
In the first part of this article, we introduced the encoder-decoder architecture for neural natural language generation (NNLG). We used the running example of machine translation (figure 1). We discussed how it is typically trained using a maximum likelihood criterion with teacher forcing. We also drew attention to two common failure modes of the decoding:
- If we use greedy search or beam search to select the output tokens, then the model’s output tends to stay in high probability regions and so the outputs are less diverse than realistic human speech.
- If we sample randomly from the predicted distribution over the output tokens then we get more diverse outputs, but can enter a degenerate state where phrases are repeated if a low probability token is chosen.
It is hypothesized that both of these phenomena are side-effects of using a training criterion that is based on predicting one word of the output sequence at a time and comparing to the ground truth.
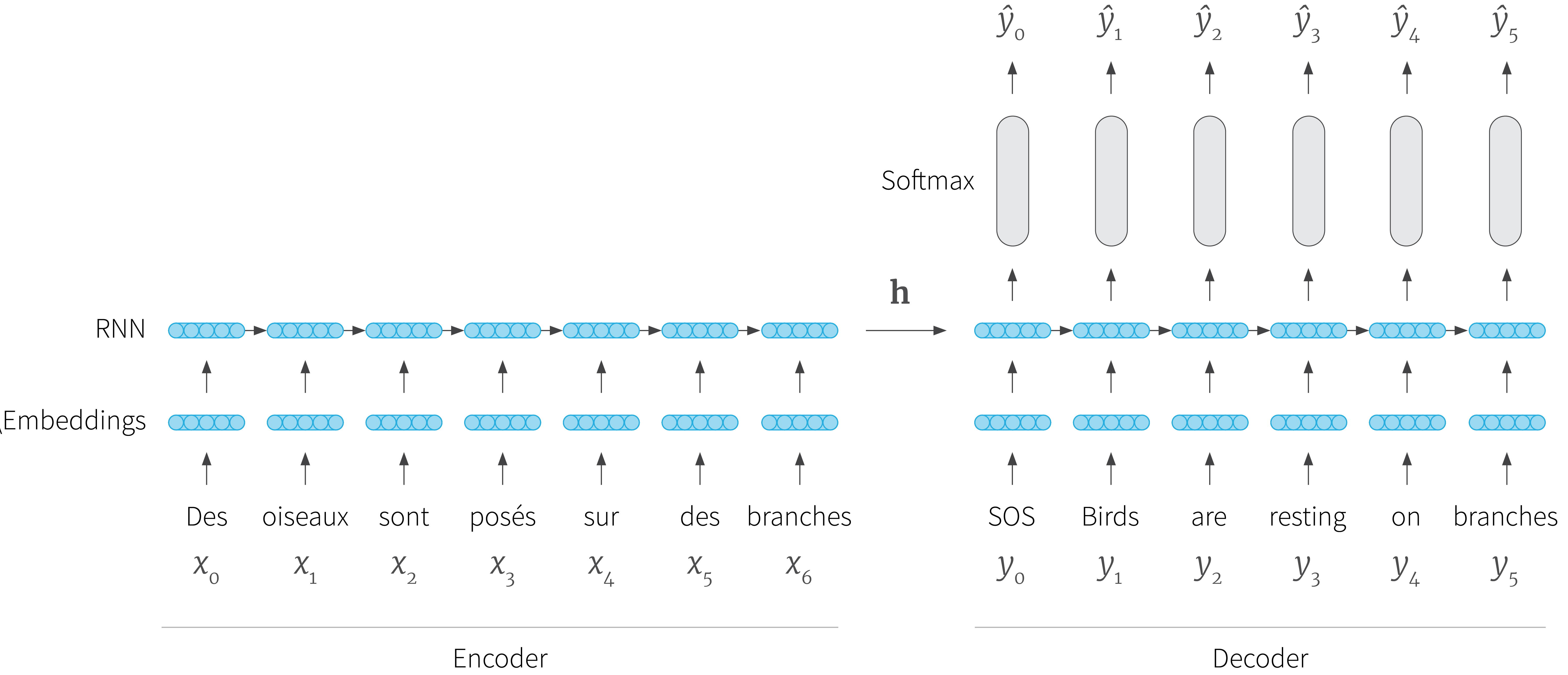
Figure 1. Recap of natural language generation encoder-decoder architecture for machine translation. The encoder takes the input sentence in the form of a sequence of tokens $\{x_{t}\}_{t=1}^{k}$ and computes a latent state $\mathbf{h}$ which is fed to the decoder. At each step, the decoder takes the latent state and an input token $y_{t}$. It updates the state and returns a probability distribution over the vocabulary, from which it selects one word $\hat{y}_{t}$. The first input token $y_{0}$ is a special start of sentence (SOS) token. Subsequent input tokens consist of either the generated word from the previous time-step (during inference) or the ground truth word from the previous time-step (during training). Generation continues until an end of sequence (EOS) token is produced. For more details see the first part of this tutorial.
