
Predicting the future is a fundamental task in human activity understanding. The complexity of this task comes from the fact that the future is uncertain (not to mention that humans are notoriously bad at predicting it!)
Given a fixed history of events and their corresponding times – like those shown below in Fig. 1 – multiple actions are possible in the future. In our CVPR paper of the same name, which we will be presenting this week in Long Beach, we propose a powerful generative approach that can effectively model the distribution over future actions.
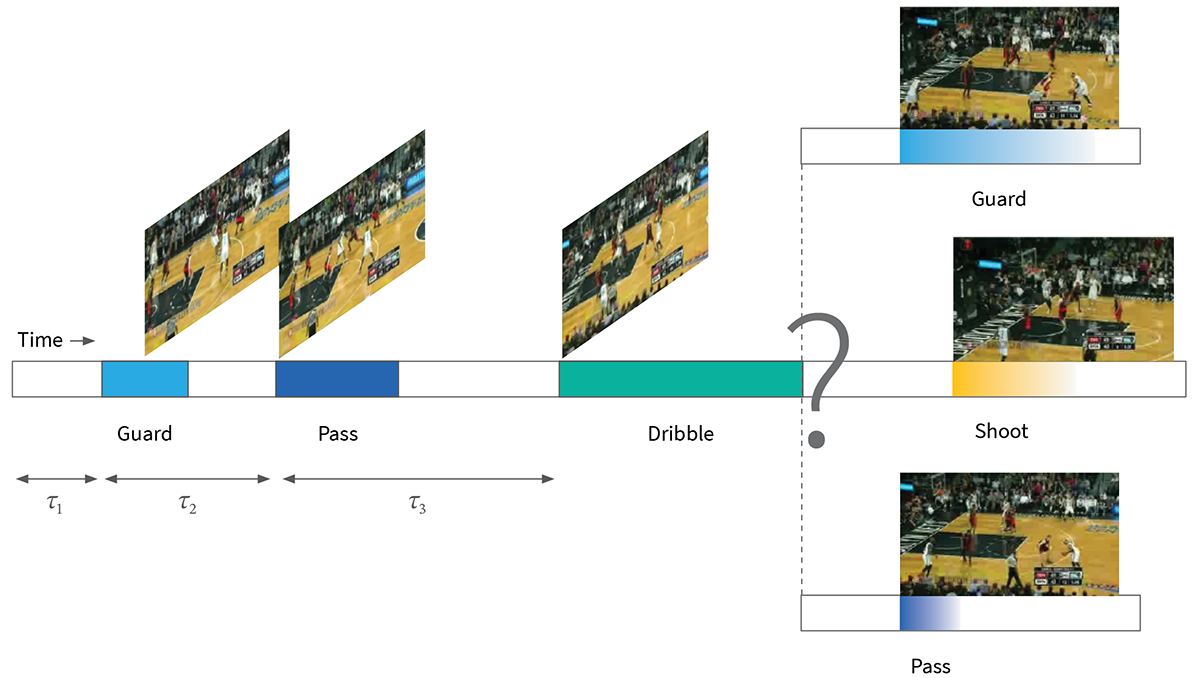
Figure 1: Given a history of past actions, multiple actions are possible in the future. For example, here we have a sequence of basketball events and their corresponding timing, but different types of actions might happen next.
To date, much of the work in this domain has focused on taking frame-level data of video as input in order to predict the actions or activities that may occur in the immediate future. Time-series data often involves regularly spaced data points with interesting events occurring sparsely across time. We hypothesize that in order to model future events in such a scenario, it is beneficial to consider the history of sparse events (action categories and their temporal occurrence in the above example) alone, instead of regularly spaced frame data. This approach also allows us to model high-level semantic meaning in the time-series data that can be difficult to discern from frame-level data.

Figure 2: Given the history of actions, APP-VAE generates a distribution over possible actions in the next step. APP-VAE can recurrently perform this operation to model diverse sequences of actions that may follow. The figure shows the distributions for the fourth action in a basketball game given the history of first three actions.
More specifically, we are interested in modeling the distribution over future action category and action timing given the past history of sparse events. For action timing, we aim to model the distribution over inter-arrival time. The inter-arrival time is the time difference between the starting time of two consecutive actions.
The contributions of this work center around the APP-VAE (Action Point Process VAE), a novel generative model for asynchronous time action sequences. Fig. 2 shows the overall structure of our proposed framework. We formulated our model with the variational auto-encoder (VAE) paradigm, a powerful class of probabilistic models that facilitate generation and the ability to model complex distributions. We present a novel form of VAE for action sequences under a point process approach. This approach has a number of advantages, including a probabilistic treatment of action sequences to allow for likelihood evaluation, generation, and anomaly detection.
