / beam search beam search |
Maximum likelihood training
In this section, we describe the standard approach to train encoder-decoder architectures, which uses the maximum likelihood criterion. Specifically, the model is trained to maximize the conditional log-likelihood for each of $I$ input-output sequence pairs $\{\mathbf{x}_{i},\mathbf{y}_{i}\}_{i=1}^I$ in the training corpus so that:
\begin{equation}\label{eq:local_max_like} L = \sum_{i=1}^{I} \log\left[ Pr(\mathbf{y}_i | \mathbf{x}_i, \boldsymbol\phi)\right] \tag{1}\end{equation}
where $\boldsymbol\phi$ are the weights of the model.
The probabilities of the output words are evaluated sequentially and each depends on the previously generated tokens, so the probability term in equation 1 takes the form of an auto-regressive model and can be decomposed as:
\begin{equation}Pr(\mathbf{y}_i | \mathbf{x}_i, \boldsymbol\phi)= \prod_{t=1}^{L_i} Pr(y_{i,t} |\mathbf{y}_{i,<t}, \mathbf{x}_i, \boldsymbol\phi). \tag{2}\end{equation}
Here, the probability of token $y_{i,t}$ from the $i^{th}$ sequence at time $t$ depends on the tokens $\mathbf{y}_{i,<t} = \{y_{i,0}, y_{i,1},\ldots y_{i,t-1}\}$ seen up to this point as well as the input sentence $\mathbf{x}_{i}$ (via the latent embedding from the encoder).
This training criterion seems straightforward, but there is a subtle problem. In training, the previously seen ground truth tokens $\mathbf{y}_{i,<t}$ are used to compute the probability of the current token $y_{i,t}$. However, when we perform inference with the model and generate text, we no longer have access to the ground truth tokens; we only know the actual tokens $\hat{\mathbf{y}}_{i,<t}$ that we have generated so far (figure 2).
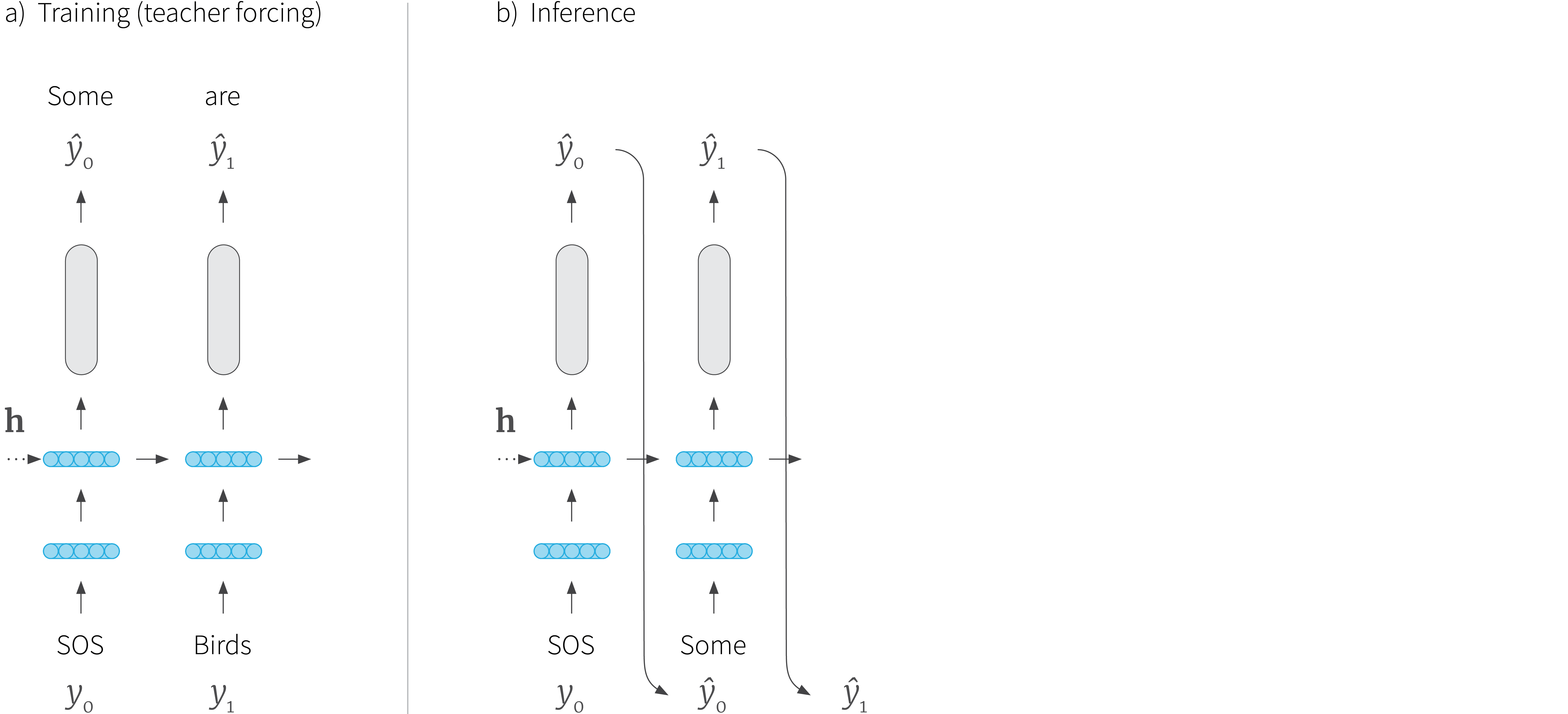
Figure 2. Local training vs. inference. a) In training, the ground truth tokens are used for input at each stage. This is known as teacher forcing. b) However, in inference, we do not have access to these, and so we pass in the previously generated tokens. In this sense, the training and inference distributions might differ.