In the second part of this tutorial (figure 2), we consider alternative training approaches that compare the complete generated sequence to the ground truth at the sequence level. We’ll consider two families of methods; in the first, we take models that have been trained using the maximum likelihood criterion and fine-tune them with a sequence-level cost function — we’ll consider using both reinforcement learning and minimum risk training for this fine tuning. In the second family, we consider structured prediction approaches which aim to train the model from scratch using a sequence level cost function.
| Type of method | Training | Inference |
|---|---|---|
| Decoding algorithms | Maximum likelihood Maximum likelihood Maximum likelihood Maximum likelihood Maximum likelihood Maximum likelihood | greedy search beam search diverse beam search iterative beam search top-k sampling nucleus sampling |
| Sequence-level fine-tuning | Fine-tune with reinforcement learning Fine-tune with minimum risk training Scheduled sampling | greedy search/beam search beam search |
| Sequence-level training | Beam search optimization SeaRNN Reward augmented max likelihood | greedy search / beam search beam search greedy search / beam search beam search |
Fine-tuning with reinforcement learning
Metrics that could provide a sequence-level comparison between the generated sentence and the ground truth include the BLEU (Papineni et al, 2002), ROUGE (Lin 2004), and METEOR (Bannerjee et al. 2005) scores. The best known of these is the BLEU score which compares the overlap of n-grams between the gold sequence and a generated sequence. This metric is not perfect because valid generated sentences that express the same ideas as the gold ones but with different words will be rated poorly. Despite its imperfections, the BLEU score has often been used to fine tune language generation models.
Unfortunately, the use of a sequence-level metric introduces a new problem. Unlike the maximum-likelihood criterion, the BLEU score is not easily differentiable. For a given output sentence it can be evaluated but there is no sense of how to smoothly change the sentence to improve it. The solution to this problem is to use reinforcement learning (RL) which, through its reward formalism, allows us to train a model to maximize a non-differentiable quantity. We will train the RL agent to output entire sequences (rather than just the next token) and learn from the feedback given from the BLEU reward function.
Reinforcement learning setup
Let’s briefly recap the reinforcement learning framework. In RL an agent performs actions in an environment and observes the consequences of these actions through (i) changes in the environment and (ii) a numerical reward which indicates whether the agent is achieving its task or not. More formally, an agent can choose actions from a set $\mathcal{A}=\{a_0,..,a_n\}$. At each time $t$ the agent makes an observation $\mathbf{o}_{t}$ and aggregates it with past observations into a state $\mathbf{s}_t$. The agent’s behaviour is called a policy $\boldsymbol\pi[a|\mathbf{s}_{t}]$ and describes the probability of taking action $a$ in state $\mathbf{s}_{t}$. The agent’s goal is to learn a policy which maximizes the expected sum of rewards at each state.
Now let’s map the RL framework to neural natural language generation. An action consists of selecting the next token, so there as many possible actions $a$ as there are words $y\in|\mathcal{V}|$ in the vocabulary. The policy $\boldsymbol\pi$ is a distribution over possible actions. Hence, we consider the policy to be the likelihood $Pr(y_{t}|\hat{\mathbf{y}}_{<t},\mathbf{x},\boldsymbol\phi)$ of producing different tokens $y_{t}$ given the previous tokens $\hat{\mathbf{y}}_{<t}$, the input sentence $\mathbf{x}$ and the model parameters $\boldsymbol\phi$. The reward is a computed score like BLEU which is only provided after generating the entire translated sentence; intermediate rewards are zero.1 The state $\mathbf{s}_{t}$ corresponds to the state of the decoder. Note that it’s not clear what constitutes the environment in this description; we will return to this question later.
Policy gradient approach for NNLG
The REINFORCE algorithm (Williams 1992) is a policy gradient method that describes the policy $\boldsymbol\pi[a|s,\boldsymbol\phi]$ as a function of parameters $\boldsymbol\phi$ and then manipulates these parameters to improve the rewards received. Translating to the NNLG case, this means that we will manipulate the parameters $\boldsymbol\phi$ of the model (technically we backpropagate through the encoder as well) so that it produces sensible distributions over the words at each step, and the resulting BLEU scores are good.
More specifically, the REINFORCE algorithm maximizes the expected discounted sum of rewards when the actions $a$ are drawn from the policy $\boldsymbol\pi$:
\begin{equation} J[\boldsymbol\phi] = \mathbb{E}_{a\sim \boldsymbol\pi\left[\boldsymbol\phi\right]}\left[\sum_{t=1}^L\gamma^{t-1}r[\mathbf{s}_t,\hat{y}_{t}]\right], \tag{1}\end{equation}
where $L$ is the length of a decoding episode, and $r[s_t,\hat{y}_{t}]$ is the reward obtained for generating word $\hat{y}_{t}$ when the decoder has hidden state $\mathbf{s}^t$. The term $\gamma\in(0,1]$ is the discount factor which weights rewards less the further they are into the future. For NNLG, we commonly only receive a reward at the end of the decoding when we compare to the BLEU score, and the intermediate rewards are all zero.