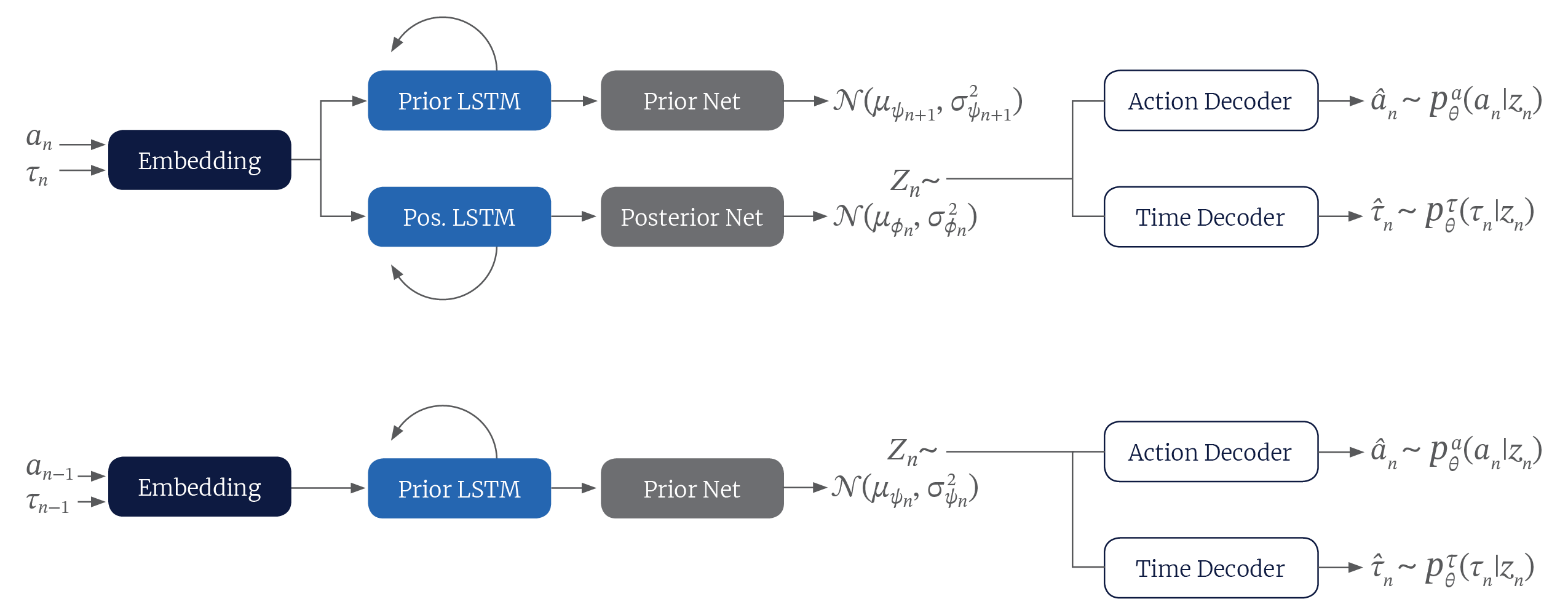
Figure 3: Our proposed recurrent VAE model for asynchronous action sequence modeling. At each time step, the model uses the history of actions and inter-arrival times to generate a distribution over latent codes, a sample of which is then decoded into two probability distributions for the next action: one over possible action labels and one over the inter arrival time.
Fig. 3 shows the architecture of our model. Overall, the input sequence of action categories and inter-arrival times are encoded using a recurrent VAE model. At each step, the model uses the history of actions to produce a distribution over latent codes $zn$, a sample of which is then decoded into two probability distributions: one over the possible action categories and another over the inter-arrival time for the next action.
Since the true distribution over latent variables $z_n$ is intractable, we rely on a time-dependent posterior network $q_\phi(z_{n}|x_{1:n})$ that approximates it with a conditional Gaussian distribution $N(\mu_{\phi_n}, \sigma^2_{\phi_n})$.
To prevent $z_n$ from just copying $x_n$, we force $q_\phi(z_n|x_{1:n})$ to be close to the prior distribution $p(z_n)$ using a KL-divergence term. Here, in order to consider the history of past actions in generation phase, we learn a prior that varies across time and is a function of past actions, except the current action $p_\psi(z_n|x_{1:n-1})$.
The sequence model generates two probability distributions: i) a categorical distribution over the action categories; and ii) a temporal point process distribution over the inter-arrival times for the next action.
The distribution over action categories $a_n$ is modeled with a multinomial distribution when $a_n$ can only take a finite number of values: \begin{equation}p^a_\theta(a_n=k|z_n) = p_k(z_n) \quad \text{and} \,\,\,\,
\sum_{k=1}^K{p_k(z_n)} =1 \label{eq:action}
\end{equation} where $p_k(z_n)$ is the probability of occurrence of action $k$, and $K$ is the total number of action categories.
