
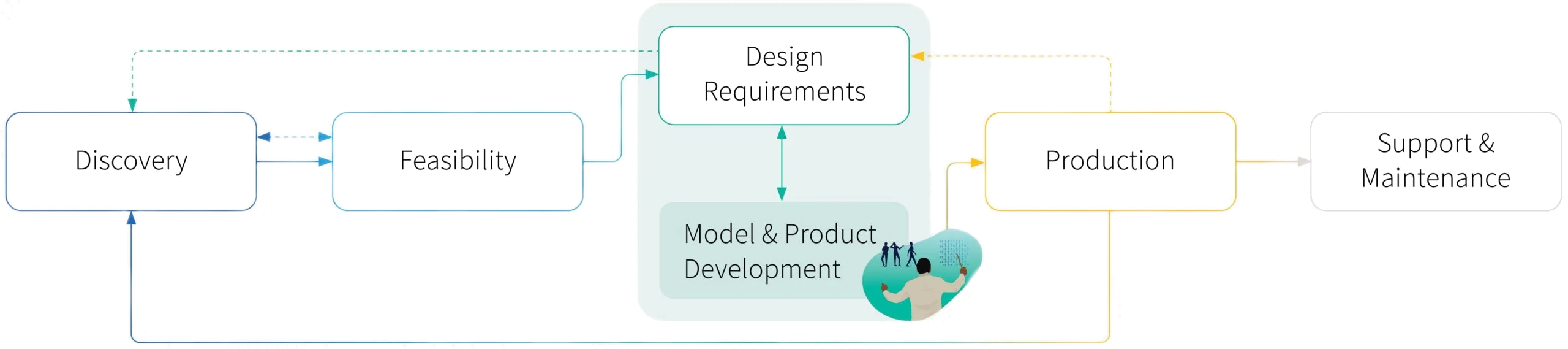
This is part 6 in our Field Guide to Machine Learning Product Development: What Product Managers Need to Know series. Read the Introduction, learn about how to manage data throughout the machine learning product lifecycle, read up on the Discovery phase and Feasibility phase; Design and Requirments phase; and the Model and Development phase below.
Imagine dropping in on two different team standup meetings. At the first standup, the team is building an email feature served with an API. The developers are familiar with scrums or Kanban, and are comfortable breaking their work down into one or two-day chunks. You hear things like “I implemented an API that will talk to the email system. We’re all set, and it’s in testing.”
At the second standup, the team is building a machine learning model to predict future stock market returns. The machine learning scientists are chunking their experiment cadence into short sprints. But these team members are more likely to say things like “I’m still training the model, and something is not working. I’m going to look into the initialization parameters and maybe try to optimize that. I’ll report back next time and then repeat.”
In both examples, standups give the team a space to share progress against the tasks in the workplan. But in the machine learning standup, uncertainty often creeps into the discussion, as teams share ideas on different experiments that could lead to a new outcome. Yet – outside of the standup routine – stakeholders expect progress updates.
The big challenge facing product managers (PMs) in the model development phase of the machine learning product lifecycle is simply to keep things moving in the face of uncertainty.
Progress might require careful management of three main stakeholder groups: the development teams; the executives you are problem-solving with; and the designers and engineers with interdependencies on final model performance.
In this post, we’ll explore the model development phase from the viewpoints of these three stakeholder groups, identifying lessons we have learned from our work at RBC Borealis.
Build on benchmarks
Armed with a clear set of baseline performance metrics for the task (that you hopefully developed during the feasibility study phase as suggested in this article), machine learning teams can come together around a unified objective and sense of progress. The benchmark essentially provides direction to the team as they explore candidate model architecture that can improve performance above that baseline.
For many, the challenge then becomes breaking down the tasks in order to structure progress against your goal. During the build phase, machine learning teams tend to follow an iterative process that moves through training, validating and testing their models in order to confirm that the statistical properties they learn during the training phase will generalize well to new data sets during the testing phase.
Yet that does not mean that progress cannot be measured. Many teams share their research results and improvements on model evaluation using scoring systems like AUC or ROC, or through precision and recall. However, finding the right balance between ambiguity and specificity is often challenging: goals like “improve 5% this week” can be difficult to achieve with machine learning sprints. It’s not uncommon to go weeks without making progress and then suddenly have a breakthrough that leaps past the benchmark. Yet setting a goal of simply “reporting back progress” can be too loose to drive the team towards a productive outcome.
It is also worth considering the relationship between technical value and business value. An improvement in model performance does not always linearly translate into improvements in business outcomes. For example, if you are building something where additional precision leads to monetary gains (like a model that predicts stock market performance), extra model performance is valuable to the business. For a product recommendation engine, on the other hand, you can quickly reach a point of diminishing returns. In these cases, it may be more worthwhile getting your model out and learning in production than it would be to keep working on finding an architecture that would only deliver incremental performance improvements. As a PM, it is your role to spot when there is a mismatch in value.
This is also the right time to be thinking about the ethical and governance considerations of your model in production. Remember that any requirements for explainability around fair treatment of individuals or groups should be established up front in the design stage (or earlier) as they may act as constraints on the algorithmic design.
Models can change even after they go into production. Sometimes the model can pick up inductive biases from its training set that result in different (and sometimes undesired) behaviors when the data distribution changes slightly in production, — a phenomenon a recent paper calls underspecification. So while the team may be excited when a model performs well on a hold-out test set (as they should be), it might be a good idea to remain skeptical.
To manage this risk, PMs may want to work though various hypothetical scenarios with distribution shifts in order to get ahead of future challenges, while the design team keeps experimenting. Ultimately, the best approach might be to work through these tests in simulated scenarios and be prepared to monitor performance, retrain and adapt the model as needed, once it goes into production.