We need the derivative of this expression so we can change the parameters to increase this measure and this derivative is found using the policy gradient theorem (Sutton et al. 2000). The REINFORCE algorithm uses the resulting expression to estimate the derivative from a set of $I$ decoding results sampled with the current policy $\boldsymbol\pi[\boldsymbol\phi]$. The $i^{th}$ decoding result consists of series of tuples $\{\mathbf{s}_{i,t}, \hat{y}_{i,t}, r_{i,t}\}_{t=1}^{L_{i}}$ where each tuple consists of the decoder state $\mathbf{s}_{i,t}$ , the predicted tokens $\hat{y}_{i,t}$, and the rewards $r_{i,t}$ respectively. The estimated gradient is:
\begin{equation} \nabla J[\theta] \approx \frac{1}{I}\sum_{i=1}^{I}\sum_{t=1}^{L_{i}} \nabla_{\theta} \log \left[\boldsymbol\pi\left[\hat{y}_{i,t}|\mathbf{s}_{i,t},\boldsymbol\phi\right]\right] \left(Q^{\boldsymbol\pi}[\mathbf{s}_{i,t}, \hat{y}_{i,t}]- b[\mathbf{s}_{i,t}]\right) \tag{2}\end{equation}
where the state-action value function $Q^{\boldsymbol\pi}[\mathbf{s}_{i,t}, \hat{y}_{i,t}]$ is the expected sum of rewards $\mathbb{E}_{\sim \boldsymbol\pi}[\sum_{t’\geq t}^{T}\gamma^{t’-t} r[\mathbf{s}_{i,t’},\hat{y}_{i,t’}]|\mathbf{s}_{i,t},\hat{y}_{i,t}]$ after generating the token $\hat{y}_{i,t}$ given the state $\mathbf{s}_{i,t}$, and $b[\bullet]$ is a baseline function which helps reduce variance.
It is common that the state-action value function $Q^{\boldsymbol\pi}(s_{i,t}, \hat{y}_{i,t})$ is also estimated through Monte-Carlo roll-outs, which leads to:\begin{equation}
\nabla J[\theta] \approx \frac{1}{I}\sum_{i=1}^{I}\sum_{t=1}^{L_{i}} \nabla_{\theta} \log \left[\boldsymbol\pi\left[\hat{y}_{i,t}|\mathbf{s}_{i,t},\boldsymbol\phi\right]\right] \left(\sum_{t’=t}^T \gamma^{t’-t} r[\mathbf{s}_{i,t’}, \hat{y}_{i,t’}] – b[\mathbf{s}_{i,t’}]\right). \tag{3}
\label{eq:reinforce}
\end{equation}
Results of RL fine tuning
In practice, any RL fine-tuning approach must choose a decoding method. Wu et al. (2018) compare the performance of beam search and greedy search and find that RL fine-tuning seems to bring the largest improvement for greedy search. They explain this result in terms of exploration-exploitation trade-off. At each time step, the agent could choose to apply only the actions that it thinks are most valuable (exploitation), or it could choose to take different actions to increase its confidence in what it believes to be the best actions (exploration). Beam search exploits the current policy more efficiently than greedy search, and to the extent that greedy search is sub-optimal, it also permits more exploration of the sequence space.
RL fine-tuning has been shown to improve the performance of NNLG models for many tasks (Ranzato et al. 2017; Bahdanau et al. 2017; Strub et al. 2017; Das et al. 2017; Wu et al. 2018). However, the improvement over maximum likelihood training has been small (Wu et al. 2018) and although it is theoretically simple to move to an RL objective, in practice, it is not uncommon to have to resort to “tricks” to make it work (Bahdanau et al. 2017).
Training from scratch with RL
If RL is used as a solution to “fix” problems caused by log-likelihood training, then why not train a model with RL from scratch? Such training requires that the model outputs sequences, observes rewards, and updates its behaviour. However, it is highly unlikely that a randomly-initialized model would generate a sequence of tokens that would be relevant to a sentence to translate. Consequently, the model would never observe any significant reward and would be unable to learn to improve.
A different approach might be to use off-policy training which observes trajectories from another model and uses these to learn a policy; it differs from on-policy training in that it learns without ever actually generating tokens itself. For machine translation, the “other model” is the human who generated the gold translations. The NMT model observes these translations as well as the associated rewards, and updates its policy to maximize the expected sum of rewards at each state. To account for the differences between the learned policy and the gold policy, we use importance sampling and Equation 3 becomes:
\begin{eqnarray} \label{eq:offpol} \nabla J[\theta] &\approx& \\ &&\hspace{-1.3cm}\frac{1}{I}\sum_{i=1}^{I}\sum_{t=1}^{L_{i}} \frac{\boldsymbol\pi\left[y_{i,t}|\mathbf{s}_{i,t},\boldsymbol\phi\right]}{q(y_{i,t}|\mathbf{s}_{i,t})}\nabla_{\boldsymbol\phi} \log \left[\boldsymbol\pi\left[y_{i,t}|\mathbf{s}_{i,t},\boldsymbol\phi\right]\right] \left(\sum_{t’=t}^T \gamma^{t’-t} r[\mathbf{s}_{i,t’}, y_{i,t’}] – b[\mathbf{s}_{i,t’}]\right). \nonumber \tag{4}\end{eqnarray}
where $q(y_{i,t}|\mathbf{s}_{i,t})$ is the probability that a human would generate token $y_{i,t}$ given state $\mathbf{s}_{i,t}$.
This seems convenient, but there is a problem here too. Since the human-generated translation is the gold standard, the reward is always going to be the maximum BLEU score of 1. Consequently, the sum of rewards in Equation 4 is always 1 and the training objective reduces to negative log-likelihood. In fact, this method really only differs from ML training when trajectories are of variable quality and have different rewards, or when rewards for partial sequences are available (Zhou et al. 2017; Kandasamy et al. 2017), and even then we have the additional complication of having to estimate $q[\bullet].$ Overall, training with RL from scratch is not adapted to the usual case where only good generations are available for learning.