The approach of using the ground truth tokens for training is known as teacher forcing. In a sense, it means that the training scenario is unrealistic and does not map to the real situation when we perform inference. In training, the model is only exposed to sequences of ground truth tokens, but sees its own output when deployed. As we shall see in the following discussion, this exposure bias may result in some problems in the decoding process.
Inference: maximizing sequence likelihood
We now return to the decoding (inference) process. At each time step, the system predicts the probability $Pr(\hat{y}_t |\hat{\mathbf{y}}_{<t}, \mathbf{x}, \boldsymbol\phi)$ over items in the vocabulary, and we have to select a particular word from this distribution to feed into the next decoding step. The goal is to pick the sequence with the highest overall probability:
\begin{equation}Pr(\hat{\mathbf{y}} | \mathbf{x}, \boldsymbol\phi) = \prod_t Pr(\hat{y}_t | \hat{\mathbf{y}}_{<t},\mathbf{x}, \boldsymbol\phi). \tag{3}\end{equation}
Finding the most probable sequence
In principle, we can simply compute the probability of every possible sequence by brute force. However, there are as many choices as there are words $|\mathcal{V}|$ in the vocabulary for each position and so a sentence of length $L$ would have $|\mathcal{V}|^{L}$ possible sequences. The vocabulary size $|\mathcal{V}|$ might be as large as 50,000 words and so this might not be practical.
We can improve the situation by re-using partial computations; there are many sequences which start in the same way and so there is no need to re-compute these partial likelihoods. A dynamic programming approach can exploit this structure to produce an algorithm with complexity $\mathcal{O}[L|\mathcal{V}|^2]$ but this is still very expensive.
Since we cannot find the sequence with the maximum probability, we must resort to tractable search strategies that produce a reasonable approximation of this maximum. Two common approximations are greedy search and beam search which we discuss respectively in the next two sections.