The inter-arrival time $\tau_n$ is assumed to follow an exponential distribution parameterized by $\lambda(z_n)$, similar to a standard temporal point process model:
\begin{equation}\begin{aligned}p^{\tau}_{\theta}(\tau_n | z_n) =\begin{cases} \lambda(z_n) e^{-{\lambda(z_n)}\tau_n} & \text{if}~~ \tau_n \geq 0 \\0 & \text{if}~~ \tau_n<0\end{cases}\end{aligned} \label{eq:time}\end{equation}
where $p^{\tau}_{\theta}(\tau_n|z_n)$ is a probability density function over random variable $\tau_n$ and $\lambda(z_n)$ is the intensity of the process, which depends on the latent variable sample $z_n$. We train the model by optimizing the variational lower bound over the entire sequence comprised of $N$ steps:
\begin{align}\mathcal{L}_{\theta,\phi}(x_{1:N}) = \sum_{n=1}^N(&{\mathop{\mathbb{E}}}_{q_\phi(z_{n}|x_{1:n})}[\log p_\theta{(x_n|z_{n})}] \\
&- D_{KL}(q_\phi(z_n|x_{1:n})||p_\psi(z_n|x_{1:n-1})))
\nonumber
\label{eq:loss}
\end{align}
We empirically validate the efficacy of APP-VAE for modeling action sequences on the MultiTHUMOS and Breakfast datasets. Experiments show that our model is effective in capturing the uncertainty inherent in tasks such as action prediction and anomaly detection.

Figure 4: Examples of generated sequences. Given the history (shown at left), we generate a
distribution over latent code zn for the subsequent time step. A sample is drawn from this distribution, and decoded into distributions over action category and time, from which a next action/time pair by selecting the action with the highest probability and computing the expectation of the generated distribution overτ. This process is repeated to generate a sequence of actions. Two such sampled sequences (a) and (b) are shown for each history, and compared to the respective ground truth sequence (in line with history row). We can see that APP-VAE is capable of generating diverse and plausible action sequences.
Fig. 4 shows examples of diverse future action sequences that are generated by APP-VAE given the history. For different provided histories, sampled sequences of actions are shown. We note that the overall duration and sequence of actions on the Breakfast Dataset are reasonable. Variations, e.g. taking the juice squeezer before using it, adding salt and pepper before cooking eggs, are plausible alternatives generated by our model.
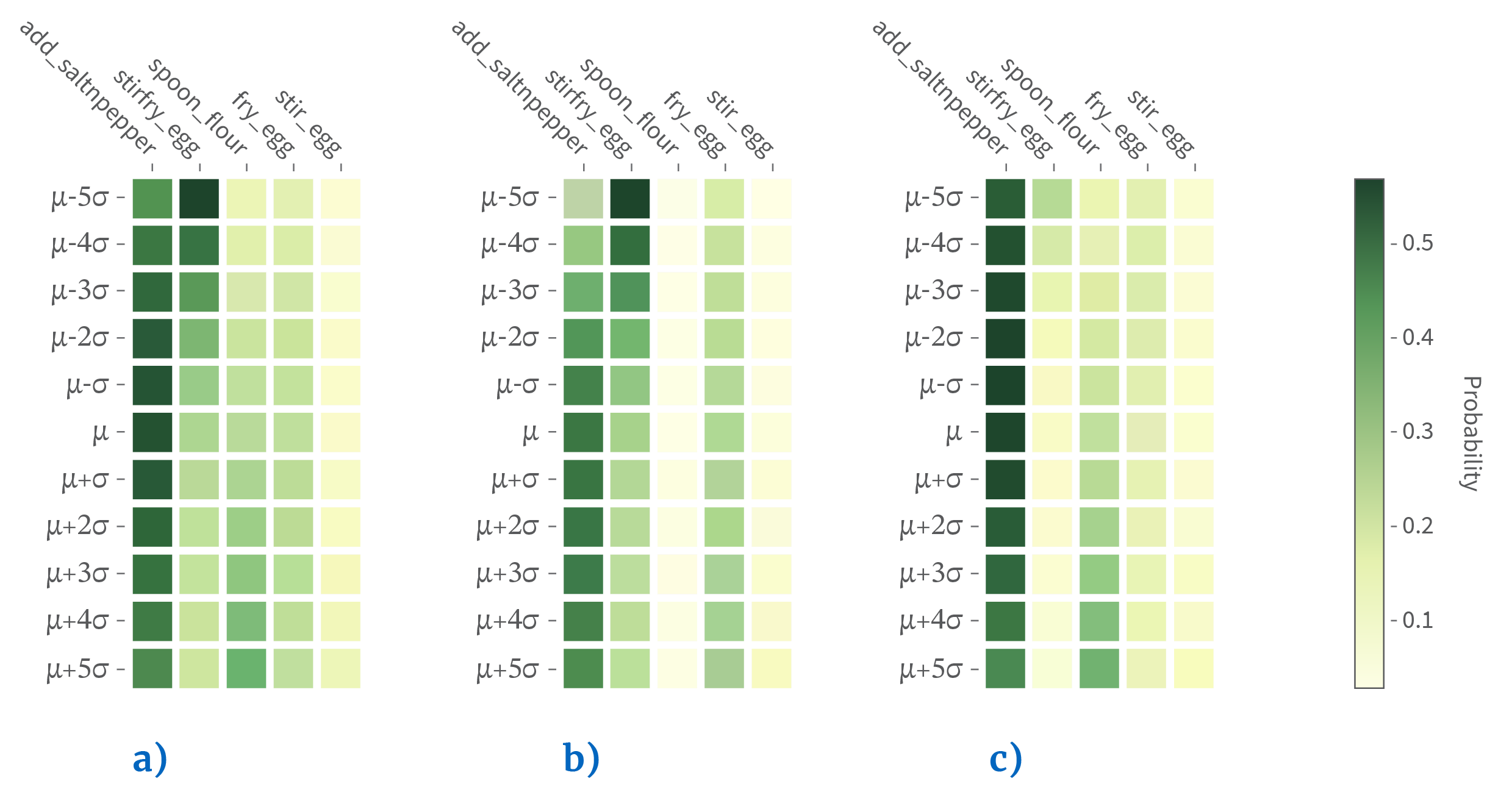
Figure 5: Latent Code Manipulation. The history + ground-truth label of future action for the sub-figures are: (a) “SIL, crack egg”→“add saltnpepper”, (b) “SIL, take plate, crack egg”→ “add saltnpepper” and (c) “SIL, pour oil, crack egg”→“add saltnpepper”.