Reinforcement learning vs. structured prediction
Let’s return to the question of what exactly constitutes the ‘environment’ when we frame natural language generation as RL. One of the difficulties of RL training is that the agent must interact with the unknown environment. For each action that the agent takes, it must wait for the environment to provide a new observation to be able to decide its next action. The agent can thus only produce one trajectory at a time.
However, for natural language generation the environment is the decoder itself: it outputs a word and then directly updates its state solely based on this word, without requiring any external input. Therefore, we can run the decoding process as many times as we want since there is no external environment that conditions the states of the decoder.
In this sense, natural language generation might be better framed as structured prediction; we treat it as a machine learning problem with multiple outputs that are mutually dependent. For machine translation, these dependencies represent the constraints between words in the output sentence that ensure that it is syntactically correct and semantically meaningful. When we consider natural language generation in this light, we can contemplate methods in which we roll-out as many trajectories as computationally-feasible and learn through sequence-level costs like BLEU. Further discussion of the relationship between RL and structured prediction can be found in Daume (2017), and Kreuzer (2018).
Fine tuning with minimum risk training
Minimum risk Training (Shen et al. 2016) is a structured prediction technique that is practically very similar to the REINFORCE algorithm except that is does not only consider one generated translation of the input sentence at a time. Instead, it evaluates multiple possible translations $\{\hat{\mathbf{y}}_{j}\}$, computes a cost $\Delta[\hat{\mathbf{y}}_j, \mathbf{y}_i]$ for each, and weighs each cost by the probability $Pr(\hat{\mathbf{y}}_j|\mathbf{x}_i,\boldsymbol\phi)$ of its trajectory. The overall loss function $\mathcal{L}[\boldsymbol\phi]$ is the total cost:
\begin{equation} \mathcal{L}[\boldsymbol\phi] = \sum_{i=1}^{I}\left(\frac{1}{Z_{i}}\sum_{\hat{\mathbf{y}}_j \in \mathcal{S}[\mathbf{x}_i]} Pr(\hat{\mathbf{y}}_j|\mathbf{x}_i,\boldsymbol\phi)^{\alpha} \Delta[\hat{\mathbf{y}}_j, \mathbf{y}_i] \right) \tag{5}\end{equation}
where $\mathcal{S}[\mathbf{x}_i]$ is a selected subset of all possible translations of $\mathbf{x}_i$ and $\Delta[\hat{\mathbf{y}}_i, \mathbf{y}_i]$ computes the risk associated with $\hat{\mathbf{y}}_i$ in the form of a distance between the estimated translation $\hat{\mathbf{y}}_i$ and the gold translation $\mathbf{y}_i$ (e.g., the negative BLEU score). The exponent $\alpha$ controls the sharpness of the weightings of each possible translation and $Z_{i}$ is a normalizing factor that ensures that the exponentiated probabilities sum to one. Note that $\mathcal{S}[\mathbf{x}_i]$ is constructed to always contain the ground truth translation $\mathbf{y}_i$. The remaining candidate translations in this subset are generated by sampling from the model distribution.
This model is efficient, because it evaluates multiple trajectories at once and is a viable alternative to reinforcement learning for fine tuning after maximum likelihood pre-training (Shen et al. 2016).
Fine-tuning with scheduled sampling
Scheduled sampling tries to address the main problem with the maximum likelihood approach; the decoder is never exposed to its own outputs during the training procedure. The idea is simple: during training, the input to the decoder at time t+1 is the ground truth token $y_t$ with probability $\epsilon$ or the previously decoded token $\hat{y}_{t}$ with probability $1−\epsilon$. The probability $\epsilon$ is adjusted during training: it starts at 1 (where the model learns from ground truth) and progressively decays to 0 (where the model only learns from its own outputs). This is a fine-tuning technique which progressively blends in model predictions.