Greedy search
The simplest strategy is greedy search. It consists of picking the most likely token according to the model at each decoding time step $t$ (figure 3a).
\begin{equation} \hat{y}_t =\underset{w \in \mathcal{V}}{\mathrm{argmax}}\left[ Pr(y_{t} = w | \hat{\mathbf{y}}_{<t}, \mathbf{x}, \boldsymbol\phi)\right] \tag{4}\end{equation}
Note that this does not guarantee that the complete output $\hat{\mathbf{y}}$ will have high overall probability relative to others. For example, having selected the most likely first token $y_{0}$, it may transpire that there is no token $y_{1}$ for which the probability $Pr(y_{1}|y_{0},\mathbf{x},\boldsymbol\phi)$ is high. It might have been overall better to choose a less probable first token, which is more compatible with a second token.

Figure 3. Greedy search vs. beam search a) In greedy search, we choose the most likely word (here ‘Birds’) at each stage and feed this into the next stage. b) In beam search we maintain $B$ hypotheses (‘Birds’, ‘The’ and ‘Some’) about the sentence up to this point. For each of these hypotheses we evaluate the probability of adding every word to the next position. We then retain the $B$ most likely overall combinations.
Beam search
We have seen that searching over all possible sequences is intractable, and that greedy search does not necessarily produce a good solution. Beam search seeks a compromise between these extremes by performing a restricted search over possible sequences. In this regard, it produces a solution that is both tractable and superior in quality to greedy search (figure 3b).
At each step of decoding $t$, the $B$ most probable sequences $\mathcal{B}^{t-1} =\{\hat{\mathbf{y}}_{<t,b}\}_{b=1}^{B}$ are stored as candidate outputs. For each of these hypotheses the log probability is computed for each possible next token $w$ in the vocabulary $\mathcal{V}$, so $B|\mathcal{V}|$ probabilities are computed in all. From these, the new $B$ most probable sequences $\mathcal{B}^t =\{\hat{\mathbf{y}}_{<t+1,b}\}_{b=1}^{B}$ are retained. By analogy with the formula for greedy search, we have:
\begin{equation}\label{eq:beam_search} \mathcal{B}^t =\underset{w \in \mathcal{V},b\in1\ldots B}{\mathrm{argtopk}}\left[B, Pr(y_{t} = w | \hat{\mathbf{y}}_{<t,b}, \mathbf{x}, \boldsymbol\phi)\right] \tag{5}\end{equation}
where the function $\mathrm{argtopk}[K,\bullet]$ returns the set of the top $K$ items that maximize the second argument. The process is repeated until EOS tokens are produced or the maximum decoding length is reached. Finally, we return the most likely overall result.
The integer $B$ is known as the beam width. As this increases, the search becomes more thorough but also more computationally expensive. In practice, it is common to see values of $B$ in the range 5 to 200. When the beam width is 1, the method becomes equivalent to greedy search.
Problems with maximum likelihood training
When we train a decoder with a maximum-likelihood criterion, the resulting sentences can exhibit a lack of diversity. This happens at both (i) the beam level (many sentences in the same beam may be very similar) and (ii) the decoding level (words are repeated during one iteration of decoding). In the next two sections we look at methods that have been proposed to ameliorate these issues.
Inference: encouraging diversity
While beam search is superior to greedy search, it often produces sentences that have the same or a very similar start (figure 4a). Decoding is done in a left-to-right fashion and the probability weights are often concentrated at the beginning; even if search is performed over $B$ sentences, the weight of the first few words will mean that most of these sentences start with these words and there is little diversity.
| 4a) Beam Search A steam engine train travelling down train tracks. A steam engine train travelling down tracks. A steam engine train travelling through a forest. A steam engine train travelling through a lush green forest. A steam engine train travelling through a lush green countryside. A train on a train track with a sky background. |
| 4b) Diverse Beam Search A steam engine train travelling down train tracks. A steam engine train travelling through a forest. An old steam engine train travelling down train tracks. An old steam engine train travelling through a forest. A black train is on the tracks in a wooded area. A black train is on the tracks in a rural area. |
This raises the question of whether the likelihood objective correlates with our end-goals. We might care about other criteria such as diversity, which is important for chatbots: if a chatbot always said the same thing in response to a generic input such as “how are you today?”, it would become quickly dull. Hence, we might want to factor in other criteria of quality when decoding.
