
Many companies race to use machine learning capabilities, eager to build on cutting-edge research and tackle a wide variety of business applications. As interest in the field grows, more product teams and business managers anchored in traditional product development methodologies find themselves in a new, unfamiliar territory: building machine learning products. With this series on the machine learning product development lifecycle, we aim to share what it takes to deliver business value from machine learning.
How machine learning systems differ from the traditional software
The Agile Manifesto published in 2001 has changed the way most software products are developed today: in iterative, focused short loops and sprints. However, applying agile to machine learning systems is far from straightforward. Traditional software implements a known set of computations to come up with an output — developers have a specific output in mind, making product development relatively straightforward. Experienced developers get good at estimating how long it will take to build a component or feature.
As Andrei Karpathy explained in his Software 2.0 post in 2017, machine learning is a different kind of programming that provides much more flexibility around the kinds of problems we can automate using computer systems, as developers provide “rough skeletons” of code and use data to fill in the details. The challenge is, this same flexibility is accompanied by uncertainty in the development process. Machine learning systems are inductive; they learn a suitable program (called a model) based on prior examples of inputs and outputs (called training data), and then apply what they’ve learned to make inferences on new data in production. Scientists choose the model architectures carefully, but getting it right can take time—even an experienced machine learning scientist doesn’t know if they’ll find a solution, let alone how long it will take to find one.
The key difference between building traditional software and machine learning systems is accounting for that uncertainty.
Managing uncertainty across the machine learning product development lifecycle
With machine learning, uncertainty is rife across the product development lifecycle – right down to the level of individual algorithms. For example, you can reach a certain level of performance and find that you need to make changes, which would require weeks of code refactoring, and then more time just to return to the same level of baseline performance. And that’s assuming that an entirely different approach isn’t required. Particularly in the early stages of a project, it’s simply unclear what might work.
Uncertainty can also surface in the problem statement and data set. For example, building a recommendation engine for TikTok (which carries live, user-generated content) would be substantially different from building a recommendation engine for Netflix (where content set is tightly controlled). They are both recommendation engines, but their problem statements and data sets are very different.
Uncertainty could also mean that your mathematical model may not generalize well to an unseen data set. Predicting the accuracy of a machine learning model is difficult. Even seemingly good machine learning models can sometimes make errors, necessitating further tweaks to balance the levels of bias and variance, or precision and recall.
In order to manage uncertainty during the product development lifecycle, machine learning projects need to be highly iterative from the beginning.
At RBC Borealis, we simultaneously work on each phase of our lifecycle in parallel, carefully iterating on each section until we reach a satisfactory level before circling back, then forward to ensure we find a fit between problem and solution.
Given the complexity, it is imperative for product managers new to machine learning context to develop a nuanced, operational understanding of machine learning systems, capabilities and limitations — and invest the time upfront to tie the effort more tightly to real business problems.
Six main stages in the machine learning product lifecycle
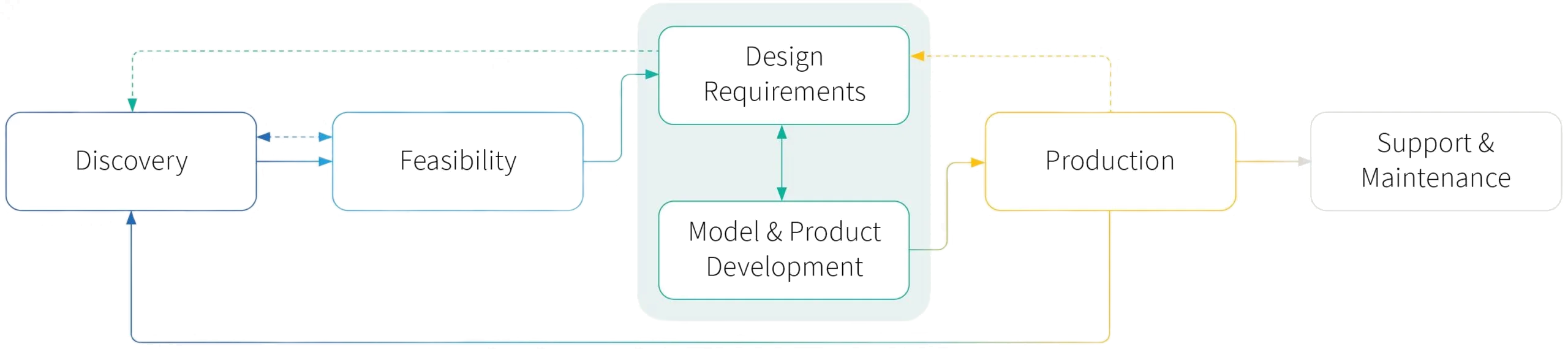
As the product management discipline evolves, we aim to provide a framework for approaching machine learning projects that can be referenced by practitioners or teams that are building machine learning systems, covering the six main stages: Discovery, Feasibility, Design and Requirements, Model and Product Development, Production, Support and Maintenance.
We have also dedicated a separate section to the topic of managing data throughout the ML product lifecycle.