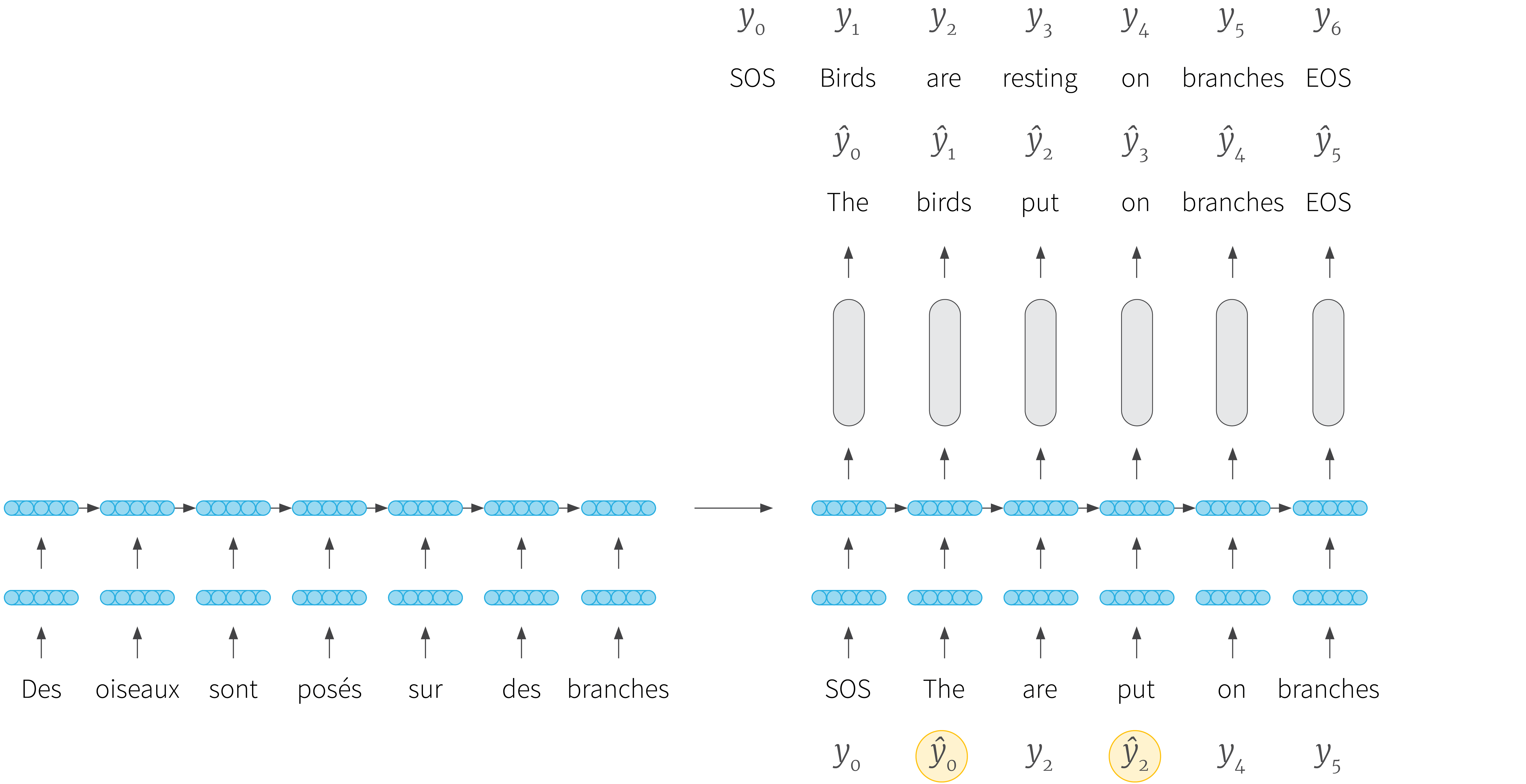
Figure 3. Scheduled sampling. In scheduled sampling the decoder is randomly presented with either the predicted token from the previous time step (in yellow circles) or the ground truth one. In this way the decoder is exposed to its own output, but can partially recover from mistakes. Here, the model would generate $SOS$ $The$ $birds$ $are$ $put$ $on$ $branches$ $EOS$ whereas the ground truth translation is $SOS$ $Birds$ $are$ $resting$ $on$ $branches$ $EOS$. Randomly mixing the two, the model sees the following inputs: $SOS$ $The$ $are$ $put$ $on$ $branches$. In contrast, a true oracle would have applied targeted corrections to the decoder’s mistakes, and so the model might have seen something like $SOS$ $The$ $birds$ $are$ $resting$ $on$ $branches$. Scheduled sampling does not really allow the model to recover from its mistakes but instead tries to force it to output the gold translation, no matter the prefix generated so far. Nonetheless, it is empirically successful.
This approach takes inspiration from the DAgger method in imitation learning (Ross et al., 2011) in which an agent learns from both its own actions and the actions of an oracle which acts expertly. However, unlike imitation learning, scheduled sampling does not rely on a live oracle but instead uses the dataset (Figure 3). Consequently, the corrections provided to the model might not make sense given the model’s errors: it optimizes an objective that does not guarantee good behaviour if trained until convergence (Huszár, 2015). Nonetheless, this method is empirically successful and outperforms RL on a paraphrase generation task (Du & Ji, 2019).
Sequence-level training from scratch
The preceding methods trained at the token level and then fine-tuned at the sequence level. The methods in this section combine searching and learning to directly train the model at the sequence level. In the next three sections, we consider beam search optimization, SeaRNN, and reward augmented maximum likelihood respectively.
Beam search optimization
Similarly to scheduled sampling, Beam Search Optimization also uses ground truth data as an oracle. However, unlike scheduled sampling, it tries to maintain semantic and syntactic correctness. It (i) uses a sequence-level cost function and (ii) maintains a beam of hypotheses during the learning procedure. At each point in time, the oracle ensures that the ground truth is among these hypotheses.
Figure 4. Beam search optimization. During training $K$ sequences are maintained. Most of the time, these include the ground truth sequence (brown rectangles). When the ground truth sequence falls off the beam, the beam is re-initialised from that ground truth prefix.