Diverse beam search
To counter beam-level repetition, Vijayakumar et al. (2018) proposed a variant of beam search, called diverse beam search, which encourages more variation in the generated sentences than pure beam search (figure 4b). The beam is divided into $G$ groups. Regular beam search is performed in the first group to generate $B’=\frac{B}{G}$ sentences. For the second group, at step $t$ of decoding, the beam search criterion is augmented with a factor that penalizes token sequences that are similar to the first $t$ words of the hypotheses in the first group. For the third group, sequences that are similar to those in either of the first two groups are penalized, and so on (figure 5).

Figure 5. Diverse beam search procedure with $B=6$ total beams split into $G=3$ groups, and $B’=2$ sentences per group. The beam search criterion is augmented to discourage re-use of words in previous groups. For example, In the second group, at the first time step of decoding, “Some” is preferred to “Birds” because “Birds”was already in the output of the first group.
Vijayakumar et al. (2018) investigate several similarity metrics including Hamming diversity which penalizes tokens based on their number of occurrences in the previous groups.
Iterative beam search
Diverse beam search has the disadvantage that it only discourages sequences that are close to the final sequences found in previous beams. However, there may be significant portions of the space that were searched to find these hypotheses and since we didn’t store the intermediate results there is nothing to stop us from redundantly considering the same part of the search space again (figure 6).

Figure 6. Problem with diverse beam search. Here we have found the first beam, giving the two output sentences "Birds are standing on branches" and "Birds are resting on branches". Along the way the system searched and rejected the sentence fragment "There are". Unfortunately, in diverse beam search, this search history is not remembered and so the system can waste a lot of time re-exploring the same paths.
Kulikov et al. (2018) introduced iterative beam search which aims to solve this problem. It resembles diverse beam search in that beams (groups of hypotheses) are computed and recorded. These beams are ordered and each is affected by the previous beams. However, unlike diverse beam search we do not wait for a beam search to complete before computing the others. Instead, they are computed concurrently.
Consider the situation where at ouput time $t-1$ we have $G$ groups of beams, each of which contains $B^{\prime}$ hypotheses. We extend the first beam to length $t$ in the usual way; we consider concatenating every possible vocabulary word with each of the $B^{\prime}$ hypotheses, evaluate the probabilities and retain the best overall $B^{\prime}$ solutions of length $t$.
When we extend the second beam to length $t$, we follow the same procedure. However, we now set any hypotheses that are too close in Hamming distance to those in the first beam to have zero probability. Likewise, when we extend the third beam, we discount any hypotheses that are close to those in the first two beams. The result is that each beam is forced to explore a different part of the search space and the final results have increased diversity (figure 7).

Figure 7. Iterative beam search. The system finds solutions in multiple beams but now they interact with each other as they are generated, which prevents exploring the same parts of the search space repeatedly.
Inference: avoiding decoding-level repetition
Until this point, we have assumed that the best way to decode is by maximizing the probability of the output words, using either greedy search, beam search, or a variation on these techniques. However, Holtzman et al. (2019) demonstrate that human speech does not stay in high probability zones and is often much more surprising than the text generated by these methods.
This raises the question of whether we should sample randomly from the output probability distribution rather than search for likely decodings. Unfortunately, this can also lead to degenerate cases. Holtzman et al. (2019) conjecture that at some point during decoding, the model is likely to sample from the tail of the distribution (i.e., from the set of tokens which are much less probable than the gold token). Once the model samples from this tail, it might not know how to recover. In the next two sections, we consider two methods that aim to repress such behavior.