Fig. 5 visualizes a traversal on one of the latent codes for three different sequences by uniformly sampling one z dimension over µ − 5σ, µ + 5σ while fixing others to their sampled values. As shown, this dimension correlates closely with the action add saltnpepper, strifry egg and fry egg.
We further qualitatively examine the ability of the model to score the likelihood of individual test samples. We sort the test action sequences according to the average per time-step likelihood estimated by drawing samples from the approximate posterior distribution following the importance sampling approach. High scoring sequences should be those that our model deems as “normal” while low scoring sequences those that are unusual. Tab. 1 shows some example of sequences with low and high likelihood on the MultiTHUMOS dataset. We note that a regular, structured sequence of actions such as jump, body roll, cliff diving for a diving action or body contract, squat, clean and jerk for a weightlifting action receives high likelihood. However, repeated hammer throws or golf swings with no set up actions receives a low likelihood.
Table 1 (below): Example of test sequences with high and low likelihood according to our learned model:
Test sequences with high likelihood |
|---|
| 1 NoHuman, CliffDiving, Diving, Jump, BodyRoll, CliffDiving, Diving, Jump, BodyRoll, CliffDiving, Diving, Jump, BodyRoll, BodyContract, Run, CliffDiving, Diving, Jump, …, BodyRoll, CliffDiving, Diving, BodyContract, CliffDiving, Diving, CliffDiving, Diving, CliffDiving, Diving, Jump, CliffDiving, Diving, Walk, Run, Jump, Jump, Run, Jump |
| 2 CleanAndJerk, PickUp, BodyContract, Squat, StandUp, BodyContract, Squat, CleanAndJerk, PickUp, StandUp, BodyContract, Squat, CleanAndJerk, PickUp, StandUp, Drop, BodyContract, Squat, PickUp, …, Squat, StandUp, Drop, BodyContract, Squat, BodyContract, Squat, BodyContract, Squat, BodyContract, Squat, BodyContract, Squat, NoHuman |
| Test sequences with low likelihood |
|---|
| 1 NoHuman, TalkToCamera, GolfSwing, GolfSwing, GolfSwing, GolfSwing, NoHuman |
| 2 NoHuman, HammerThrow, TalkToCamera, CloseUpTalkToCamera, HammerThrow, HammerThrow, HammerThrow, TalkToCamera, …, HammerThrow, HammerThrow, HammerThrow, HammerThrow, HammerThrow, HammerThrow, HammerThrow, HammerThrow, HammerThrow, HammerThrow, HammerThrow, HammerThrow, HammerThrow |
We presented a novel probabilistic model for point process data – a variational auto-encoder that captures uncertainty in action times and category labels. As a generative model, it can produce action sequences by sampling from a prior distribution, the parameters of which are updated based on neural networks that control the distributions over the next action type and its temporal occurrence. Our model can be used to analyze and model asynchronous data in a wide variety of ranges like social networks, earthquakes events, health informatics, and the list goes on.