Let the score of a partial sequence at time $t$ be $\mbox{s}[w,\hat{\mathbf{y}}_{\leq t}, \mathbf{x}_i,\boldsymbol\phi]$, where $\boldsymbol\phi$ are the weights of the model, $w$ is a token in the vocabulary $\mathcal{V}$, $\hat{\mathbf{y}}_{<t}$ is the sequence decoded so far, and $\mathbf{x}_i$ is the input sentence to be translated. This score is the output of the decoder before passing through the softmax function. During decoding, the $K$ most highly scored sequences are retained. Let $\hat{\mathbf{y}}_{<t}^{(K)}$ be the $K$-th ranked sequence at time $t$, so that there are exactly $K-1$ sequences scored more highly than this. The loss function for a single sequence is as follows:
\begin{eqnarray} \mathcal{L}[\boldsymbol\phi] &=& \sum_{t=1}^{T-1} \Delta\left[\hat{\mathbf{y}}^{(K)}_{\leq t}\right] \left(1 – \mbox{s}\left[w,\hat{\mathbf{y}}_{\leq t}^{(K)}, \mathbf{x},\boldsymbol\phi\right] + \mbox{s}\left[w,\mathbf{y}_{\leq t}, \mathbf{x},\boldsymbol\phi\right]\right) \\ \nonumber &&\hspace{1cm}+ \Delta\left[\hat{\mathbf{y}}^{(1)}_{\leq T}\right] \left(1 – \mbox{s}\left[w,\hat{\mathbf{y}}_{\leq T}^{(1)}, \mathbf{x},\boldsymbol\phi\right] + \mbox{s}\left[w,\mathbf{y}_{\leq T}, \mathbf{x},\boldsymbol\phi\right]\right), \tag{6}\end{eqnarray}
where $\Delta[\bullet]$ is a cost that derives from inverse BLEU score of the partial sequence $\hat{\mathbf{y}}^{(K)}_{\leq t}.$ The first term in the loss function encourages the model to score the ground truth translation $\mathbf{y}_{\leq t}$ higher than the $K$-th ranked sequence with a margin. The second term encourages the ground truth translation to be the most highly scored sequence at the last time step of decoding $T$. The function $\Delta[\bullet]$ is defined so that it returns 0 when there is no margin violation and a positive quantity otherwise.
To train this model, we need to update the set $\mathcal{S}_{t}$ of the $K$ most highly scored sequences at each time step $t$ and make sure that the ground truth sequence is in this set. To do this, Wiseman and Rush (2016) propose the following mechanism:
\begin{equation} \mathcal{S}_t = \mbox{topK} \begin{cases} \mbox{succ}[\mathbf{y}_{<t}] & \text{if violation} \\ \bigcup\limits_{k=1}^K \mbox{succ}[\hat{\mathbf{y}}^{(k)}_{<t}] & \text{otherwise}, \end{cases} \tag{7}\end{equation}
where $\mbox{succ}[w]$ returns the set of all valid sequences that can be formed by appending a token to the sequence $w$. If the gold sequence is in the top-$K$ results then beam search continues as normal. If the gold sequence falls off the beam, this is a violation and the model now uses the ground truth as prefix for subsequent generation (figure 4).
In this way, beam search optimization trains the model to output sequences where the ground truth sequence is always the most highly scored one at the end of decoding and is among the top $K$ sequences during decoding. The mistake-specific scoring function $\Delta$ takes into account a sequence-level cost during training.
SeaRNN
SeaRNN (LeBlond et al. 2018) searches over all possible next tokens, taking into account the subsequent completion of the sequence. It generates the first part of the sequence using the roll-in policy, chooses the next token to evaluate and then completes the sentence with a roll-out policy. The cost of this full completed sentence can then be evaluated and the best token chosen (figure 5).