Top-k sampling
Fan et al. (2018) proposed top-$k$ sampling as a possible remedy. Consider one iteration of decoding at the $t$-th time step. Let us define $\mathcal{V}_{K,t}$ as the set of the $K$ most probable next tokens according to $Pr(y_{t}=w|\hat{y}_{<t},\boldsymbol\phi)$. Let us also define the sum $Z$ of these $K$ probabilities:
\begin{equation} Z = \sum_{w \in \mathcal{V}_K^t} Pr(y_{t}=w|\hat{\mathbf{y}}_{<t},\boldsymbol\phi). \tag{6}\end{equation}
Top-$k$ sampling proposes to re-scale these probabilities and ignore the other possible tokens:
\begin{equation} Pr(y_{t}=w | \hat{\mathbf{y}}_{<t}|\boldsymbol\phi) \leftarrow \begin{cases} Pr(y_{t}=w | \hat{\mathbf{y}}_{<t},\boldsymbol\phi) / Z & \text{if } w \in \mathcal{V}_K^t \\ 0 & \text{otherwise}. \tag{7} \end{cases}\end{equation}
With this strategy, we only sample from the $K$ most likely tokens and thus avoid tokens from the tail of the distribution (their probability is set to zero).
Unfortunately, it can be difficult to fix $K$ in practice. There exist extreme cases where the distribution is very peaked and so the top-$K$ tokens include tokens from the tail. Similarly, there may be cases where the distribution is very flat and valid tokens are excluded from the top-$K$ list.
Nucleus sampling
Nucleus sampling (Holtzman et al. 2019) aims to solve this problem by retaining a fixed proportion of the probability mass. They define $\mathcal{V}_\tau^t$ as the smallest set such that:\begin{equation*}
Z = \sum_{w \in \mathcal{V}^t_\tau} Pr(y_{t}=w|\hat{\mathbf{y}}_{<t}, \boldsymbol\phi) \geq \tau,
\end{equation*}
where $\tau$ is a fixed threshold. Then, as in top-$k$ sampling, probabilities are re-scaled to:
\begin{equation} Pr(y_{t}=w | \hat{\mathbf{y}}_{<t}|\boldsymbol\phi) \leftarrow \begin{cases} Pr(y_{t}=w | \hat{\mathbf{y}}_{<t},\boldsymbol\phi) / Z & \text{if } w \in \mathcal{V}_\tau^t \\ 0 & \text{otherwise}. \tag{8} \end{cases}\end{equation}
Since the set $\mathcal{V}_\tau^t$ is chosen so that the cumulative probability mass is at least $\tau$, nucleus sampling does not suffer in the case of a flat or a peaked distribution.
Discussion
Part I of this tutorial has highlighted some of the problems that occur during decoding. We can classify these problems into two categories.
First, maximum-likelihood trains the model to stay in high probability regions of the token space. As shown by Holtzman et al. (2019), this differs significantly from human speech. If we want to take into account other criteria of quality, such as diversity, search strategies must be put in place to explore the space of likely outputs and greedy sampling or vanilla beam search are not enough.
Second, the exposure bias introduced by teacher forcing forces NNLG models to be myopic, and only look for the next most likely token given a ground truth prefix. As a consequence, if the model samples a token from the long tail, it might enter a “degenerate” case. When this happens, the model “makes an error” by sampling a low-probability token and does not know how to recover from this error.
We have presented some sampling strategies that alleviate these issues at inference time. However, since these problems are both side-effects of the maximum likelihood teacher-forcing methodology for training, another way to approach this is to modify the training method. In part II of this tutorial, we describe how Reinforcement Learning (RL) and structured prediction help with both maximum-likelihood and teacher-forcing induced issues.
Work with Us!
Impressed by the work of the team? RBC Borealis is looking to hire for various roles across different teams. Visit our career page now and discover opportunities to join similar impactful projects!
Careers at RBC Borealis