How to communicate non-linear progress to the business leaders
Executives and business leaders want to see high-level overviews of what will be delivered, when it will be delivered, and what benefits or cost savings the model will create. And as PM, it’s on you to communicate progress to these stakeholders, typically more used to clear, linear development timelines — and educate them on the uncertain and non-linear nature of machine learning projects.
As PM, you may find yourself saying things like “We hope to deliver this in six months, but it’s possible our timelines will push out as far as 12 months. If we don’t see evidence of progress by then, we’ll cut the project. As far as value created, that will depend on where we land with model performance and we won’t know that until it’s in production.” Likely not the definite, linear answers that most executives are looking for.
There are a few ways to help manage this uncertainty and ‘bring executives along’ on the development journey. One is through transparent and consistent communication.
Don’t be afraid of frequent touchpoints with executives; it’s better to have them travel with you than it is to surprise them with bad news after going silent for six months.
When communicating with the business side, get ready to translate early and often; phrase progress in terms of business outcomes rather than technical benchmarks or milestones. For instance, instead of discussing a precision measure for a classification task, frame the discussion as an effort to articulate the impact of a low false positive rate on outcomes. Help your business partners envision what the future business value might look like.
Another way to manage uncertainty is to hedge risk by working on a couple of candidate projects at once – treating development more like a venture capitalist investing into multiple startups, knowing that not every startup or project will be a success. It’s an approach that is common within machine learning organisations and it’s often embedded in the DNA of their project managers. To ensure projects don’t turn into sunk costs, be sure to incorporate touchpoints with go/no-go decision points across the product lifecycle.
Get a sense of what error rates the business is comfortable accepting for a task. Then reverse engineer that understanding into a minimum viable product to kickstart the fly wheel learning effect and improve the algorithm’s performance over time.

Iterate with design and engineering
As in any project, there are clear interdependencies between model performance and the product features that can be designed and developed to work with the model. In a traditional software development process, design will spec out the requirements for a product or feature, creating the blueprint for development teams. In a machine learning project, development can often be more nuanced. As the team works its way towards a candidate solution using the spec, they may find out they need to change the criteria in some way, which could have implications on downstream design.
When building a cash flow forecasting model, for example, you may have design spec a feature that encompasses all types of business payments only to decide that, in the interest of time and pace to market, the first version of the model will only work on one type of payment. This shift in model scope requires design to redo the specs, creating downstream implications for supporting engineering development teams.
So why not just have design and engineering wait until after the machine learning team has found a candidate model for production? The answer is ‘time lost’.
The reality is that eventual product deployment can be greatly accelerated by having engineering work on front-end features and back-end data pipelines in parallel with machine learning experimentation. But that will require engineering teams with the right attitude and culture, keen skills for identifying ‘no regret’ development work, a level of comfort discarding code that isn’t valuable, and a sense of excitement around the challenge of iterating back and forth with peers in design and machine learning. PMs can help and take ownership of managing all the moving parts, iterating with teams throughout the process can often foster this type of culture – showing empathy when needed, and constantly communicating with stakeholders to ensure everyone is on the same page as the specs for the production solution evolve.

Navigating uncertainty like a pro
Navigating the uncertainties of the machine learning model development phase takes a PM skill set that goes beyond fluency with scrum practices, clarity of vision, and clear communication. It requires techniques for creating a sense of team unity and momentum (even when it’s unclear when and how things will work).
While it can feel daunting in the moment, the payoffs of doing this well are huge. As long as communication is tight and the team is grounded in trust, you’ll start to see different functions rely upon one another more deeply as they coalesce around a candidate model and product design that can go to production.
We’ll dive into what that looks like in our next post!
We're Hiring!
We are scientists, engineers and product experts dedicated to forging new frontiers of AI in finance, backed by RBC. The team is growing! Please view the open roles, including Product Manager, Business Development Lead, Research Engineer – Data Systems, and more.
View all jobsNews
Managing data throughout the machine learning product lifecycle
News
How to conduct a Feasibility study for your Machine Learning projects
News