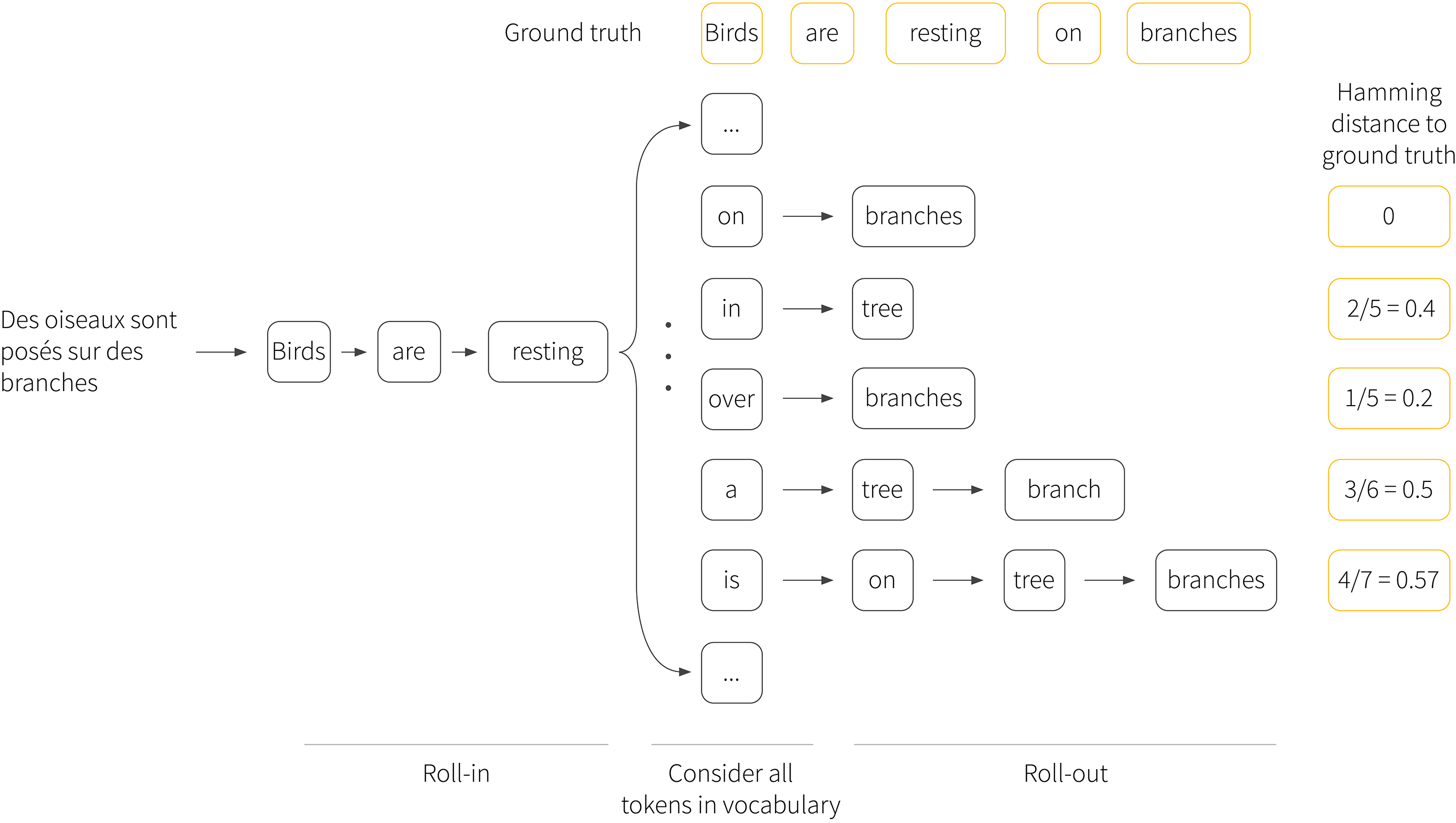
Figure 5. SeaRNN. For each partial sequence, SeaRNN tries every possible next word and completes the sentence for each. A cost is computed for each completion and in this way the word is chosen. This optimization over next words is done at each time step and embedded within the training optimization so the computational cost is very high.
In more detail, the roll-in policy is first applied to generate a sequence which is stored together with the corresponding hidden states. The algorithm then steps through this sequence. At step $t$, the roll-out policy takes the partial sequence $\hat{\mathbf{y}}_{<t}$ and a possible next token $w \in \mathcal{V}$, and completes the sentence $\hat{\mathbf{y}}_{>t}$. A cost $\mbox{c}[\{\hat{\mathbf{y}}_{<t},w,\hat{\mathbf{y}}_{>t}\},\mathbf{y}]$ is then computed based on the similarity of the current sequence $\{\hat{\mathbf{y}}_{<t},w,\hat{\mathbf{y}}_{>t}\}$, consisting of partial roll-in, word choice and roll-out, and the ground truth $\mathbf{y}$. In this way we can select the best choice of word $w^{*}$.
LeBlond {et al. (2018) propose to use the log-loss for training the system:
\begin{align} \mathcal{L}[\boldsymbol\phi] &= \sum_{t=1}^T -\log \left(\frac{\exp[s\left[w^{*}_{t},\hat{\mathbf{y}}_{<t}, \mathbf{x},\boldsymbol\phi\right]]} {\sum_{i \in \mathcal{V}} \exp\left[s\left[i,\hat{\mathbf{y}}_{<t}, \mathbf{x},\boldsymbol\phi\right]\right]} \right), \tag{8}
\end{align}
where $\mbox{s}\left[w^{*}_{t},\hat{\mathbf{y}}_{<t}, \mathbf{x},\boldsymbol\phi\right]$ is the pre-softmax score for the generated sequence $\hat{\mathbf{y}}_{\leq t} = \{\hat{\mathbf{y}}_{<t}, w^*_t\}$ given the input $\mathbf{x}$.
There are three possible types of roll-in and roll-out policy: we can use the model’s predictions, the ground truth tokens, or a mix of the model’s predictions and the ground truth tokens. Note that if the roll-in and roll-out policies are the ground truth predictions, then this loss reduces to negative log-likelihood since for each $t$, $w^*_t$ will be the ground truth token $y^t$. LeBlond et al. (2018) ran experiments for all 9 different combinations and they concluded that it was best to use the model’s predictions as roll-in strategy and a mix of the two policies for roll-out.
Although this approach allows us to train the model at the sequence level, the computational cost is too high for practical word-level generation: at each time step of decoding, SeaRNN has to generate sequences for every possible next token and so in practice it is only applied to a reduced vocabulary.
Reward augmented maximum likelihood
The preceding approaches have relied on the model’s own predictions to support sequence-level optimization. Instead, Reward Augmented Maximum Likelihood or RAML (Norouzi et al. 2016) aims to teach the model about the space of good solutions. To this end, the algorithm augments the ground truth dataset with sequences which are known to maximize a reward $r$. RAML uses sequence-level information not to train the model to learn from its own output, but to teach the model about the space of good solutions.