Discovery
The development of a machine learning product should always start with discovery. It’s tempting to skip this step — agile has made it too easy to build first and think (and test) later—but in an ML context this step is critical, and will help product teams tackle and tame uncertainty early in the product lifecycle. Discovery begins by defining the problem space, understanding and framing the business problem, the desired outcome and mapping them to a solution space. This is not always an easy task: technical teams are looking for a quantitative baseline to measure feasibility against while the business is struggling to achieve clarity; the business is looking for clear cost-benefit analysis at a time when the outcomes are unclear. Balancing stakeholder needs, business problem framing, defining goals and outcomes, and building relationships with the business will be key. Here’s our take on a new age of discovery: Balancing short-term value with long-term innovation, or how to successfully navigate the discovery stage.

Feasibility
The feasibility stage is used to determine if the machine learning system can achieve the outcomes initially proposed. An initial Minimum Viable Product (MVP) solution may be created at this stage to identify immediate limitations which, in turn, helps refine and reframe the problem statement. Given adaptive nature of machine learning systems, a feasibility study will help product teams understand how the system might have to change, adapt and interact with users when in production, develop a baseline for the problem and a more informed perspective on business ROI. Read more about conducting your Feasibility study for ML projects.

Design Requirements
The design of machine learning requirements takes a careful combination of design and business goals. PMs need to understand the end user to drive value. By focusing on the end-user and developing a deep understanding of a specific problem your product can solve. Otherwise, you run the risk of developing an extremely powerful system only to address a small (or possibly non-existent) problem. In the design & requirements section, we explore the fundamental differences of user experience with machine learning systems, and what goes into developing a dynamic interface that adapts to a user’s needs given the uncertainty when it comes to predictions.

Model and Product Development
It’s time to take the blueprints and a clear set of goals and targets developed through the discovery, feasibility and design stages and start the build. This will be a collaborative endeavour with design, engineering, ML researchers, business and PMs working together, and PMs can drive a lot of value by continuing deliberate stakeholder management. The build will go from simple to complex – PMs should prepare to drive the product through train, test, and validate cycles; manage standups with scientists who may or may not be making progress; and navigate the iterative dependence between design, science and engineering teams. For a deeper dive into this stage, please read How to navigate the model and product development phase of your machine learning project.

Production
The production stage is where the ML system is introduced to the infrastructure where it will function (and hopefully thrive). In the upcoming blog post on this topic, we will discuss the challenges around production environments in large enterprise environments – from business and legal, to technological issues like MLOps. Read our overview of what PMs can do here to set projects up for success: The (never-ending) production stage.

Support & Maintenance
ML projects are not complete upon shipping your first draft. In fact, shipping your MVP is an important first step towards a larger iteration. Developing and deploying ML systems can be relatively fast and affordable, but maintaining them over time can be more difficult and expensive than commonly assumed. Machine learning systems are tightly coupled — a change in one component, changes to the feature space, hyper parameters, or learning rate, for example, can affect model performance in unexpected ways. In the upcoming blog post, we will walk PM teams through what to expect at this stage and how to plan and prepare for it.
News
How to navigate the model and product development phase of your machine learning project
News
Managing data throughout the machine learning product lifecycle
News
A new age of discovery: Balancing short-term value with long-term innovation
We're Hiring!
RBC Borealis offers a stimulating work environment and the platform to do world-class machine learning in a startup culture. We're growing the team, hiring for roles such as Product Manager, Business Development Lead, Research Engineer - Data Systems and more.
View all jobs