The algorithm exploits the fact that the global minimum of the REINFORCE loss function with reward $r$ and with entropy regularization is achieved when the policy $\boldsymbol\pi[\boldsymbol\phi]$ matches the exponential payoff distribution:
\begin{equation} q(\hat{\mathbf{y}}_i|\mathbf{y}_i,\tau) = \frac{1}{Z(\mathbf{y}_i,\tau)} \exp(r[\hat{\mathbf{y}}_i, \mathbf{y}_i]/\tau), \tag{9}\end{equation}
where $\tau$ is a temperature parameter, Z is a normalizing term, and $r[\hat{y}_i,y_i]$ is a sequence-level reward (e.g., the BLEU score).
It follows that if we sample values $\hat{\mathbf{y}}_i$ from $q(\hat{\mathbf{y}}_i|\mathbf{y}_i, \tau)$ we will maximize the regularized expected sum of rewards. Hence, we draw samples from $q$ and train the model to maximize the likelihood of these samples. The resulting training objective is:
\begin{equation} \mathcal{L}[\boldsymbol\phi] = \sum_{i=1}^{I} \left(-\sum_{\hat{\mathbf{y}}_i \in \mathcal{Y}} q(\hat{\mathbf{y}}_i|\mathbf{y}_i, \tau) \log[\boldsymbol\pi[\mathbf{y}_i|\mathbf{x}_i,\boldsymbol\phi]]\right), \tag{10}\end{equation}
where $\mathcal{Y}$ is the set of all possible translations. To minimize $\mathcal{L}$, one must minimize the negative log likelihood of samples weighted according to $q(\bullet|\mathbf{y}_i, \tau)$.
RAML thus serves as a data-augmentation method which not only presents ground truth samples to the model, but also samples that maximize the chosen reward function. Note that sampling from $q(\hat{\mathbf{y}}_i|\mathbf{y}_i, \tau)$ is not straightforward. See Norouzi et al. (2016) for more details.
Summary and discussion
In the first part of this tutorial, we considered training with maximum-likelihood and then presented different decoding algorithms. We discussed that one of the main problems with maximum likelihood training is exposure bias: during training the sequential decoderonly sees ground truth tokens whereas during testing it must generate new words based on its own previous outputs.
If the model samples one token from the tail of the distribution at some point during decoding, it enters a space that it has not observed during training so it does know not how to continue the generation and it ends up outputting a sequence of low-quality.2 Approaches to avoid this problem fall into four categories:
- During inference, force the model to stay in high-likelihood space to avoid errors that take the model to an unknown part of the output space (top-k sampling, nucleus sampling);
- During inference, force the model to stay in high-likelihood space as it learns from its own outputs (fine-tuning with RL, MRT or scheduled sampling);
- Make the model learn to recover from its own mistakes during training (BSO, SeaRNN);
- Teach the model about the space of good solutions according to a sequence-level reward (RAML).
We speculate that the most successful future approaches will probably combine learning to recover from mistakes during training and preventing the solution from straying away from the known output space during inference.
Future directions
To conclude the tutorial, we draw attention to several areas that we believe would benefit from further investigation.
Exploring the space of solutions: During inference, it is unclear how to constrain exploration. Beam search, top-k sampling, and nucleus sampling all rely on setting a threshold. However, instead of setting an arbitrary threshold, it might be interesting to try to quantify the model’s confidence. In particular, approaches inspired from the safe reinforcement learning literature might be useful (García et al. 2015).
Model distribution: Technically encoder-decoder NNLG models are trained to model the distribution $Pr(\bullet|\mathbf{y}_{<t})$ at each time step $t$. However, it is unclear whether they are really successful at learning this distribution and in particular, whether they do use all the history to predict the next token. Since this is a fundamental assumption of NNLG, work that explore when models learn the joint distribution and when they do not would be very enlightening.
Encoder-decoder relations: All the work that we have presented here has focused on what is happening in the decoder. The underlying assumption is that it is possible to decouple encoder and decoder representations when investigating decoding strategies. This assumption might not always hold and phenomena induced by the encoder representations might explain some of the behaviour observed during decoding (see El Asri & Trischler, 2019).
Metrics: One hindrance to progress in this field has been the lack of reliable automatic metrics (Liu et al. 2016) and the fact that the community does not seem to have gathered around a small common set of benchmarks. There is an important body of work on the topic of evaluation (Holtzman et al. 2018; Xu et al. 2019}) and some metrics to measure various aspects such as coherence and entailment have been proposed and might become more widely used.
Linguistic considerations: In this post, we have only focused on the NNLG problem from a machine learning point of view, without any linguistic considerations. We encourage the reader to look into other approaches such as Shen et al. (2019) (which received a best paper award at ICLR 2019!) which modifies the RNN architecture to take into account linguistic properties. Following the #BenderRule, we should also mention that the work we have described has only been applied to a few languages and that these approaches might not be universal.
Conclusion
In conclusion, on high-resource languages, the field of NNLG has known great empirical success and has made significant progress towards generating coherent text. We hope that this post has provided a useful overview for young researchers or anybody who is considering doing research in this area. This is a truly exciting area where, we believe, most of the building blocks to build coherent and robust models are already in place.
1Note that this is a common setting, but it is possible to use intermediate rewards, e.g., the BLEU scores on partial sequences.
2This phenomenon is known as the problem of cascading errors in the imitation learning literature (Bagnell 2015).
Work with Us!
Impressed by the work of the team? RBC Borealis is looking to hire for various roles across different teams. Visit our career page now and discover opportunities to join similar impactful projects!
Careers at RBC Borealis